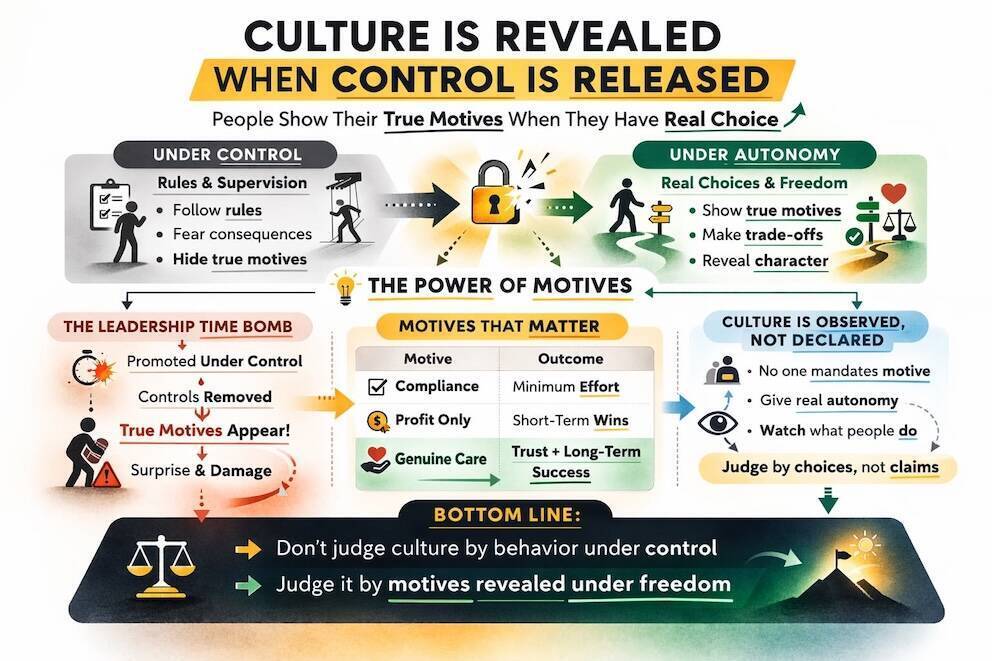
Culture is not revealed by behaviour under control, but by motive under autonomy.
Highly controlled environments mask intent and allow organisations to promote leaders whose inner compass has never been tested. When controls are later removed at seniority, behaviour shocks leadership and risk materialises.
Durable outcomes, whether in fraud prevention, customer trust, or leadership quality, only occur when actions are driven by genuine care rather than compliance, optics, or profit alone. Boards should insist not only on strong controls, but on leadership systems that deliberately create space to observe motive early, before authority becomes irreversible and consequences become systemic.
Most leadership systems obsess over what people do. What was delivered. What was measured. What was complied with. What was audited. These things are visible, countable, and comforting. They fit neatly into dashboards, scorecards, and board packs. But culture does not live there.
Culture lives in why people do things. And why is internal, invisible, and deeply problematic to measure when behaviours are constrained. You can of course mandate behaviour, but you cannot mandate motive. Yet motive is the thing that determines what happens when nobody is watching, when tradeoffs get hard, and when doing the right thing becomes expensive, slow, or personally costly.
This is where most organisations fool themselves. They mistake control for character, compliance for conviction, and execution under instruction for leadership potential. As long as the system is tight, everyone looks aligned. But alignment under constraint tells you almost nothing about who someone really is.
If you want to understand your culture, and the leaders your organisation is actually producing, you have to look past what people do and start paying attention to whythey do it.
1. Control Masks Motive
Highly controlled environments create a dangerous illusion. When everything is prescribed, what to do, how to do it, when to do it, who approves it, motive becomes irrelevant. People comply not because they believe, but because they are told.
In these environments, obedience looks like alignment, silence looks like agreement, and compliance looks like character. But this is a mirage. You are not observing who someone is. You are observing who someone is when constrained.
2. Autonomy Is the X Ray for the Soul
Motives only become visible when control is reduced. When there is less instruction, fewer approvals, real discretion, and real tradeoffs, people start to reveal their internal compass. Some step up, protect others, and take responsibility without being asked. Others optimise for personal safety, defer hard decisions, hide behind process, shift blame, or exploit ambiguity.
This is not a failure of governance. This is the test. If you do not allow upcoming leaders space, you never get to see their heart condition or their true motivation for doing things.
3. The Leadership Time Bomb
There is a common pattern that quietly destroys organisations. Juniors operate under heavy control. Motives are never observed. Promotions happen based on execution under constraint. Then, at seniority, controls are removed and behaviour suddenly changes. Leadership is shocked.
By that point, authority has already been granted, political capital has already been accumulated, and reversing the decision is expensive and destabilising. The problem was not that the leader changed. The problem is that you never saw them clearly before.
4. Motives Decide Whether You Will Do the Hard Thing
Consider fraud as a concrete example. Why are you investing in fraud controls? Is it because regulators compelled you? Because the media embarrassed you? Because you fear financial losses? Because auditors raised findings? Or is it because you genuinely love your clients and want to protect them?
These motivations are not equivalent. They produce radically different outcomes.
5. Love Is the Only Motivation Strong Enough
If being good at fraud requires rewriting your app, rebuilding your call centre stack, rearchitecting identity flows, retraining staff, and accepting real short term friction and cost, you will not do it for compliance, optics, or risk registers. It is simply too much effort.
Only love sustains that level of commitment.
Think about children. Even without love, you would still make sure they were fed, clothed, educated, and statistically unlikely to perish. Civilization has standards. But without love, you would almost certainly look for distance. You would outsource the problem to a boarding school, a relative, or an institution with timetables and rules, because children are exhausting, irrational, and profoundly inefficient unless you love them.
Love is what makes the sleepless nights tolerable, the mess forgivable, and the long view worth taking. Children raised without love may survive perfectly well in the short term, but they tend to return later as far more expensive problems. Organisations behave the same way. Without genuine care, leaders will meet minimum obligations, optimise for containment, and outsource discomfort. And just like neglected children, cultures raised without love do not disappear. They grow up.
6. Money as a Motive: How Clients Instantly Know
Now consider a more everyday interaction. If your primary motive is money, then every interaction with a client becomes an opportunity to sell. Cross sell. Up sell. Bundle. Close a deal.
But imagine a client who has had a problem with your company and waited 30 minutes to speak to someone. Trying to sell to them in that moment is not clever. It is inappropriate and insensitive, and the client feels it instantly and the discomfort of the consultant trying to push something at an inappropriate time, is palpable to all.
When the motive is right, the response changes completely. You let them go. You apologise properly. You fix the issue. You give them a loyalty reward. And perhaps quietly, inside that reward, you include the special offer you were hoping to sell. The sale is no longer the point; the relationship is.
When money is the motive, you optimise for extraction. When care is the motive, you optimise for trust.
7. Why Motives Trump Marketing Every Time
Without good motives, nothing is durable. Clients may tolerate you for a while. They may respond to discounts or campaigns. But they will not trust you.
Motives leak. They show up in tone, timing, tradeoffs, and priorities under pressure. They are externally visible, and they overpower whatever marketing budget you have. No amount of brand spend can hide bad intent for long.
Motives make you naked. They expose who you really are to your staff, your peers, and your clients. Which is why it is far better to understand where your team is coming from before your clients do.
8. Culture Is Observed, Not Declared
You cannot train motive, policy motive, or audit motive. You can only observe it. And observation requires reduced control, real autonomy, real responsibility, and real consequences.
Leadership development is not about preparing people to perform. It is about creating conditions where their true motivations surface.
9. The Counterintuitive Leadership Discipline
Great leaders do something uncomfortable. They release control before people are senior. They watch carefully, take notes, and intervene early. This feels risky, but the real risk is discovering too late who someone becomes when they are finally free.
10. The Choice Every Organisation Faces
You can control tightly, promote safely, and be shocked later. Or you can release thoughtfully, observe honestly, and promote with conviction.
Walk into any large organisation and ask a deceptively simple question:
“What does everyone do?”
Not what are your job titles, not what does your org chart say, but what do people actually do all day.
The silence that follows is never accidental.
This blog is a reframing of Pournelle’s Iron Law of Bureaucracy, but instead of stopping at criticism, it moves toward organisational design. Not growth. Not scale. Design.
The uncomfortable truth is this: Most organisations are not designed. They are accumulated. And as with all accumulated systems, organisations will typically overdevelop the wrong muscles.
2. Pournelle’s Law, Reframed for Builders
Jerry Pournelle’s Iron Law of Bureaucracy is often quoted but rarely explained properly. Pournelle observed that in any bureaucratic organisation, two groups inevitably emerge:
Those dedicated to the goals of the organisation
Those dedicated to the organisation itself
Over time, group two always wins. Not because they are malicious. Not because they are incompetent. But because bureaucratic systems naturally reward process management, risk avoidance, and internal justification over outcome creation.
This is usually presented as an inevitability. A law of nature. Something to be managed rather than designed against. That framing is wrong. The problem is not bureaucracy. The problem is muscle imbalance.
3. The Human Body Got This Right
The human body is not symmetrical. It is intentionally imbalanced.
The bicep is larger than the tricep
The quadriceps overpower the hamstrings
The muscles responsible for action dominate those responsible for restoration
Why?
Because doing work is the primary objective. Restoring from work is a necessary but secondary function.
If your triceps were as strong as your biceps, you would struggle to lift anything. If your hamstrings dominated your quads, you would fall over trying to walk. Balance is not symmetry. Balance is intentional asymmetry.
4. Organisations Ignore Biology
Most organisations do the exact opposite. They grow antagonist muscles without restraint:
Risk teams grow faster than delivery teams
Compliance expands while execution stalls
Oversight multiplies while accountability evaporates
Reporting increases while action decays
Soon, the organisation can review, approve, audit, escalate, and govern far better than it can build, ship, fix, or change anything. At that point, the organisation is not safe. It is immobile.
5. The Risk Team Thought Experiment
Imagine a risk function with thousands of people. Now imagine there is nobody with the authority, skills, or capacity to action the outcomes. What do you actually have?
Risk is identified ✔
Risk is documented ✔
Risk is escalated ✔
Risk is reported ✔
But risk is not reduced. This is not risk management. This is risk theatre.
A massive tricep attached to a withered bicep does not make you safer. It makes you weak in slow motion.
6. Growth Is Not a Neutral Act
Teams cannot be allowed to arbitrarily grow. Headcount is not free. Every new role changes the force distribution of the organisation.
Uncontrolled growth does three dangerous things:
It creates internal demand for justification
It invents work to sustain itself
It shifts power away from execution toward process
At some point, people are no longer hired to do work. They are hired to explain work to other people who do not do it. That is the moment Pournelle’s law stops being theoretical.
7. Composition Beats Size Every Time
The question is never:
“Do we need a risk team?”
The real question is:
“How strong should this muscle be relative to the others?”
A healthy organisation has:
A dominant delivery muscle
A smaller but sharp oversight muscle
A thin but highly competent governance layer
A direct and short feedback loop between them
The moment an antagonist muscle becomes larger than the muscle it exists to protect, you have inverted the system. And inverted systems always collapse inward.
8. Designing for Intelligent Weakness
Here is the counterintuitive rule:
Some organisational muscles must be kept deliberately weak.
Not incompetent. Not underfunded. Weaker – relative to execution.
This forces discipline:
Risk must prioritise, not catalogue
Governance must decide, not defer
Compliance must enable, not smother
Strategy must choose, not narrate
Management, team leaders, delivery leads etc must all have dedicated execution teams with agree ratios.
Weakness creates focus. Strength without constraint creates entropy.
9. Ask Better Questions, Not Just More Questions
“What does everyone do?” is not a one off audit question. It is a leadership habit. But it is not enough on its own. Leaders must also ask:
What would actually break if this person stopped doing their role tomorrow?
And do we care?
If nothing breaks, or the only impact is that a report is late or a meeting is cancelled, you are not looking at a critical muscle. You are looking at organisational scar tissue. Closely related is an even more dangerous question:
Who reads these reports?
What decisions do they make because of them?
What actions follow?
If the answers are vague, ceremonial, or deferred to another committee, the output exists to justify the role, not to reduce risk or improve outcomes.
Auditors will never find this. Dashboards will never show it. Only a technically and operationally competent leader will.
10. Calculating Your Bloat Ratio
Divide your organisation into two buckets.
Builders: People who build, design, operate or fix systems. If they disappeared and outcomes degraded, they are builders.
Everyone else: Management, coordination, reporting, governance and oversight.
Bloat Ratio = Non builders divided by builders.
Set targets for this. If you do not, the organisation will choose for you.
Ask the Question Regularly:
What does everyone do is a leadership habit?
Ask: Who creates value? Who restores the system? Who only talks about the system? What would break if this role stopped? Do we care?
11. Conclusion: Build Like a Body, Not a Bureaucracy
Organisations are not machines. They are not flowcharts. They are living systems.
Living systems survive through asymmetry, constraint, and intent.
If everyone exists to restore, nobody builds. If everyone governs, nothing moves. If everyone reviews, nothing improves.
So ask the question. Then ask what would break. Then decide if you care.
What does everyone do?
And more importantly:
Which muscles have you allowed to grow without thinking?
Do not be misled, bloat left unmanaged will create its own connected ecosystem and slowly choke your companies life blood. It will kill you faster than your competitors ever could.
If you look back over time at all once great companies, you will see that eventually simplicity gave way to scale. What are some of the risks that drive this?
Product sprawl (payments, credit, insurance, business banking)
Complexity creep in operations
More regulators, more rules, more controls
Cultural dilution as headcount grows (nobody can answer the question “what do all those people actually do?”)
This is where many great banks lose their edge. But is this really a shared destiny for all banks, or did the leadership simply fail to lead?
It is a comforting idea: scale is gravity, and operational drag is just what happens when you get big. If that were true, every large organisation would converge on the same outcome: bloated estates, fragile systems, endless governance, and chronic delivery failure. But complexity is not a law of nature. It is a residue. It is what remains when decisions are postponed instead of resolved. It is what accumulates when compromise is allowed to harden into architecture. It is what grows when organisations confuse activity with progress.
Two banks can grow at the same pace, operate under the same regulatory regime, and still end up with radically different realities.
The difference is not growth. The difference is what growth is allowed to amplify.
1. Doesn’t Growth Force Layers, Process, and Bureaucracy?
Growth forces repetition. It does not force bureaucracy.
