Category: Technology
WordPress on AWS Graviton: Deploy & Migrate in Minutes
Running WordPress on ARM-based Graviton instances delivers up to 40% better price-performance compared to x86 equivalents. This guide provides production-ready scripts to deploy an optimised WordPress stack in minutes, plus everything you need to migrate your existing site. Why Graviton for WordPress? Graviton3 processors deliver: The t4g.small instance (2 vCPU, 2GB RAM) at ~$12/month handles […]
Read more →
AI vs Salesforce: The True Cost of Enterprise CRM in 2025
When a $3 API call can replace a $165 per user per month platform, the financial mathematics of enterprise software fundamentally change. 1. The New Economics of Customer Engagement Something fundamental shifted in 2024. The capabilities that once justified six and seven figure enterprise software contracts became commoditised overnight. Not gradually, through slow competitive erosion, […]
Read more →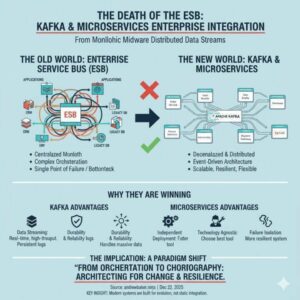
ESB vs Kafka: Why Microservices Are Replacing Enterprise Buses
1. Introduction The Enterprise Service Bus (ESB) once promised to be the silver bullet for enterprise integration. Organizations invested millions in platforms like MuleSoft, IBM Integration Bus, Oracle Service Bus, and TIBCO BusinessWorks, believing they would solve all their integration challenges. Today, these same organizations are discovering that their ESB has become their biggest architectural […]
Read more →Model Context Protocol: Enterprise Implementation Guide
The Model Context Protocol (MCP) represents a fundamental shift in how we integrate Large Language Models (LLMs) with external data sources and tools. As enterprises increasingly adopt AI powered applications, understanding MCP’s architecture, operational characteristics, and practical implementation becomes critical for technical leaders building production systems. 1. What is Model Context Protocol? Model Context Protocol […]
Read more →HTTP/2 Rapid Reset CVE-2023-44487: Test Your Server on macOS
Introduction In August 2023, a critical zero day vulnerability in the HTTP/2 protocol was disclosed that affected virtually every HTTP/2 capable web server and proxy. Known as HTTP/2 Rapid Reset (CVE 2023 44487), this vulnerability enabled attackers to launch devastating Distributed Denial of Service (DDoS) attacks with minimal resources. Google reported mitigating the largest DDoS […]
Read more →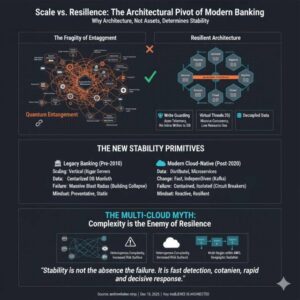
Why Bank Architecture Determines Resilience More Than Size
1. Size Was Once Mistaken for Stability For most of modern banking history, stability was assumed to increase with size. The thinking was the bigger you are, the more you should care, the more resources you can apply to problems. Larger banks had more capital, more infrastructure, and more people. In a pre-cloud world, this […]
Read more →Browser Curl with Playwright: Load Testing Guide
Modern sites often block plain curl. Using a real browser engine (Chromium via Playwright) gives you true browser behavior: real TLS/HTTP2 stack, cookies, redirects, and JavaScript execution if needed. This post mirrors the functionality of the original browser_curl.sh wrapper but implemented with Playwright. It also includes an optional Selenium mini-variant at the end. What this […]
Read more →How to Delete the Icon Cache in Windows (Fix Glitches)
I remember getting weird flashing on my laptop and eventually figured out my icon cache was full. So if you ever get this, try running the script below. This is obviously quite a weird/random post – hope its helpful 🙂
Read more →Why Least Privilege Security Is a Lie: 3 Root Causes
In technology, there is a tendency to solve a problem badly by using gross simplification, then come up with a catchy one liner and then broadcast this as doctrine or a principle. Nothing ticks more boxes in this regard, than the principle of least privileges. The ensuing enterprise scale deadlocks created by a crippling implementation […]
Read more →Public Cloud Migration: Why Lift-and-Shift Strategies Fail
The cloud is hot…. not just a little hot, but smokin hot!! Covid is messing with the economy, customers are battling financially, the macro economic outlook is problematic, vendor costs are high and climbing and security needs more investment every year. What on earth do we do??!! I know…. lets start a crusade – lets […]
Read more →