Bureaucracy appears when organisations stop trusting their systems to behave predictably. It is a defensive response:
to systems that are too coupled to change safely
to teams that cannot deploy independently
to ownership that is unclear or contested
to leadership that lacks technical confidence
In well designed environments, growth punishes excess process because process slows feedback. Simplicity becomes a survival trait.
In poorly designed environments, growth rewards control because control is the only way to reduce surprise. Scale does not create bureaucracy. Fear does.
2. Don’t Mature Product Portfolios Naturally Become Complex?
Only if nothing ever truly ends. Product complexity explodes when organisations refuse to delete. Old products linger because retirement is politically painful. New products are layered on top because fixing the original mistake would require accountability.
Over time, the portfolio stops being intentional. It becomes archaeological. Operational complexity emerges when:
product boundaries are unclear
shared state becomes the default
release cycles are coupled
incidents span multiple domains by design
Maturity is not the accumulation of features. Maturity is the accumulation of clarity.
3. Growth Reveals Truth. It Does Not Change It.
Screenshot
This is the uncomfortable part. Scale is not a transformation engine. It is an amplifier. Growth does not turn good systems into bad ones. Growth turns weak assumptions into outages. If you already have:
strong technical leadership, growth accelerates decision making
predictable delivery, growth increases confidence
resilient architecture, growth improves stability
If you already have:
unclear ownership, growth magnifies politics
entangled systems, growth multiplies blast radius
indecision, growth creates paralysis
weak architecture, growth exposes fragility
When people say “they will become complex as they grow”, what they are really saying is: “Growth will expose whatever they have been avoiding.”
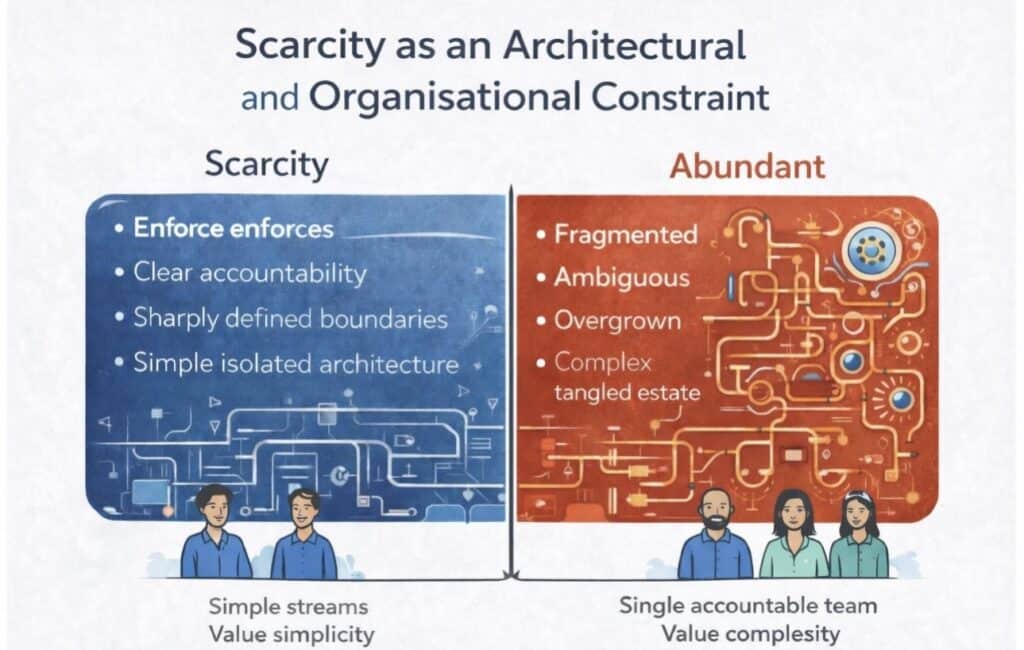
4. Why Does Scarcity Force Simplicity Including Organisational Design?
Screenshot
Scarcity is not just a financial or technical constraint. It is an organisational one.
When resources are scarce, organisations are forced to make explicit choices about ownership, scope, and accountability. You cannot create twenty product teams for the same savings account and hope simplicity will somehow emerge either for the client or architecturally. Scarcity enforces:
a small number of clearly accountable teams
sharply defined product boundaries
single sources of truth
architectural coherence
When you only have a handful of teams, duplication is obvious and intolerable. Overlap becomes expensive immediately. Decisions are made early, when they are still cheap. Abundance breaks this discipline. With enough people and budget, organisations fragment responsibility:
multiple teams own different “aspects” of the same product
customer journeys are split across silos
data ownership becomes ambiguous
architecture starts to mirror reporting lines instead of domains
This is how organisations create massive internal motion while the customer experience degrades and operational risk increases.
Organisational simplicity and architectural simplicity are inseparable. If your org chart is tangled, your systems will be too.
Screenshot
5. Doesn’t Maturity Inevitably Create Complexity?
No, and this is where many organisations lie to themselves.
We routinely confuse an organisation getting older with an organisation becoming mature. They are not the same thing. Maturity does not create complexity, but immaturity does.
As immature organisations age, they do not magically become disciplined, coherent, or deliberate. They reveal their immaturity more clearly. Deferred decisions surface. Leadership vacuums widen. Weak architectural choices harden into constraints.
Organisations are not like bottles of wine that effortlessly reveal sophistication over time. They are more like a box of frogs, full on entropy and constantly needing to be corrected.
Without active leadership, clarity, and constant intervention, entropy takes over. Chaos rushes in where decisions are delayed. Politics replaces strategy when direction is absent.
Time is not a cure. Time is an accelerant.
Screenshot
6. Isn’t Operational Drag Simply the Cost of Regulation and Risk?
Regulation adds constraints. It does not mandate chaos. In practice, regulators reward:
clean boundaries
deterministic processes
auditable flows
explicit accountability
What creates regulatory pain is not simplicity but opacity: tangled estates, unclear data lineage, and uncontrolled change paths.
Many organisations hide behind regulation because it is a convenient excuse not to simplify. Compliance does not require complexity. It requires clarity.
7. Don’t All Large Systems Eventually Become Fragile?
Large does not mean fragile. Coupled means fragile. Fragility appears when:
multiple products share the same state
deployments are linked
teams cannot change without coordination
ownership is blurred
Resilience comes from clean failure domains.
If systems are isolated, you can grow without multiplying outage impact. If they are not, every new product increases systemic risk.
8. Isn’t This Just a Different Phase of the Same Journey?
This assumes there is only one destination.
It implies every organisation eventually converges on the same architecture, the same cost base, and the same operational burden.
That belief protects poor performance. There are divergent paths:
one treats simplicity as a first class constraint
the other treats complexity as inevitable and builds governance to manage the damage
These are not phases. They are philosophies.
9. If Complexity Isn’t Inevitable, Why Do So Many Organisations Suffer From It?
Because complexity is what you get when you refuse to choose. It is easier to:
keep two systems than retire one
add a layer than remove a dependency
add a new product, than fix the existing ones
create a committee than empower a team
declare inevitability than admit poor decisions
Operational complexity is not created by growth. It is created by accumulated compromise.
10. So What Actually Creates Operational Complexity?
Almost always the same four forces:
Indecision Parallel paths are kept alive to avoid conflict.
Product complexity Portfolios grow without pruning.
Poor strategic architectural decisions Short term delivery is traded for long term fragility.
No technically viable strategy for co existence Products cannot live in isolated domains.
Growth does not cause these. Growth merely exposes them.
11. What Is the Real Destiny?
There is no destiny. There is only design. Organisations that invest in:
scarcity as a deliberate constraint
value stream aligned organisational design
isolation as a scaling strategy
strong technical leadership
ruthless simplification
Do not collapse under growth. They compound efficiency. Those that do not, will call their outcomes “inevitable”. They never were.
I once worked in a company with spectacularly low trust. Everything took ages (like years), quality was inconsistent (at best),costs were extraordinary and there was almost no common understanding of why things were so bad.
Clients were charged a small fortune for products that competitors could deliver at a fraction of the price. Internally, this was not seen as a signal of systemic dysfunction. Instead, leadership convinced itself that the real problem was staff dishonesty.
People were not struggling. They were lying. Or so the story went.
2. When Control Becomes the Strategy
Once you believe the problem is dishonesty, the solution seems obvious: control harder.
The organisation began contracting everyone into their commitments. Meetings stopped being places where ambiguity could be explored and became legal style discovery exercises. One leader even started recording meetings, as if future playback would somehow convert uncertainty into accountability.
Timesheets followed. Surely if every minute was captured and categorised, delivery would improve. When that failed, internal cross charging arrived. Entire teams were hired whose sole job was to recharge teams to other teams, under the belief that the tension of accepting internal charges would force discipline and performance.
None of this worked.
The only measurable outcome was a larger organisation with more friction, more defensiveness and more arguments. Energy moved away from delivery and toward self protection and tribalism.
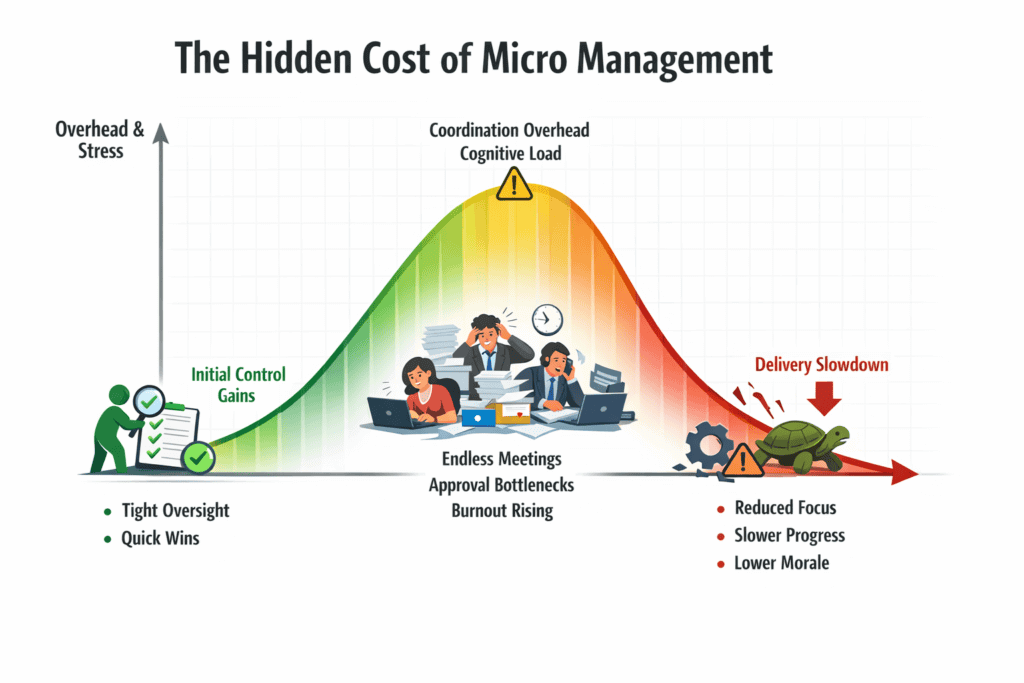
3. Micro Management and the Hidden Tax on Delivery
What leaders consistently underestimate is the overhead of micro management.
Every additional approval step slows flow. Every forced status update steals time from real work. Every justification meeting teaches people to optimise for optics, not outcomes.
Micro management does not just consume time, it fragments attention. Engineers stop thinking in systems and start thinking in inboxes. Teams stop solving problems and start preemptively defending themselves against future blame.
The most damaging part is that micro management creates the illusion of control while actively degrading capability. The people closest to the work lose autonomy. The people farthest from the work gain dashboards. And everyone feels busy.
Low trust organisations never account for this tax. They measure utilisation. They measure hours. They never measure how much thinking capacity they have destroyed.
4. Naval Gazing Disguised as Rigor
The result is a culture of permanent explanation.
Every delay requires a post mortem. Every miss spawns a deck. Every deck spawns more meetings.
This is not rigor. It is naval gazing. It is the organisation staring at itself instead of the problem it exists to solve.
In these environments, explanation replaces progress. And explanation without progress looks indistinguishable from excuse making.
Trust does not increase. It decays.
5. The Counterintuitive Reality of Trust
Here is the uncomfortable truth leaders eventually discover, usually too late.
Trust on projects nobody understands gets built through demonstrated competence in small increments, not through explanation.
The instinct is always to educate stakeholders until they understand enough to trust the work. This rarely succeeds. Complex technology resists compression into executive summaries. Attempts to do so either oversimplify to the point of dishonesty or overwhelm people into silent nodding.
Worse, explanation without delivery erodes credibility.
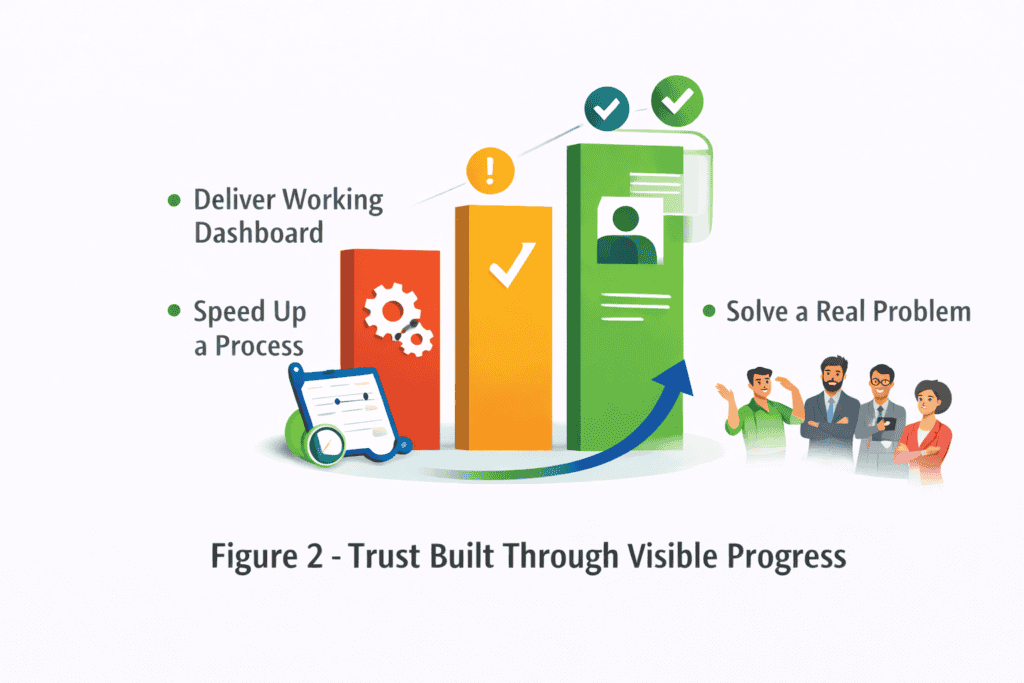
6. Deliver Something Tangible, Early
The fastest way to build trust is to ship something real.
Not a proof of concept only engineers can appreciate. Something visible. Something that solves a real problem, however small. A dashboard that now exists. A process that now completes in minutes instead of days.
People will happily say “I don’t understand how it works” as long as they can also say “but I can see that it does”.
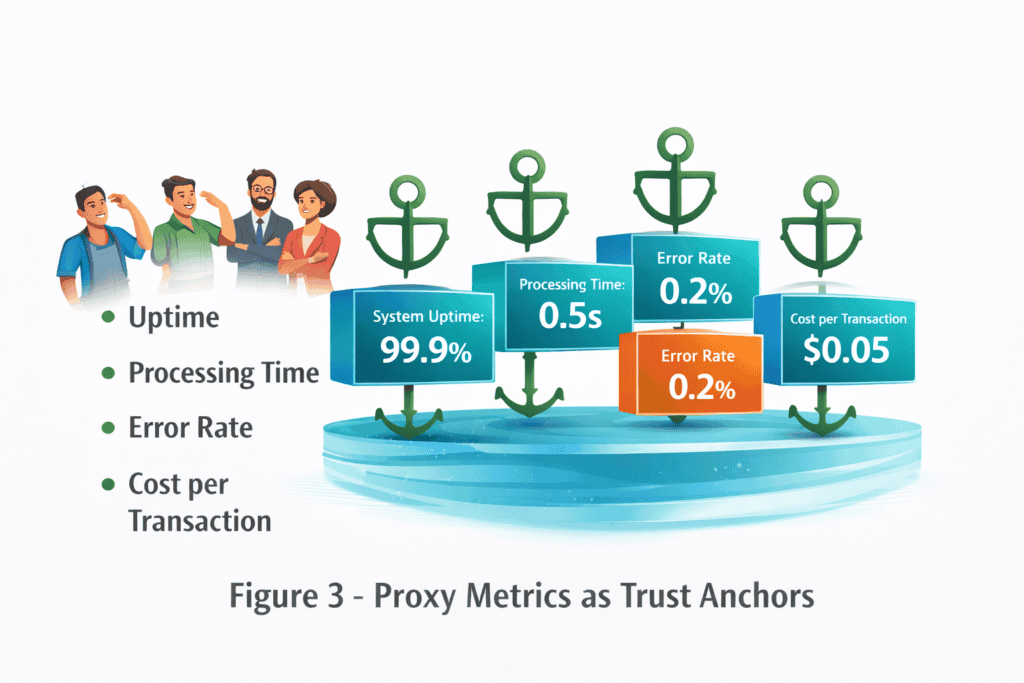
7. Create Proxy Metrics People Can Track
If stakeholders cannot evaluate the technical work directly, give them metrics they can understand.
Uptime. Latency. Error rates. Cost per transaction.
These become trust anchors. They allow leaders to observe improvement without needing to understand the machinery underneath. Over time, the metrics speak for the team.
8. Be Predictable Where It Counts
Predictability is deeply underrated.
Status updates at the same time every week. Budgets that do not surprise. Risks surfaced early, not theatrically late.
When the visible parts of a project are calm and disciplined, people extend trust to the invisible technical work. Chaos in communication destroys confidence even when the engineering is sound.
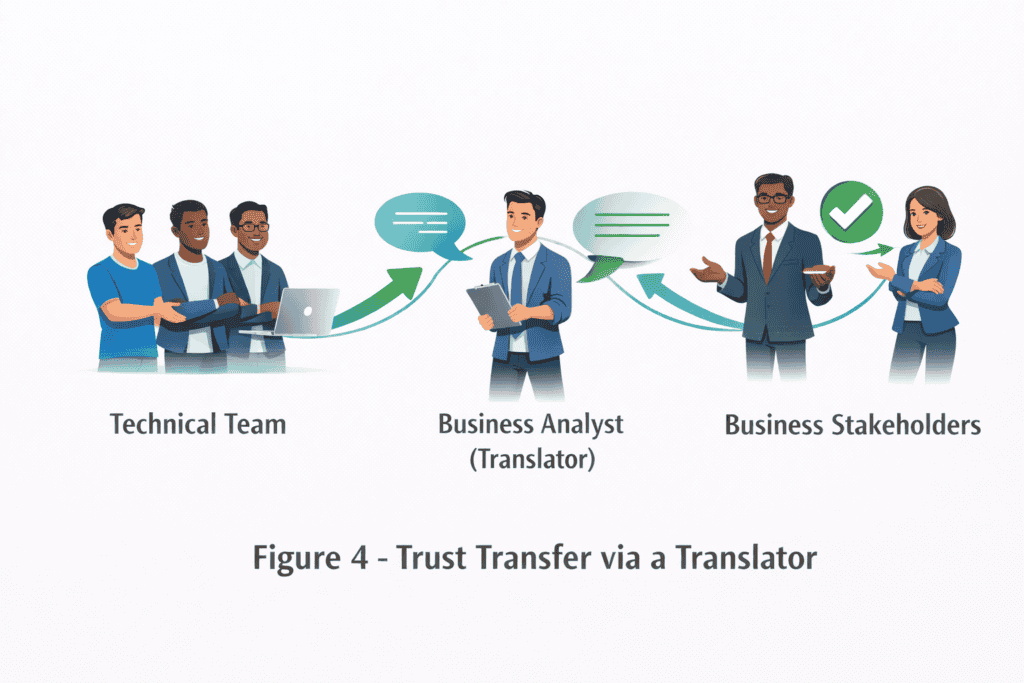
9. Find a Trusted Translator
Trust often flows through people, not artefacts. A technically literate but business fluent individual can act as a bridge. A product owner. A business analyst. A respected engineering lead. Their confidence becomes transferable. Stakeholders who trust them begin to trust the team by proxy. This is not politics. It is how humans reduce uncertainty.
10. How High Trust Organisations Actually Operate (And Why This Feels Uncomfortable)
This is the part that tends to shock people who have spent years inside low trust organisations.
High trust organisations do not look more controlled. They look dangerously loose.
There are fewer approvals, not more. Fewer meetings, not more. Less documentation, not less accountability.
From the outside, they can appear reckless. From the inside, they feel calm.
Failure Is Not a Scandal
In low trust organisations, failure is treated like a crime scene. Access is restricted. Statements are taken. Timelines are reconstructed. The goal is to find who caused the problem, because blame is the only available control mechanism.
In high trust organisations, failure is treated like telemetry.
Something happened. That means the system just told us something useful.
The first questions are not “who approved this?” or “why did you say it would work?” They are “what broke?”, “what signal did we miss?”, and “how do we make sure this class of failure cannot happen again?”
This is why post incident reviews in high trust environments feel almost unsettling to newcomers. They are calm. Factual. Almost boring. Nobody is performing. Nobody is defending themselves. There is nothing to defend.
It Is Still a Commercial Organisation
High trust does not mean naive.
These organisations are still commercial entities with customers, margins and obligations. Repeated failure, negligence or consistently poor judgment is not ignored, and it is not endlessly tolerated. The difference is how it is handled.
Patterns of behaviour are addressed deliberately and discretely. Conversations happen early, in private, and with clarity. Expectations are restated. Support is offered where it makes sense. When change does not occur, decisions are made without theatre, public shaming or moral grandstanding.
Accountability is real, but it is exercised with dignity.
This is intentional. Public punishment erodes trust far beyond the individual involved. Quiet, decisive action preserves the integrity of the system while protecting everyone else’s ability to operate without fear.
Accountability Is Structural, Not Personal
Low trust organisations believe accountability comes from pressure. High trust organisations know it comes from design.
Clear ownership exists, but it is paired with real authority. Teams are accountable for outcomes they can actually influence. When something fails outside their control, the organisation fixes the interface, not the person.
People are not asked to commit to certainty they do not possess. They are asked to commit to discovery, transparency and response. This removes the incentive to lie.
Failure Is Paid for Once
Low trust organisations pay for failure repeatedly.
They pay in meetings. They pay in reporting. They pay in re approval cycles. They pay in talent attrition.
High trust organisations pay for failure once, by fixing the underlying mechanism that allowed it to occur.
A bad deploy does not result in more approval gates. It results in better automated checks. An outage does not result in stricter sign off. It results in improved isolation, better fallbacks and clearer operational metrics.
The system gets stronger. The people are left intact.
You Are Trusted Until You Prove Otherwise
This is the hardest concept for people coming from low trust environments to internalise.
In high trust organisations, trust is the default state.
People are assumed to be competent and acting in good faith. Controls are added only where evidence shows they are needed. And when trust is violated, the response is precise and local, not systemic and punitive.
One failure does not collapse trust in the entire organisation.
The Real Source of the Shock
The real shock is not how failures are handled. The shock is realising how much energy low trust organisations waste trying to prevent embarrassment rather than improving capability. How much human creativity is sacrificed in the name of control. How many smart people are trained to explain instead of build.
Once you see how a high trust organisation operates, it becomes impossible to unsee the dysfunction.
11. Admit Uncertainty Without Flinching
False certainty is one of the fastest ways to destroy trust.
Saying “we don’t know yet” followed by “here is how we will find out” builds far more confidence than over confident predictions that later collapse. People forgive uncertainty. They do not forgive being misled.
Honesty about unknowns is a trust accelerant.
12. What Stakeholders Are Really Asking
At its core, this was never about technology. Trust on these projects is trust in people.
Stakeholders are asking whether you will tell them early when things go wrong. Whether you will protect their interests when they cannot protect themselves. Whether your judgment is sound even when they cannot personally verify the details.
Low trust organisations try to replace these questions with process, surveillance and contracts. High trust teams answer them through behaviour. And this is the uncomfortable conclusion.
When trust is missing, organisations reach for control. When trust is present, control becomes almost unnecessary. Confusing control with delivery feels safe. But it is one of the most reliable ways to ensure you get neither.
Ultimately, trust is built through demonstrated competence, not control.
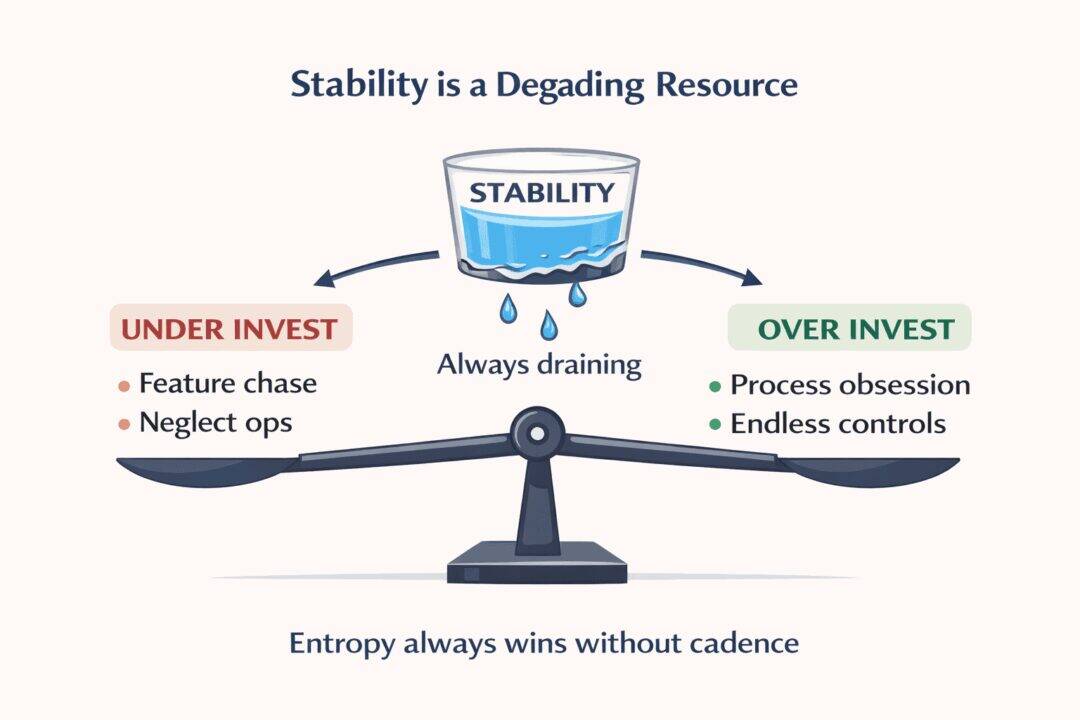
Most companies do not fail because they cannot innovate. They fail because they misjudge stability.
Some organisations under invest. They chase features, growth, and deadlines while stability quietly drains away. Outages feel sudden. Incidents feel unfair. Leadership asks how this happened “out of nowhere”.
Other organisations over invest. They build process on process, reviews on reviews, controls on controls. Delivery slows to a crawl. Engineers disengage. The system becomes stable but irrelevant. Eventually the business collapses under its own weight. Both groups are wrong for the same reason.
They treat stability as a thing you can reason about intellectually instead of a resource that behaves physically. Most corporate conversations about stability sound like this:
“Are we stable enough?”
“Do we need more resilience?”
“Let’s prioritise reliability this quarter”
“Teams can work on stability when they think it’s needed”
These are the wrong questions. Stability is not binary. It is not something you have or do not have. It is something that is constantly leaking away.
Entropy never pauses. Complexity always grows. Dependencies always drift.
So the real question is not how much stability do we want? It is how do humans reliably maintain something that is always degrading, even when it feels fine?
To answer that, it helps to stop thinking like executives and start thinking like biology. And that brings us to a very simple walking experiment.
1. A Simple Walking Experiment
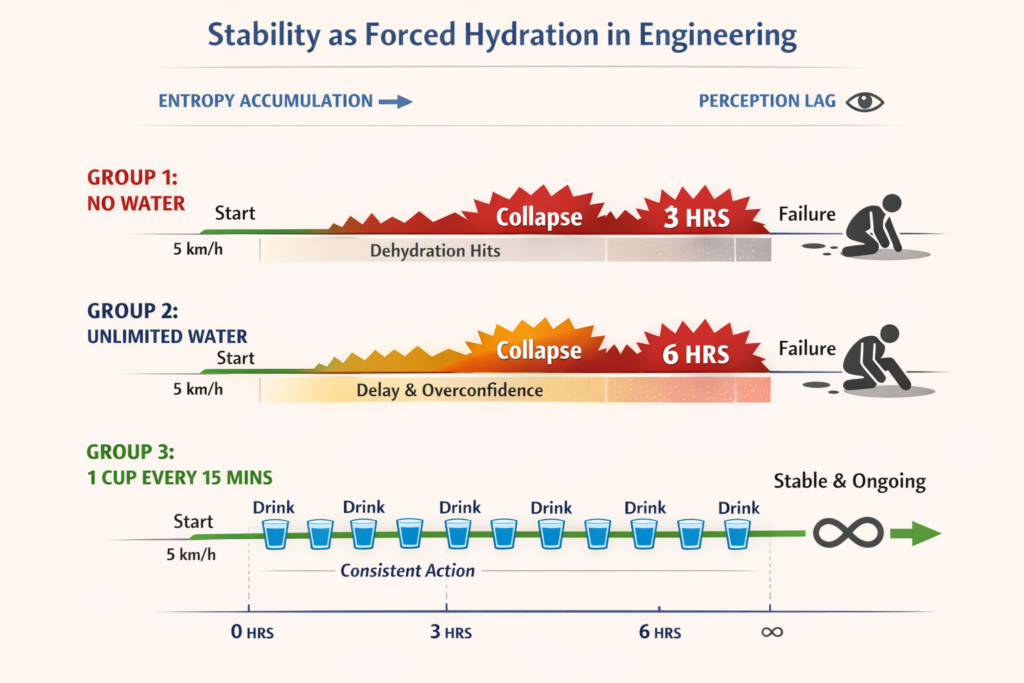
Imagine three groups of walkers. All three walk at exactly 5 km per hour. The terrain is the same. The weather is the same. The only difference is how they consume water.
This is not a story about hydration. It is a story about engineering stability.
Group 1: No Water
This group decides they will push through. Water is optional. They feel strong. They feel fine.
No surprises. they fail after 3 hours.
Group 2: Unlimited Water
This group has all the water they could ever want. Drink whenever you feel like it. No limits. No rules.
This group goes longer, BUT still fails after 6 hours.
Group 3: One Cup Every 15 Minutes
This group is forced to drink one cup of water every 15 minutes. Even if they are not thirsty. Even if they feel fine. Even if they think it is unnecessary.
They walk forever.
2. Who Wins and Why?
The obvious loser is Group 1. Deprivation always kills you quickly.
But the surprising failure is Group 2. Unlimited water feels like safety. It feels mature. It feels trusting. Yet it still fails. Why?
Because humans are terrible at sensing slow degradation. By the time thirst is obvious, damage is already done. By the time things feel unstable, they are likely in already in a really bad place.
Group 3 wins not because they are smarter. They win because they removed judgment from the system.
3. Stability Is Like Water
Stability in engineering behaves exactly like hydration. It is:
Always leaking away
Always trending down
Never something you “finish”
You do not reach a stable system and stop. You only slow the rate at which entropy wins.
The moment you stop drinking, dehydration begins. The moment you stop investing in stability, decay begins. There is no neutral state.
4. Why does “Do It When You Need It” Fail?
Many teams treat stability like Group 2 treats water.
“We can fix reliability whenever we want.” “We have budget for it.” “We will focus on it after this delivery.” “We are stable enough right now.”
This is a lie we tell ourselves because:
Instability accumulates silently
Risk compounds invisibly
Pain arrives late and all at once
Your appetite for stability is not accurate. Your perception lags reality. By the time engineers feel the pain:
Pager load is already high
Cognitive load is already maxed
Trust in the system is already gone
5. Why Forced, Small, Regular Work Wins
Group 3 survives because the rule is boring, repetitive, and non negotiable.
One cup. Every 15 minutes. No debate.
Engineering stability works the same way.
Small actions:
Reviewing error budgets
Paying down tiny bits of tech debt
Exercising failovers
Reading logs when nothing is broken
Testing restores even when backups “worked last time”
These actions feel unnecessary right up until they are existential.
The key insight is this:
Stability must be regular, small, and forced, not discretionary.
6. Carte Blanche Stability Still Fails
Giving teams unlimited freedom to “do stability whenever they want” feels empowering. It is not. It creates:
Deferral
Rationalisation
Optimism bias
Hero culture
Just like unlimited water, people will drink:
Too late
Too little
Only when discomfort appears
And discomfort always appears after damage.
7. Stability Is Not a Project
You do not “do stability”. You consume it continuously. Miss a few intervals and you do not notice. Miss enough and you collapse suddenly. This is why outages feel unfair. “This came out of nowhere.” – it never did. You authored it, when you made stability a choice.
8. The Temporary Uplift of New Leadership and Why It Fades
There is a familiar pattern in many organisations.
New leadership arrives. Energy lifts. Standards tighten. Questions get sharper. Long ignored issues suddenly move.
For a while, stability improves.
This uplift is real, but it is also temporary.
Why?
Because much of the early improvement does not come from structural change. It comes from attention.
People prepare more. Risks are surfaced that were previously hidden. Teams clean things up because someone is finally looking.
But attention is not a system. It does not scale. And it does not last. Over time, leaders get pulled upward and outward:
Strategy
Budgets
Politics
External pressure
The deep, uncomfortable details fade from view again. Entropy resumes its work. Eventually the organisation concludes it needs:
A new leader
A new structure
Another reset
And the cycle repeats.
8.1 Inspection Is Not Optional
John Maxwell captured this simply:
“What you do not inspect, you cannot expect.”
Stability is not maintained by policy. It is maintained by inspection. Leaders cannot delegate this entirely.
Dashboards help, but they are abstractions. Audits help, but they are compliance driven. Neither replaces technical curiosity.
8.2 Why Audits Miss the Real Risks
Auditors are necessary, but they are constrained:
They work to checklists
They assess evidence, not behaviour
They validate controls, not fragility
They rarely ask:
What happens under load?
What breaks first?
What do engineers silently work around?
Where are we “hoping” things hold?
A technically competent leader, even without writing code daily, will notice:
Architectural smells
Operational anti patterns
Client complains
Excessive handoffs during fault resolution
Risk concentration
Overly large blast radii
“Accepted” risks no one remembers accepting
These things do not show up in audit findings. They show up in deep dives.
8.3 Leadership Must Periodically Go to the Gemba
If leaders want stability to persist beyond their honeymoon period, they must:
Periodically deep dive the estate
Sit with engineers in the details
Review real incidents, not summaries
Ask uncomfortable “what if” questions
Not continuously. But deliberately. And repeatedly. This does two things:
It resets attention on the highest risks
It reinforces that stability is not someone else’s job
8.4 Sustainable Stability Outlives Leaders
The goal is not to rely on heroic leaders. The goal is to build systems where:
Risk surfaces automatically
Attention is forced by mechanisms
Leaders amplify the system instead of substituting for it
New leadership should improve things. But stability should not depend on leadership churn. When stability only improves after a reset at the top, it is already leaking. The strongest organisations use leadership attention to reinforce cadence, not replace it.
9. The Engineering Lesson
Great engineering organisations do not trust feelings. They trust cadence. They bake stability into time:
Weekly reliability work
Fixed chaos testing intervals
Mandatory post incident learning
Forced operational hygiene
Even when everything looks fine. Especially when everything looks fine. Because that is when dehydration is already happening.
10. Conclusion: Turning Stability from Belief into Mechanism
Stability does not survive on intent. It survives on structure.
Most organisations say the right things about reliability, resilience, and operational excellence. Very few hard code those beliefs into how work actually gets done.
If stability depends on motivation, maturity, or “good engineering culture”, it will decay. Those things fluctuate. Entropy does not.
The only way stability survives at scale is when it is embedded as a forced, recurring behaviour.
10.1 Make Stability Time Non Negotiable
The first rule is simple: stability must have reserved time.
Set aside a fixed day each week, or a fixed percentage of capacity, that is explicitly not for delivery:
Automation
Observability improvements
Reducing operational toil
Fixing recurring incidents
Removing fragile dependencies
This time should not be borrowable. It should not be traded for deadlines. If it disappears under pressure, it was never real to begin with.
Just like forced hydration, the value is not in intensity. It is in cadence.
10.2 Always Run a Short Cycle Risk Rewrite Program
High risk systems should never wait for a “big modernisation”.
Instead, always run a rolling program that:
Identifies the highest risk systems
Rewrites or refactors them in small, contained slices
Finishes something every cycle
This creates two critical properties:
Risk is continuously reduced, not deferred
Engineers stay close to production reality
Long lived, untouched systems are where entropy concentrates. Short cycles keep decay visible.
10.3 Encode Stability as Hard Parameters
The most important shift is this: stop debating risk and start flushing it out mechanically.
Introduce explicit constraints that surface outsized risk early, for example:
Maximum database size: 10 TB
Maximum service restart time: 10 minutes
Maximum patch age: 3 months
Maximum server size: 64 CPUs
Maximum operating system age: 5 years
Maximum sustained IOPS: 60k
Maximum acceptable outage per incident: 30 minutes
These numbers do not need to be perfect. They need to exist.
When a system crosses one of these thresholds, it triggers a conversation. Not a blame exercise. A prioritisation discussion.
The goal is not to prevent exceptions. The goal is to make embedded, accepted risk visible.
10.4 Adjust the Numbers, Never the Principle
Over time, these parameters will change:
Hardware improves
Tooling matures
Teams get stronger
That is fine.
What must never change is the mechanism:
Explicit limits
Automatic signalling
Early discussion
Intentional action
This is how you prevent stability debt from silently compounding.
10.5 Stability Wins When It Is Boring
The organisations that endure do not heroically fix stability problems in crises. They routinely prevent them in boring ways.
Small actions. Forced cadence. Hard limits.
That is how Group 3 walks forever.
Stability is not something you believe in. It is something you operationalise. And if you do not embed it mechanically, entropy will do the embedding for you.
Not prototypes. Not proofs of concept. Real systems. Real risk. Real consequences.
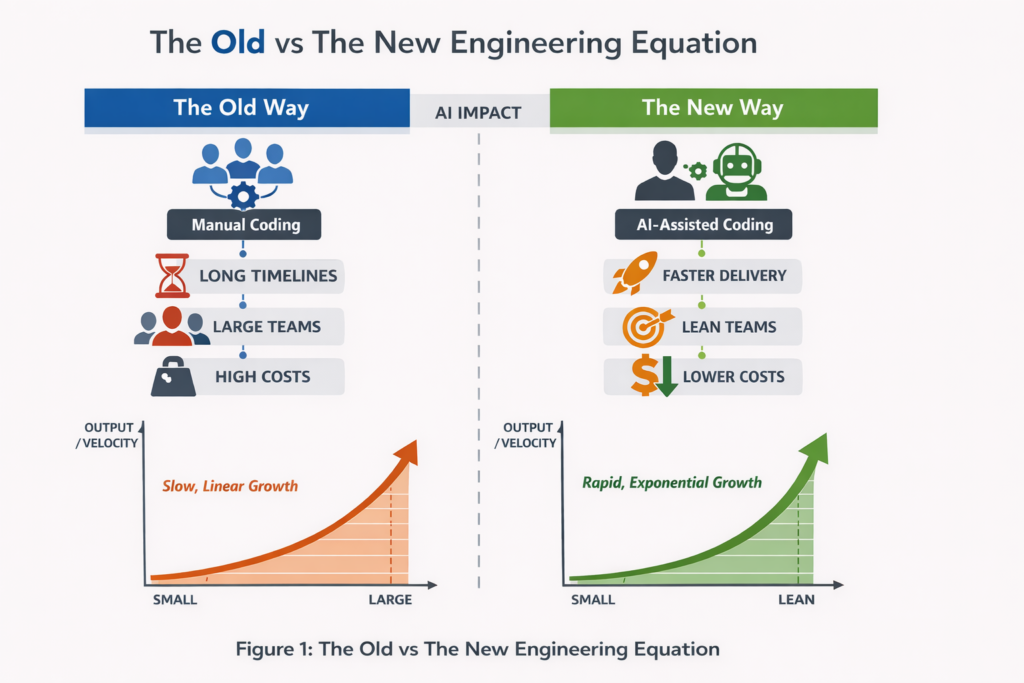
At Capitec, a very small group of engineers is now tackling something that would historically have demanded hundreds of people: large scale rewrites of core internet banking capabilities. This is not happening because budgets magically increased or timelines became generous. It is happening because the underlying economics of software engineering have shifted. Quietly. Irreversibly.
AI assisted development is not just making engineers faster. It is changing what is economically possible. And that shift has profound consequences for how systems are built, who wins, and who slowly loses relevance.
This is not about vibe coding. It is about a new engineering equation.
1. This Is Not Vibe Coding
There is a growing narrative that AI allows anyone to describe what they want and magically receive working software. That framing is seductive and dangerously wrong.
In regulated, high consequence environments like banking, blindly accepting AI output is reckless. What we are doing looks very different. AI does not replace engineering intent. It amplifies it.
Engineers still define architecture, boundaries, invariants, and failure modes. AI agents execute within those constraints. Every line of code is still owned by a human, reviewed by a human, and deployed under human accountability. The difference is leverage.
Where one engineer previously produced one unit of progress, that same engineer can now produce an order of magnitude more, provided the system around them is designed to absorb that speed.
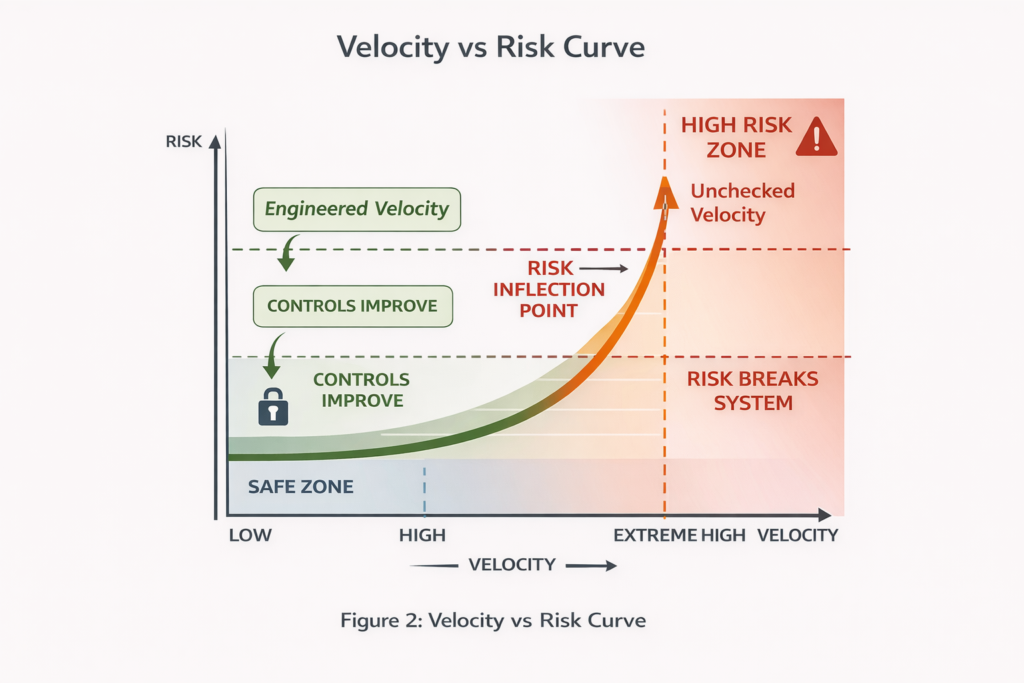
2. Agentic Engineering Changes Velocity and Risk at the Same Time
The most obvious benefit of AI assisted development is throughput. The less obvious cost is risk concentration.
When a small team moves at extreme velocity, mistakes propagate faster. Architectural errors are no longer local. Feedback loops that were “good enough” at traditional speeds become existential bottlenecks. This forces a recalibration.
You cannot bolt AI onto old delivery models and expect safety to hold. The entire lifecycle has to evolve. Velocity without compensating controls is not progress. It is deferred failure.
3. Testing Becomes a First Class Engineering Asset
At this scale and speed, testing stops being a checkbox activity and becomes a core product.
AI makes it economically viable to build things we previously avoided because they were “too expensive”:
Full system simulations
High fidelity fakes of external dependencies
End to end tests runnable locally
Failure injection under load
These are not luxuries. They are the only way to operate safely when AI is generating large volumes of code.
The paradox is that AI does not reduce the need for testing. It increases it. But it also collapses the cost of building and maintaining those test harnesses. This is where disciplined teams pull away from everyone else.
4. Feedback Loops Must Collapse or Everything Breaks
Slow feedback is lethal in high velocity systems. If your CI pipeline takes hours, you are already losing. If it takes days, you have opted out of this new world entirely.
Engineers and AI agents need confirmation quickly. Did this change break an invariant? Did it violate a performance budget? Did it alter a security boundary?
The goal is not just fast feedback. It is continuous confidence. Anything slower becomes friction. Anything slower becomes risk.
5. Coordination Beats Process at High Speed
Traditional process exists to manage scarcity. Meetings, approvals, handoffs, and documentation evolved when change was expensive. AI inverts that assumption.
When change is cheap and frequent, coordination becomes the scarce resource. Small, colocated teams with tight communication outperform larger distributed ones because decisions happen immediately.
This is not a tooling problem. It is an organisational one. The fastest teams are not the most automated. They are the most aligned.
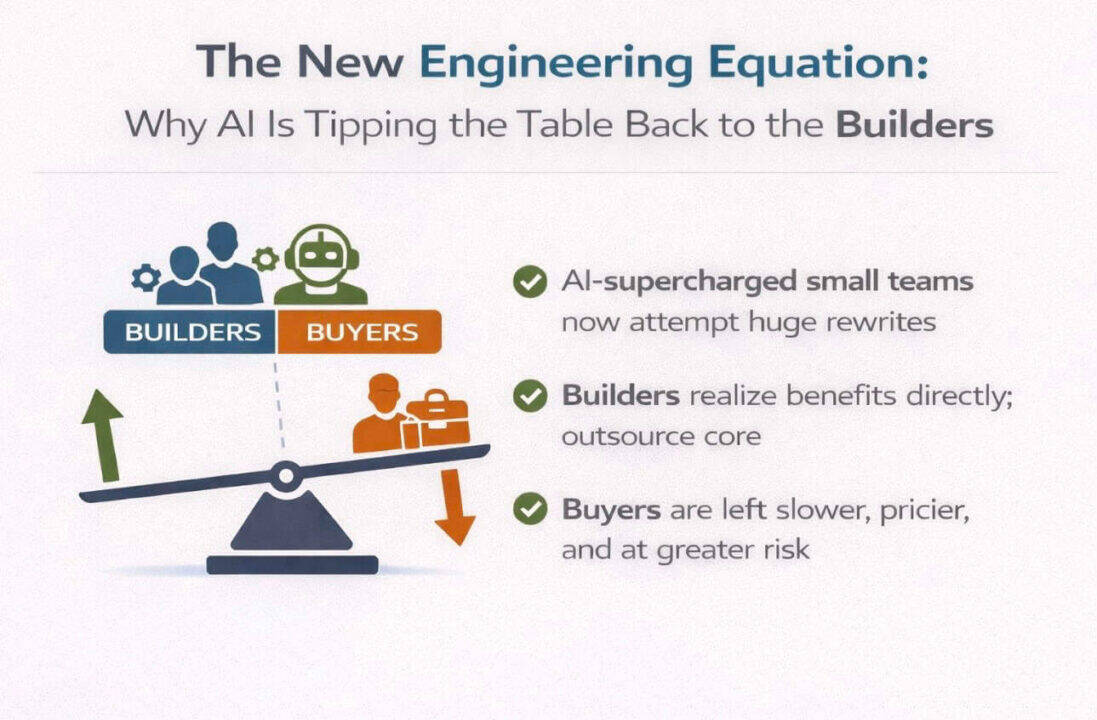
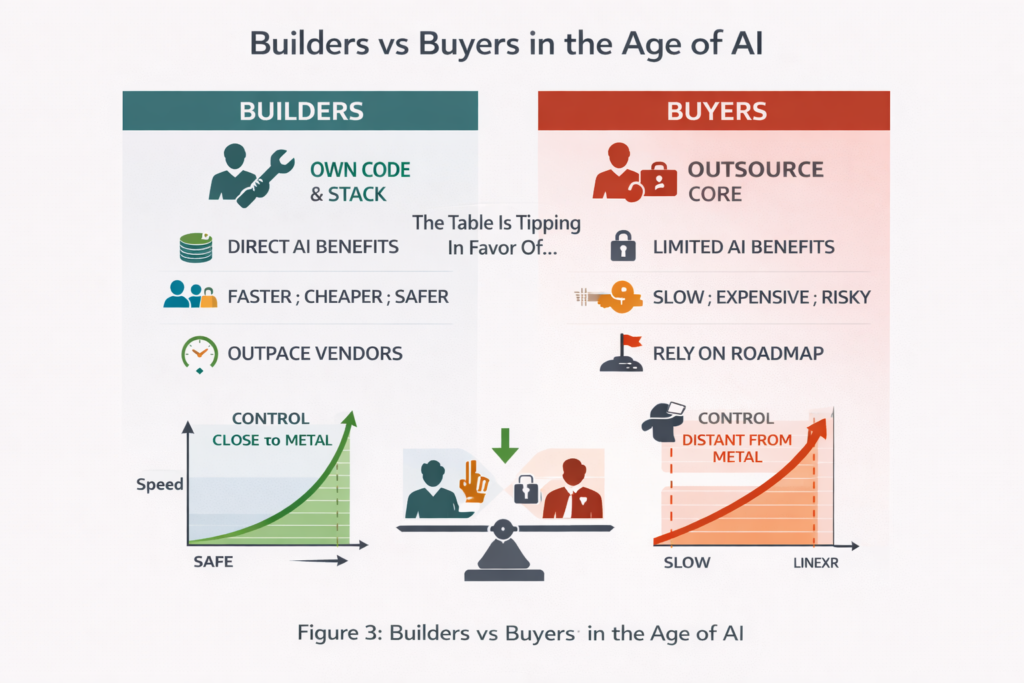
6. Why AI Favours Builders Over Buyers
There is an uncomfortable implication in all of this. The organisations extracting the most value from AI are those who still build their core systems.
If you are deeply locked into vendor platforms, proprietary SaaS stacks, or opaque black box solutions, you are structurally constrained. You do not control the code. You do not control the abstractions. You do not control the rate of change.
Vendors will absolutely use AI to improve their own internal productivity. But those gains will rarely be passed back proportionally. At best, prices stagnate. More often, feature velocity increases while commercial leverage shifts further toward the vendor. AI accelerates the advantage of proximity to the metal.
Builders can refactor systems that were previously untouchable. They can collapse years of technical debt into months. They can afford to build safety rails that previously failed cost benefit analysis. Buyers wait for roadmaps. This is a quiet power shift.
For the first time in a long time, small, highly capable teams can out execute organisations that outsourced their core competence. The table, at least for now, is tipping back toward the builders. Buying software is not wrong. Buying your core increasingly is.
The new currency is thinking, not doing. If you’re attached to a vendor then you need to parcel up your IP and wait for it to boomerang back to you, or maybe you can buy the execution from them at $1500 per day per resource 😳
7. What This Means for Large Scale Rewrites
Internet banking rewrites used to be multi year, multi vendor, high risk undertakings. The cost alone forced compromise. That constraint is eroding.
With AI assisted development, small teams can now attempt rewrites incrementally, safely, and with far more confidence; provided they own the architecture, the testing, and the delivery pipeline.
This is not about replacing engineers with AI. It is about removing everything that prevented engineers from doing their best work. AI does not reward ownership in name. It rewards ownership in practice.
Ownership of code Ownership of architecture Ownership of feedback loops Ownership of change
8. Conclusion: The New Flow of Ideas
What’s truly at stake isn’t just faster code or higher throughput. It’s the flow of ideas.
AI is not merely an accelerant. It is the scaffolding that allows ideas to move from intent to reality at unprecedented speed, while remaining safe. It creates the guard rails that constantly test that nothing has regressed, that negative paths are exercised, that edge cases are explored, and that vulnerabilities are surfaced early. AI probes systems the way attackers will, performs creative hacking before adversaries do, and exposes weaknesses while they are still cheap to fix.
None of this removes the need for engineers. Discernment still matters. Understanding still matters. Creation, judgment, and problem solving remain human responsibilities. AI does not decide what to build or why. It ensures that once an idea exists, it can move forward with far less friction and far more confidence.
What has changed is visibility. Never before has the speed difference between those who are progressing and those who are merely watching been so obvious. A gulf is opening between teams and companies that embrace this model and those constrained by vendor contracts, rigid platforms, and outsourced control. The former compound learning and velocity. The latter wait for roadmaps and negotiate change through contracts.
The table has shifted back toward the builders so structurally that it’s hard to see any other pathway to compete effectively. Ownership of code, architecture, and feedback loops now directly translates into strategic advantage. In this new engineering equation, speed is not recklessness. It is the natural outcome of ideas flowing freely through systems that are continuously tested, challenged, and reinforced by AI.
Those who master that flow will move faster than the rest can even observe.
Why More Information Doesn’t Mean More Understanding
We’ve all heard the mantra: data is the new oil. It’s become the rallying cry of digital transformation programmes, investor pitches, and boardroom strategy sessions. But here’s what nobody mentions when they trot out that tired metaphor: oil stinks. It’s toxic. It’s extraordinarily difficult to extract. It requires massive infrastructure, specialised expertise, and relentless refinement before it becomes anything remotely useful. And even then, used carelessly, it poisons everything it touches.
The comparison is more apt than the evangelists realise.
1. The Great Deception
Somewhere along the way, we convinced ourselves that accumulating information was synonymous with gaining understanding. That if we could just capture enough data points, build enough dashboards, and train enough models, clarity would emerge from the chaos. This is perhaps the most dangerous illusion of the modern enterprise.
I’ve watched organisations drown in their own data lakes, though calling them lakes is generous. Most are swamps. Murky, poorly mapped, filled with debris from abandoned projects and undocumented schema changes. Petabytes of customer interactions, transaction logs, sensor readings, and behavioural metrics, all meticulously captured, haphazardly catalogued, and largely ignored. The dashboards multiply. The reports proliferate. And yet the fundamental questions remain unanswered: What should we do? Why are we doing it? What does success actually look like?
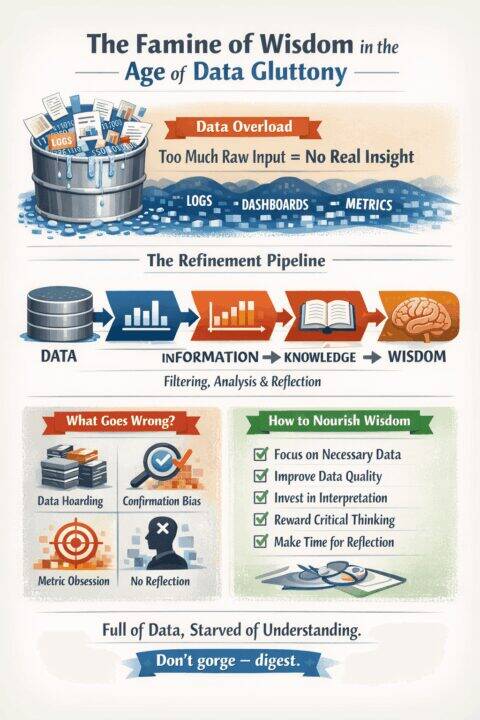
Information is not knowledge. Knowledge is not wisdom. And wisdom is not guaranteed by any quantity of the preceding.
2. The Refinement Problem
Crude oil, freshly extracted, is nearly useless. It must be transported, heated, distilled, treated, and transformed through dozens of processes before it becomes the fuel that powers anything. Each step requires expertise, infrastructure, and enormous capital investment. Skip any step, and you’re left with toxic sludge.
Data follows the same brutal economics. Raw data is not an asset. It’s a liability. It costs money to store, creates security and privacy risks, and generates precisely zero value until someone with genuine expertise transforms it into something actionable. Yet organisations hoard data like digital dragons sitting on mountains of gold, convinced that possession equals wealth.
The transformation from data to wisdom requires multiple refinement stages: Data must become information through structure and context. Information must become knowledge through analysis and interpretation. Knowledge must become wisdom through experience, judgement, and critically, self awareness. Each transition demands different skills, different tools, and different kinds of thinking. Most organisations have invested heavily in the first transition and almost nothing in the rest.
3. Tortured Data Will Confess Anything
There’s an old saying among statisticians: torture the data long enough and it will confess to anything. This isn’t a joke. It’s a warning that most organisations have failed to heed.
With enough variables, enough segmentation, and enough creative reframing, you can make data support almost any conclusion you’ve already decided upon. This is the dark side of sophisticated analytics: the tools that should illuminate truth become instruments of confirmation bias. The analyst who brings inconvenient findings gets asked to “look at it differently.” The dashboard that shows declining performance gets redesigned to highlight a more flattering metric. The model that contradicts the executive’s intuition gets retrained until it agrees.
If the data is telling you something that seems wrong, there are two possibilities. The first is that you’ve discovered a genuine insight that challenges your assumptions. This is rare and valuable. The second, far more common, is that something in your data pipeline is broken: bad joins, stale caches, misunderstood definitions, silent failures in upstream systems. Always validate. Always check your assumptions. And be deeply suspicious of any analysis that confirms exactly what you hoped it would.
4. Embedded Lies
Here’s something that keeps me up at night: data doesn’t just contain errors. It contains embedded lies. Not malicious lies, necessarily, but structural deceits built into the very fabric of what we choose to measure and how we measure it.
Consider fraud in financial services. Industry estimates suggest that only around 8% of fraud is actually reported. That means any organisation fixating on reported fraud metrics is studying the tip of an iceberg while congratulating themselves on their visibility. The dashboards look impressive. The trend lines might even be heading in the right direction. But you’re optimising for a shadow of reality.
The organisation that achieves genuine wisdom doesn’t ask “how much fraud was reported last quarter?” It asks questions like: “Who else paid money into accounts we now know were fraudulent but never reported it? What patterns preceded the fraud we caught, and where else do those patterns appear? What are we not seeing, and why?”
These questions are harder. They require linking disparate data sources, challenging comfortable assumptions, and accepting that your metrics have been lying to you. Not because anyone intended deception, but because the data only ever captured what was convenient to capture. The fraud that gets reported is the fraud that was easy to detect. The fraud that doesn’t get reported is, almost by definition, the sophisticated fraud you should actually be worried about.
5. The Illusion of Knowing Ourselves
Here’s where it gets uncomfortable. The data obsession isn’t just an organisational failure. It’s a mirror reflecting a deeper human delusion. We believe we are rational agents making deliberate, informed decisions. Neuroscience and behavioural economics have spent decades demolishing this comfortable fiction.
We are pattern matching machines running on heuristics, rationalising decisions we’ve already made unconsciously. We seek information that confirms what we already believe. We mistake correlation for causation. We see patterns in noise and miss signals in data. We are spectacularly bad at understanding our own motivations, biases, and blind spots.
This matters because organisations are collections of humans, and they inherit all our cognitive limitations while adding a few of their own. When an executive demands “more data” before making a decision, they’re often not seeking understanding. They’re seeking comfort. The data becomes a security blanket, a way to defer responsibility, a defence against future criticism. “The data told us to do it.”
But the data never tells us to do anything. We tell ourselves stories about what the data means, filtered through our assumptions, our incentives, and our fears. Without self knowledge, without understanding our own biases and limitations, more data simply gives us more raw material for self deception.
6. The Famine Amidst Plenty
We are living through a peculiar paradox: a famine of wisdom amidst a gluttony of data. We have more information than any civilisation in history and arguably less capacity to make sense of it. The problem isn’t access. It’s digestion.
Consider how we’ve changed the way we consume information. Twenty years ago, reading a book or a longform article was normal. Today, we scroll through endless feeds, consuming fragments, never staying with any idea long enough to truly understand it. We’ve optimised for breadth at the expense of depth, for novelty at the expense of comprehension, for reaction at the expense of reflection.
Organisations have mirrored this dysfunction. The average executive receives hundreds of emails daily, sits through back to back meetings, and is expected to make consequential decisions in the gaps between. They have access to realtime dashboards showing every conceivable metric, yet they lack the time and mental space to think deeply about any of them. The tyranny of the urgent crowds out the importance of the significant.
Wisdom requires time. It requires sitting with uncertainty. It requires the humility to admit what we don’t know and the patience to discover it properly. None of these things scale. None of them show up on a dashboard. None of them impress investors or boards.
7. What Organisations Should Actually Do
If data is indeed the new oil, then we need to think like refineries, not like hoarders. This means fundamental changes in how we approach information.
First, ruthlessly prioritise. Not all data deserves collection, storage, or analysis. The question isn’t “can we capture this?” but “does this help us make better decisions about things that actually matter?” Most organisations would benefit from capturing less data, not more, but capturing the right data with much greater intentionality.
Second, drain the swamp before building the lake. If you can’t trust your existing data, adding more won’t help. Invest in data quality, in clear ownership, in documentation that actually gets maintained. A small, clean, well understood dataset is infinitely more valuable than a vast murky swamp where nobody knows what’s true.
Third, invest in the refinement stages. For every pound spent on data infrastructure, organisations should be spending at least as much on the human capabilities to interpret it: skilled analysts, yes, but also domain experts who understand context, and experienced leaders who can exercise judgement. The bottleneck is rarely data. It’s the capacity to transform data into actionable understanding.
Fourth, build validation into everything. Assume your data is lying to you until proven otherwise. Cross reference. Sanity check. Ask “what would have to be true for this number to be correct?” and then verify those preconditions. Create a culture where questioning data is rewarded, not punished.
Fifth, ask the questions your data can’t answer. The most important insights often live in the gaps. What aren’t you measuring? What can’t you see? If only 8% of fraud is reported, what does the other 92% look like? These questions require imagination and domain expertise, not just better analytics.
Sixth, create space for reflection. Wisdom doesn’t emerge from realtime dashboards or daily standups. It emerges from stepping back, asking deeper questions, and allowing insights to crystallise over time. This is profoundly countercultural in most organisations, which reward visible activity over invisible thinking. But the most consequential decisions (strategy, culture, longterm investments) require exactly this kind of slow, deliberate cognition.
Seventh, institutionalise self awareness. This might sound soft, but it’s absolutely critical. Decisions made from a place of self knowledge, understanding why we want what we want, recognising our biases, acknowledging our blind spots, are categorically different from decisions made in ignorance of our own psychology. Build in mechanisms that surface assumptions, challenge groupthink, and create psychological safety for dissent.
Eighth, measure what matters. The easiest things to measure are rarely the most important. Clicks are easier to count than customer trust. Output is easier to measure than outcomes. Activity is easier to track than impact. The discipline of identifying what actually matters, and accepting that some of it may resist quantification, is essential to breaking free from data theatre.
8. Decisions From a Place of Knowing
The goal isn’t to reject data. That would be as foolish as rejecting evidence. The goal is to put data in its proper place: as one input among many, useful but not sufficient, informative but not determinative.
The best decisions I’ve witnessed, the ones that created genuine value, that navigated genuine uncertainty, that proved robust in the face of changing circumstances, didn’t come from better dashboards. They came from leaders who understood themselves well enough to know when they were rationalising versus reasoning, who had cultivated judgement through experience and reflection, and who treated data as a conversation partner rather than an oracle.
This kind of wisdom is slow to develop and impossible to automate. It requires exactly the kind of patient, deep work that our information saturated environment makes increasingly difficult. But it remains the essential ingredient that separates organisations that thrive from those that merely survive.
9. Conclusion: From Gluttony to Nourishment
Data is indeed the new oil. Which means it’s messy, it’s dangerous, and in its raw form, it’s nearly useless. It stinks. It requires enormous effort to extract. It demands sophisticated infrastructure and genuine expertise to refine. And like oil, its careless use creates pollution: in this case, pollution of our decisionmaking, our organisations, and our understanding of ourselves.
The organisations that will win the next decade aren’t the ones with the biggest data lakes, or swamps. They’re not the ones with the fanciest analytics platforms or the most impressive dashboards. They’re the ones that recognise the difference between information and understanding, between metrics and meaning, between data and wisdom.
They’ll be the organisations that ask hard questions about what their data isn’t showing them. That validate relentlessly rather than trust blindly. That understand tortured data will confess to anything and refuse to torture it. That recognise the embedded lies in their measurements and actively hunt for what they’re missing.
Most importantly, they’ll be organisations led by people who know themselves. Who understand their own biases, who can distinguish between reasoning and rationalising, who have the humility to admit uncertainty and the patience to sit with it. Because in the end, the quality of our decisions cannot exceed the quality of our self knowledge.
The famine won’t end by consuming more data. It will end when we learn to digest what we already have: slowly, carefully, wisely. When we stop mistaking the swamp for a lake, the noise for a signal, and the comfortable lie for the inconvenient truth.
The first step in that transformation is the hardest one of all: admitting that we don’t know nearly as much as we think we do. Not about our customers, not about our markets, and certainly not about ourselves.
The famine won’t end until we stop gorging and start digesting.
1. Technology Is an Infinite Game and That Is the Point
Technology has no finish line. There is no end state, no final architecture, no moment where you can stand back and declare victory and go home. It is an infinite game made up of a long sequence of hard fought battles, each one draining, each one expensive, each one slower than anyone would like. The moment you solve one problem, the context shifts and the solution becomes the next constraint.
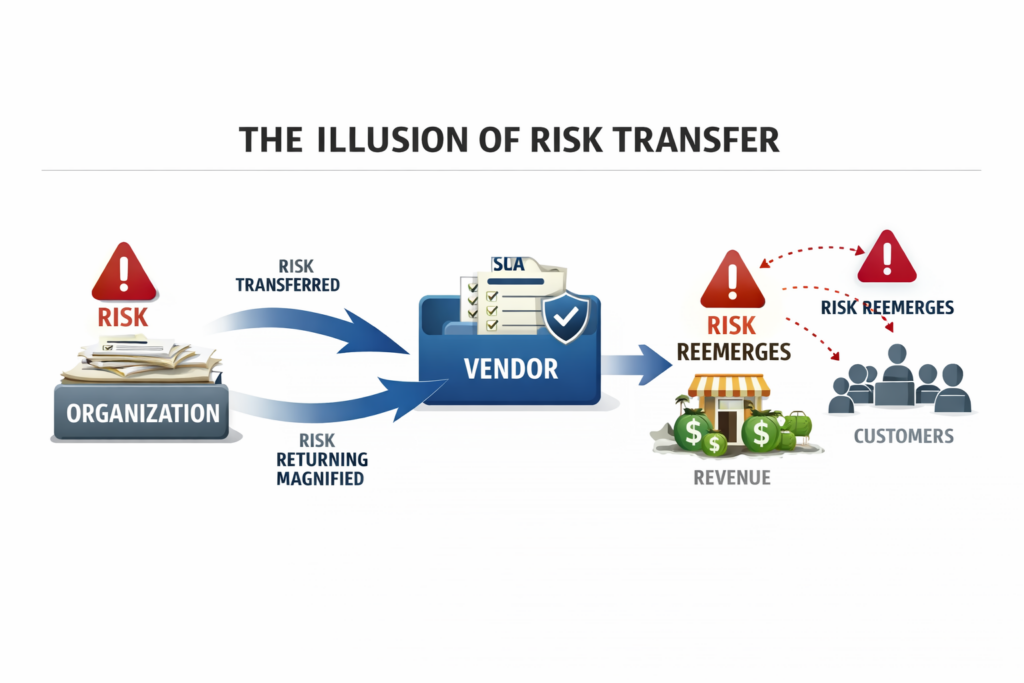
Everything feels too expensive, too difficult and too slow. Under that pressure, a familiar thought pattern emerges. If only we could transfer the risk to someone else. If only we could write enough SLAs, sharpen enough penalties and load the contract until gravity itself guarantees success. If only we could hire lawyers, run a massive outsourcing RFP and make the uncertainty go away.
This is the first lie of the infinite game. Risk does not disappear just because you have moved it onto someone else’s balance sheet. It simply comes back later with interest, usually at the worst possible time.
2. The Euphoria Phase and the Hangover That Follows
The outsourcing cycle always begins with euphoria. There is a media statement. Words like strategic and synergies are deployed liberally. Executive decks are filled with arrows pointing up and to the right. Contracts are signed. Photos are taken. Everyone congratulates each other on having made the hard decisions. Then reality arrives quietly.
Knowledge transfer begins and immediately reveals that much of what matters was never written down. Attrition starts to bite, first at the edges, then at the core. The people who actually understood why things were built the way they were begin to leave, often because they were treated as interchangeable delivery units rather than as the source of the IP itself.
You attempted to turn IP creation into the procurement of pencils. You specified outputs, measured compliance and assumed the essence of the work could be reduced to a checklist. What you actually outsourced was your ability to adapt.
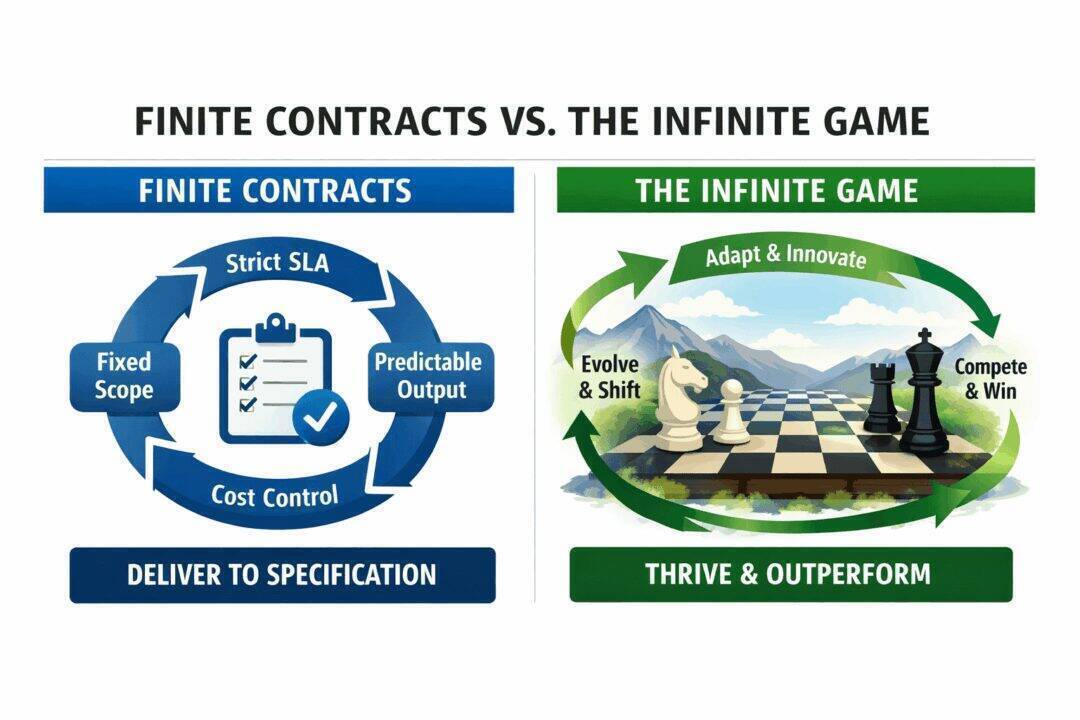
3. Finite Contracts Versus Infinite Competition
Outsourcing is fundamentally a finite game. It is about grinding every last cent out of a well defined specification. It is about predictability, cost control and contractual certainty. Those are not bad things in isolation. Competition, however, is infinite.
You are not playing to complete a statement of work. You are playing on a chessboard with an infinite number of possible moves, where the only goal is to win. To be better than the competition. To innovate faster than they do. To thrive in an environment that changes daily.
The absurdity of this mismatch is often visible in the contracts themselves. Somewhere deep in the appendices you will find a line item for innovation spend, because the board asked for it. As if innovation can be pre purchased, time boxed and invoiced monthly. Innovation is not a deliverable. It is an outcome of ownership, proximity and deep understanding.
4. When Outsourcing Actually Works
Outsourcing does work, but only under very specific conditions. It works when the thing you are outsourcing is not mission critical. When it is a side show. When failure is survivable and learning is optional.
Payroll systems, commodity infrastructure, clearly bounded operational tasks can often be externalised safely. The moment the outsourced capability becomes core to differentiation, speed or revenue generation, the model starts to collapse under its own weight.
The more central the capability is to winning the infinite game, the more dangerous it is to distance yourself from it.
5. Frameworks as a Way Down the Complexity Food Chain
There is a more subtle version of the same instinct, and it shows up in the overuse of vendor frameworks. Platforms like Salesforce allow you to express your IP in a controlled and well defined way. You are deliberately moving yourself down the complexity food chain. Things become easier to reason about, easier to hire for and easier to operate.
There is nothing inherently wrong with this. In many cases it is a rational trade off.
The danger appears when this pattern is applied indiscriminately. When every problem is forced into a vendor shaped abstraction. When flexibility is traded for integration points until you find yourself wrapped in a beautifully integrated set of shackles. Each individual decision looked sensible. The aggregate outcome is paralysis.
You did not remove complexity. You just externalised it and made it harder to escape.
6. No Strategic End State Exists
Technology strategy does not converge. There is no strategic end state. Looking for one is like looking for a strategic newspaper. It changes every day.
Mortgaging today to pay for a hypothetical tomorrow is how organisations lose their ability to move. Long term plans that require years of faith before any value is delivered are a luxury few businesses can afford. Try to operate with a tiny balance sheet. Keep commitments short. Keep feedback loops tight.
Whatever you do, do it efficiently and quickly. Get it to production. Make money from it. Learning that does not touch reality is just theory.
Anyone who walks into the room with a five year roadmap before delivering anything meaningful should be sent back out of it. Some things genuinely do take time, but sustainable businesses run on a varied delivery diet. Small wins, medium bets and the occasional long horizon investment, all running in parallel.
7. The Cost of Playing the Infinite Game
Technology is hard. It always has been. It demands stamina, humility and a tolerance for discomfort. There are no permanent victories, only temporary advantages. The frustration you feel is not a sign of failure. It is the admission price for playing an infinite game.
You do not win by outsourcing the game itself. You win by staying close to the work, owning the risk and being willing to fight the next battle with clear eyes and minimal baggage.
8. The Question Nobody Wants to Ask About Outsourcing
There is a question that almost never gets asked out loud, despite how obvious it is once you say it. How many companies that specialise in outsourcing actually lose money? The answer is vanishingly few. They are very good at what they do. Much better than you.
They have better lawyers than you. They have refined their contracts, their commercial models and their delivery mechanics over decades. They will kill you softly with their way of working. With planning artefacts that look impressive but slow everything down. With invoicing structures that extract value for every ambiguity. With change requests for things you implicitly assumed were included, but were never explicitly written down.
They do not know what your business truly wants or needs, and more importantly, they do not care. They are not misaligned out of malice, they are misaligned by design. Their incentives are not your incentives. Their goal is not to win your market, delight your customers or protect your brand. Their goal is to run a profitable outsourcing business.
They will absolutely cut your costs, at least initially. Headcount numbers go down. Unit costs look better. The spreadsheet tells a comforting story and everyone relaxes. For a while, it feels like the right decision.
Then, slowly, the cracks begin to appear.
Velocity drops. Small changes become negotiations. Workarounds replace understanding. You realise that decisions are being optimised for contractual safety rather than business outcomes. Innovation dries up, except for what can be safely branded as innovation without threatening the delivery model.
By the time this becomes visible to leadership, you are already in trouble. You have missed out on years of engagement, learning and organic innovation. The people who cared deeply about your systems and customers are gone. What remains is a brittle, over constrained estate that nobody fully understands, including the people being paid to run it.
You now have a basket case to fix, under pressure, with fewer options than before. The short term cost savings have been repaid many times over in lost opportunity, lost capability and lost time. This is not a failure of execution. It is the predictable outcome of trying to play an infinite game using finite tools.
9. Conclusion: Embrace the Reality of the Infinite Game
In the end, the frustration we feel with technology, the slowness, cost, complexity, risk, and the urge to outsource it all, is a symptom of a deeper mismatch between the type of game we are playing and the mindset we bring to it. In business and technology there is no final victory, no stable “end-state” where we can declare ourselves done and walk away. We are participating in an infinite game — one where the objective isn’t to “win once” but to remain in the game, continuously adapting, learning, and advancing.
Finite tools like contracts, SLAs, RFPs, tightly bounded outsourcing arrangements, are not evil in themselves. They work well inside a finite context where boundaries, rules and outcomes are clear. But when we try to impose them onto something that has no finish line, we almost guarantee friction, misalignment, and eventual stagnation. The irony is that in trying to control uncertainty, we inadvertently kill the very flexibility and innovation that keep us relevant.
The real lesson is not to avoid complexity, but to embrace the infinite nature of what we’re doing. Technology isn’t a project you finish, it’s a landscape you navigate. Outsourcing may shift certain operational burdens, but it doesn’t transfer the necessity to learn, to iterate, to confront ambiguity, or to sustain competitive advantage. Those remain firmly in your hands.
So if there is a single strategic takeaway, it is this:
Stop looking for an end. Start building a rhythm. Deliver value early. Learn fast. And keep forging ahead.
That is how you thrive not just in technology, but in any domain where the game has no end.
Disaster recovery is one of the most comforting practices in enterprise technology and one of the least honest. Organisations spend significant time and money designing DR strategies, running carefully choreographed exercises, producing polished post exercise reports, and reassuring themselves that they are prepared for major outages. The problem is not intent. The problem is that most DR exercises are optimised to demonstrate control and preparedness in artificial conditions, while real failures are chaotic, asymmetric and hostile to planning. When outages occur under real load, the assumptions underpinning these exercises fail almost immediately.
What most organisations call disaster recovery is closer to rehearsal than resilience. It tests whether people can follow a script, whether environments can be brought online when nothing else is going wrong, and whether senior stakeholders can be reassured. It does not test whether systems can survive reality.
1. DR Exercises Validate Planning Discipline, Not Failure Behaviour
Traditional DR exercises are run like projects. They are planned well in advance, aligned to change freezes, coordinated across teams, and executed when everyone knows exactly what is supposed to happen. This alone invalidates most of the conclusions drawn from them. Real outages are not announced, they do not arrive at convenient times, and they rarely fail cleanly. They emerge as partial failures, ambiguous symptoms and cascading side effects. Alerts contradict each other, dashboards lag reality, and engineers are forced to reason under pressure with incomplete information.
A recovery strategy that depends on precise sequencing, complete information and the availability of specific individuals is fragile by definition. The more a DR exercise depends on human coordination to succeed, the less likely it is to work when humans are stressed, unavailable or wrong. Resilience is not something that can be planned into existence through documentation. It is an emergent property of systems that behave safely when things go wrong without requiring perfect execution.
2. Recovery Is Almost Always Tested in the Absence of Load
Figure 2: Recovery Under Load With and Without Chaos Testing
The single most damaging flaw in DR testing is that it is almost always performed when systems are idle. Queues are empty, clients are disconnected, traffic is suppressed, and downstream systems are healthy. This creates a deeply misleading picture of recoverability. In real outages, load does not disappear. It concentrates. Clients retry, SDKs back off and then retry again, load balancers redistribute traffic aggressively, queues accumulate messages faster than they can be drained, and databases slow down at precisely the moment demand spikes.
Back pressure and integration dependencies are the defining characteristic of real recovery scenarios, and it is almost entirely absent from DR exercises. A system that starts cleanly with no load and all its dependencies ready for traffic, may never become healthy when forced to recover while saturated and partially integrated. Recovery logic that looks correct in isolation frequently collapses when subjected to retry storms and backlog replays. Testing recovery without load is equivalent to testing a fire escape in an empty building and declaring it safe.
3. Recovery Commonly Triggers the Second Outage
DR plans tend to assume orderly reconnection. Services are expected to come back online, accept traffic gradually, and stabilise. Reality delivers the opposite. When systems reappear, clients reconnect simultaneously, message brokers attempt to drain entire backlogs at once, caches stampede databases, authentication systems spike, and internal rate limits are exceeded by internal callers rather than external users.
This thundering herd effect means that recovery itself often becomes the second outage, frequently worse than the first. Systems may technically be up while remaining unusable because they are overwhelmed the moment they re enter service. DR exercises rarely expose this behaviour because load is deliberately suppressed, leading organisations to confuse clean startup with safe recovery.
4. Why Real World DR Testing Is So Hard
The uncomfortable truth is that most organizations avoid real world DR testing not because they are lazy or incompetent, but because the technology they run makes realistic testing commercially irrational.
In traditional enterprise estates a genuine failover is not a minor operational event. A large SQL Server estate or a mainframe environment routinely takes well over an hour to fail over cleanly, and that is assuming everything behaves exactly as designed. During that window queues back up, batch windows are missed, downstream systems time out, and customers feel the impact immediately. Pulling the pin on a system like this during peak volumes is not a test, it is a deliberate business outage. No executive will approve that, and nor should they.
This creates an inevitable compromise. DR tests are scheduled during low load periods, often weekends or nights, precisely when the system behaves best. The back pressure that exists during real trading hours is absent. Cache warm up effects are invisible. Connection storms never happen. Latent data consistency problems remain hidden. The test passes, confidence is reported upward, and nothing meaningful has actually been proven.
The core issue is not testing discipline, it is recovery time characteristics. If your recovery time objective is measured in hours, then every real test carries a material business risk. As a result, organizations rationally choose theater over truth.
Change the technology and the equation changes completely. Platforms like Aurora Serverless fundamentally alter the cost of failure. A failover becomes an operational blip measured in seconds rather than an existential event measured in hours. Endpoints are reattached, capacity is rehydrated automatically, and traffic resumes quickly enough that controlled testing becomes possible even with real workloads. Once confidence is built at lower volumes, the same mechanism can be exercised progressively closer to peak without taking the business hostage.
This is the key distinction most DR conversations miss. You cannot meaningfully test DR if the act of testing is itself catastrophic. Modern architectures that fail fast and recover fast are not just operationally elegant, they are the only ones that make honest DR validation feasible. Everything else optimizes for paperwork, not resilience.
5. Availability Is Tested While Correctness Is Ignored
Most DR exercises optimise for availability signals rather than correctness. They focus on whether systems start, endpoints respond and dashboards turn green, while ignoring whether the system is still “right”. Modern architectures are asynchronous, distributed and event driven. Outages cut through workflows mid execution. Transactions may be partially applied, events may be published but never consumed, compensating actions may not run, and side effects may occur without corresponding state changes.
DR testing almost never validates whether business invariants still hold after recovery. It rarely checks for duplicated actions, missing compensations or widened consistency windows. Availability without correctness is not resilience. It is simply data corruption delivered faster.
6. Idempotency Is Assumed Rather Than Proven
Many systems claim idempotency at an architectural level, but real implementations are usually only partially idempotent. Idempotency keys are often scoped incorrectly, deduplication windows expire too quickly, global uniqueness is not enforced, and side effects are not adequately guarded. External integrations frequently replay blindly, amplifying the problem.
Outages expose these weaknesses because retries occur across multiple layers simultaneously. Messages are delivered more than once, requests are replayed long after original context has been lost, and systems are forced to process duplicates at scale. DR exercises rarely test this behaviour under load. They validate that systems start, not that they behave safely when flooded with replays. Idempotency that only works in steady state is not idempotency. It is an assumption waiting to fail.
7. DNS and Replication Lag Are Treated as Minor Details
DNS based failover is a common component of DR strategies because it looks clean and simple on diagrams. In practice it is unreliable and unpredictable. TTLs are not respected uniformly, client side caches persist far longer than expected, mobile networks are extremely sticky, corporate resolvers behave inconsistently, and CDN propagation is neither instantaneous nor symmetrical.
During real incidents, traffic often arrives from both old and new locations for extended periods. Systems must tolerate split traffic and asymmetric routing rather than assuming clean cutover. DR exercises that expect DNS to behave deterministically are rehearsing a scenario that almost never occurs in production.
8. Hidden Coupling Between Domains Undermines Recovery
Most large scale recovery failures are not caused by the system being recovered, but by something it depends on. Shared authentication services, centralised configuration systems, common message brokers, logging pipelines and global rate limits quietly undermine isolation. During DR exercises these couplings remain invisible because everything is brought up together in a controlled order. In real outages, dependencies fail independently, partially and out of sequence.
True resilience requires domain isolation with explicitly bounded blast radius. If recovery of one system depends on the health of multiple others, none of which are isolated, then recovery is fragile regardless of how well rehearsed it is.
9. Human Factors Are Removed From the Equation
DR exercises assume ideal human conditions. The right people are available, everyone knows it is a test, stress levels are low, and communication is structured and calm. Real incidents are defined by the opposite conditions. People are tired, unavailable or already overloaded, context is missing, and decisions are made under extreme cognitive load.
Systems that require heroics to recover are not resilient. They are brittle. Good systems assume humans will be late, distracted and wrong, and still recover safely.
10. DR Is Designed for Audit Cycles, Not Continuous Failure
Most DR programs exist to satisfy auditors, regulators and risk committees rather than to survive reality. This leads to annual exercises, static runbooks, binary success metrics and a complete absence of continuous feedback. Meanwhile production systems change daily.
A DR plan that is not continuously exercised against live systems is obsolete by default. The confidence it provides is inversely proportional to its accuracy.
11. Chaos Testing Is the Only Honest Substitute
Real resilience is built by failing systems while they are doing real work. That means killing instances under load, partitioning networks unpredictably, breaking dependencies intentionally, injecting latency and observing the blast radius honestly. Chaos testing exposes retry amplification, back pressure collapse, hidden coupling and unsafe assumptions that scripted DR exercises systematically hide.
It is uncomfortable and politically difficult, but it is the only approach that resembles reality. Fortunately, some of the risk of chaos testing can be replicated in a UAT environment. But this requires investment and commitment from senior leaders that understand the value of these kinds of tests. Additionally, actual production outages can be reviewed forensically to essentially give you a “free lesson”, if you have invested in accurate monitoring and take the time to review all production failures.
12. What Systems Should Actually Be Proven To Do
A meaningful resilience strategy does not ask whether systems can be recovered quietly. It proves, continuously, that systems can recover under sustained load, tolerate duplication safely, remain isolated from unrelated domains, degrade gracefully, preserve business invariants and recover with minimal human coordination even when failure timing and scope are unpredictable.
Anything less is optimism masquerading as engineering.
13. The Symmetrical Failure
One of the most dangerous and least discussed failure modes in modern systems is what can be described as a symmetrical failure. It is dangerous precisely because it is fast, silent, and often irreversible by the time anyone realises what has happened.
Imagine a table being accidentally dropped from a production database. In an environment using synchronous replication, near synchronous replication, or block level storage replication, that change is propagated almost immediately to the disaster recovery environment. Within seconds, both production and DR contain the same fault. The table is gone everywhere. At that point DR is not degraded or partially useful. It is completely useless.
This is the defining characteristic of a symmetrical failure. The failure is faithfully replicated across every environment. Replication does not discriminate between correct state and incorrect state. It simply copies bytes. From the outside, everything still looks healthy. Replication is green. Storage is in sync. Latency is low. And yet the system has converged perfectly on a broken outcome.
This class of failure is not limited to dropped tables. Any form of logical corruption that is replicated at the physical or block layer will be propagated without validation. Index corruption, application bugs that write bad data, schema changes gone wrong, runaway batch jobs, or subtle data poisoning all behave the same way. Organisations relying heavily on block level replication often underestimate this risk because the tooling frames faster replication as increased safety. In reality, faster replication often increases the blast radius.
Some symmetrical failures can be rolled back quickly. A small table dropped and detected immediately might be recoverable from backups within an acceptable window. Others are far more intrusive. Large tables, high churn datasets, or corruption detected hours or days later can push recovery times far beyond any realistic business RTO. At that point the discussion is no longer about disaster recovery maturity, but about how long the business can survive without the system.
These failure events must be explicitly designed for, with a fixation on recovery time objectives rather than recovery point objectives alone. RPO answers how much data you might lose. RTO determines whether the business survives the incident. To achieve meaningful RTOs, organisations may need to impose constraints such as maximum database sizes, maximum table sizes, stricter data isolation, or delayed and logically validated replicas. In many cases, achieving the required RTO means changing the architecture rather than tuning the existing one.
If you want resilience, you have to accept that it will not emerge from faster replication or more frequent DR tests. It emerges from designing systems that can tolerate mistakes, corruption, and human error without collapsing instantly.
14. Conclusion
Most disaster recovery exercises do not fail because teams are incompetent. They fail because they test the wrong thing. They validate restart in calm conditions, without load, pressure or ambiguity. That proves very little about how systems and organisations behave when reality intervenes.
Traditional DR misses entire classes of failure including symmetrical failures, silent corruption, hidden coupling, governance paralysis and human breakdown under stress. A DR environment that faithfully mirrors production is only useful if production is still correct and if the organisation can act decisively when it is not.
The next question leaders inevitably ask is, “what is this going to cost?” The uncomfortable but honest answer is that if resilience is done properly, it is not a project or a line item. It is a lifestyle choice. It becomes embedded in how the organisation thinks about architecture, limits, failure and recovery. It shapes design decisions long before incidents occur.
In many cases, other than time and focus, there is little direct investment required. In fact, resilience work often reduces costs. That monolithic 100 terabyte database that runs your entire organisation and requires specialised hardware, specialised skills and multi hour recovery windows is usually a design failure, not a necessity. When it goes on a diet, recovery times collapse. Hardware requirements shrink. Operational complexity drops.
More importantly, resilient designs often introduce stand in capabilities. Caches, queues, read only replicas and degraded modes allow the business to continue processing transactions while recovery is underway. The organisation does not stop simply because the primary system is being repaired. Recovery becomes a background activity rather than a full stop event.
True resilience is not achieved through bigger DR budgets or more elaborate exercises. It is achieved by changing how systems are designed, how limits are enforced and how failure is expected and absorbed. If your recovery strategy only works when everything goes to plan, it is not resilience. It is optimism masquerading as engineering.
Organisations like to believe they reward outcomes. In reality, they reward visibility. This is the essence of the Last Mile Fallacy: the mistaken belief that the final visible step in a chain of work is where most of the value was created. We tip the waiter rather than the chef, praise the presenter rather than the people who built the system, and congratulate the messenger rather than the makers. The last mile feels real because it has a face, a voice, and a narrative that fits neatly into a meeting. The earlier miles are quieter, messier, and far harder to explain, so they are systematically undervalued.
2. Why the Last Mile Feels Like the Work
In a restaurant, tipping the waiter makes emotional sense. The waiter is the person we interact with, the person who absorbs our frustration and responds to our gratitude. But this social convention quietly becomes a value model inside organisations. The kitchen created the asset through skill, preparation, and repeated invisible decisions, yet the reward follows the interaction rather than the creation. Over time, companies internalise this logic and begin to believe that delivery, reporting, and presence are the work, rather than the final expression of it.
3. How This Manifests in Technology Organisations
In technology teams, the “waiter” is often the person reporting progress. They attend the meetings, translate uncertainty into status updates, and turn complex engineering realities into something consumable. When detailed questions arise, the response is often that they are not close to the detail and will check with the team, yet the recognition and perceived ownership remain firmly with them. This is rarely malicious. It is structural. The system rewards those who can package work, not those who quietly do it.
4. Where Engineering Value Is Actually Created
Most engineering value is created long before anything becomes visible. It appears in design tradeoffs that avoid future failure, in performance headroom that only matters on the worst day, and in risks retired early enough that no one ever knows they existed. Great engineering is often deliberately invisible. When systems work, there is nothing to point at. This creates a fundamental mismatch: great engineering does not naturally market itself, and engineers are rarely motivated to try.
5. Great Engineering Is Not Great Marketing
Engineers are intrinsically poor at being seen and heard, not because they lack confidence or capability, but because their incentives are different. Precision matters more than persuasion. Acknowledging uncertainty is a strength, not a weakness. Over claiming feels dishonest, and time spent talking is time not spent fixing the problem. What looks like poor communication from the outside is often professional integrity on the inside. Expecting engineers to compensate for this by becoming self marketers misunderstands both the role and the culture.
6. Psychological Safety and the Broker Layer
Because it is often unsafe to speak openly, information rarely flows directly from engineers to senior leadership. Saying that a deadline is fictional, that a design is fragile, or that a system is one person away from failure carries real career risk. As a result, organisations evolve a broker layer that filters, softens, and sanitises reality before it travels upward. Leadership frequently mistakes this calm, polished narrative for control, when in fact it is distance. The truth still exists, but it has been made comfortable.
7. A Legitimate Counter Argument: When Work Really Is a Commodity
There are domains where the Last Mile Fallacy is less of a fallacy and more of an economic reality. Construction is a useful example. Laying bricks is physically demanding, highly skilled work, yet bricklayers are often interchangeable. The intellectual property of the building exists before the first brick is laid. The architect, engineer, and planner have already made the critical decisions. The bricklayer is executing a predefined plan, acting on instructions rather than solving open ended problems. In this context, replacing the individual doing the work does not meaningfully alter the outcome, because the value was created upstream and encoded into the design.
8. Why Software Engineering Is Fundamentally Different
Software engineering does not work this way. The value does not sit fully formed before execution begins. Engineers are not simply following instructions; they are continuously solving problems, making trade offs, and adapting to constraints in real time. You are not paying for keystrokes or lines of code. You are paying for judgment, efficiency, and the ability to reach a desired outcome under uncertainty. Two engineers given the same requirements will produce radically different systems in terms of performance, resilience, cost, and long term maintainability. The intellectual property is created during the work, not before it.
9. Presence Without Proximity
This distinction makes the organisational behaviour even more ironic. Many organisations demand a return to the office in the name of proximity, collaboration, and culture, yet senior leaders rarely leave their own rooms, floors, or meeting cycles to engage directly with the teams doing this problem solving work. Call centres remain unvisited, engineering floors remain symbolic, and frontline reality is discussed rather than observed. The distance remains intact, even as the optics change.
10. Key Man Risk Is Consistently Misplaced
Ask where key man risk sits and many organisations will point to programme leads or senior managers. In reality, the risk sits with the engineer who understands the legacy edge case, the operator who knows which alert lies, or the developer who fixed the outage at two in the morning. These people are not interchangeable because the intellectual property lives in their decisions and experience. When they leave, knowledge evaporates. When brokers leave, slides are rewritten.
11. Leadership’s Actual Responsibility
In an engineering led organisation, leadership is not there to extract updates or admire dashboards. Leadership exists to go to the work, to create enough psychological safety that people can speak honestly, and to translate engineering reality into organisational decisions. Engineers should not be forced to become marketers in order to be heard. Leaders must do the harder work of listening, observing, and engaging deeply enough that truth can surface without fear.
12. Escaping the Last Mile Fallacy (Practical Ways Out)
Escaping the Last Mile Fallacy is not about better reporting, slicker decks, or more polished narratives. It is about deliberately collapsing the distance between those who create value and those who make decisions. That distance is organisational, cultural, and often emotional. Closing it requires intent, tolerance, and leadership courage.
12.1 Let the Makers Give the Demos
Wherever possible, the people who wrote the software should give the demos, even when the audience is Exco or the board. This will feel uncomfortable at first. Engineers may give answers that are technically honest but politically naive. That is not a failure; it is a signal that reality is finally present in the room.
If leadership cannot tolerate imperfect phrasing in exchange for truth, the organisation will always optimise for storytelling over substance. Supporting these presenters publicly is critical. The moment someone is punished or undermined for honest technical communication, the organisation snaps back into theatre mode.
12.2 Reward Truth Early, Not Just Delivery at the End
Organisations say they want transparency, but often only reward success narratives. Escaping the fallacy requires explicitly rewarding early truth, especially when that truth is inconvenient.
When engineers raise concerns about scope, complexity, architectural debt, or timelines early, that should increase trust, not decrease it. Leaders must model this by responding with curiosity rather than defensiveness. If bad news is only safe once it is irreversible, the last mile will always lie.
12.3 Train Leadership to Appreciate How Hard Value Is to Deliver
Many leadership decisions are made without any lived appreciation of how difficult modern software delivery actually is. This is not a moral failing, but it is a structural one.
Leadership development should include exposure to real delivery work: shadowing teams, walking through systems, understanding tradeoffs, and seeing the invisible labour involved in keeping systems stable while they evolve. Without this context, expectations will always skew optimistic and attribution will always drift upward.
12.4 Institutionalise Skip Level Engagement
Skip level engagement should not be treated as an exceptional event or a crisis intervention. It should be normalised as a healthy organisational reflex.
Leaders should regularly reach into the organisation and speak directly with staff at all levels, with layers of management present but not filtering the interaction. The goal is not to bypass managers, but to remove information distortion. Real understanding does not survive too many translations.
12.5 Give Exco Direct Access to Engineers and Their Work
Executive teams should have access to sessions where they can talk directly to engineers, see what they are working on, and ask questions without intermediaries. These are not status updates. They are learning sessions.
When leaders take a genuine interest in the work, engineers feel seen, complexity becomes visible, and decisions improve. When leaders rely exclusively on summaries, the last mile becomes the only voice that matters.
12.6 Treat Asking Dumb Questions as a Leadership Responsibility
If you are privileged to be a leader, you must make your peace with asking questions that feel dumb. The alternative is pretending to understand while making decisions in the dark.
Asking naive questions is not a weakness. It is how leaders escape the prison of curated narratives. It signals humility, invites clarity, and creates space for real dialogue. Leaders who only ask impressive questions are usually optimising for image, not understanding.
12.7 Create Senior Technical Career Paths That Do Not Force Management
One of the most subtle drivers of the Last Mile Fallacy is the way organisations structure career progression. In many companies, engineers eventually hit a ceiling in individual contributor roles and are forced to convert into managers to progress, gain status, or earn more. This is a mistake.
Senior designations such as Staff Engineer, Principal Engineer, and Distinguished Engineer create a parallel path that allows exceptional contributors to remain close to the work. These roles recognise impact through technical leadership, system stewardship, mentoring, and architectural judgement rather than headcount ownership.
Crucially, these roles must be financially and socially equivalent to management tracks. If technical leadership is treated as a consolation prize, the organisation will still drain its best engineers away from real work and into coordination roles they may not want or be good at.
Clear contributor career paths reduce the pressure to perform value through visibility. They keep expertise where it matters most and ensure that the people shaping the systems are the people who deeply understand them.
12.8 Shift Recognition from Visibility to Impact
Finally, organisations must consciously shift what they recognise and reward. Airtime, presentation polish, and narrative control are poor proxies for value creation.
Recognition systems should elevate impact, craft, resilience, and problem solving, even when that work is invisible or unglamorous. Until incentives change, behaviour will not. The last mile will always attract disproportionate credit because the system is designed that way.
Organisations that escape the Last Mile Fallacy do not do so accidentally. They redesign how leadership engages with work, how truth flows, and how value is recognised. Leaders go to the work, rather than waiting for the work to come to them.
13. Conclusion
Software engineering is not bricklaying. It is creative, judgement heavy problem solving carried out under uncertainty, over time, and across layers of invisible complexity. When organisations treat it as a commodity that can be fully represented through slides and summaries, they fundamentally misunderstand where value is created and where risk accumulates.
The Last Mile Fallacy persists not because leaders are malicious, but because distance is convenient. It is easier to consume narratives than to engage with reality. It is easier to reward visibility than to understand contribution. But that convenience comes at a cost: poor decisions, frustrated teams, and organisations that slowly lose their ability to execute.
Escaping the fallacy is therefore not an intellectual exercise. It is a leadership practice. It requires humility, presence, and a willingness to sit with discomfort. It requires leaders to ask questions that expose what they do not know, to listen to people who are not polished communicators, and to value truth over theatre.
If you are privileged to lead, your job is not to be protected from complexity. Your job is to engage with it. Go to the demos. Sit with the engineers. Ask the dumb questions. Collapse the distance.
Because the closer leadership is to real work, the harder it becomes to confuse motion with progress, and the easier it becomes to recognise where value is actually created.