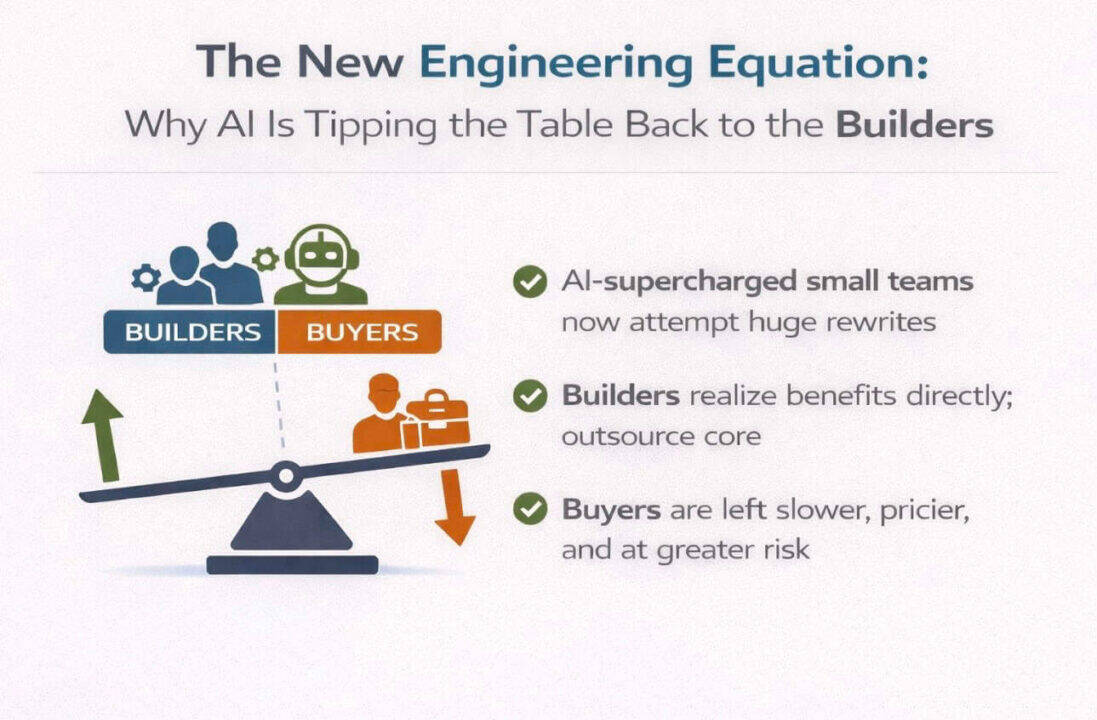
When a $3 API call can replace a $165 per user per month platform, the financial mathematics of enterprise software fundamentally change.
1. The New Economics of Customer Engagement
Something fundamental shifted in 2024. The capabilities that once justified six and seven figure enterprise software contracts became commoditised overnight. Not gradually, through slow competitive erosion, but suddenly, through the democratisation of large language models.
Consider the financial proposition Salesforce has historically offered: pay $165 per user per month for Enterprise Edition, plus implementation costs ranging from $50,000 to $500,000, plus annual maintenance at 20% of license fees, plus consultant rates of $150 to $300 per hour for customisation. The total cost of ownership for a 100 seat deployment easily exceeds $500,000 in year one alone.
Now consider the alternative: Claude’s Sonnet 4.5 at $3 per million input tokens and $15 per million output tokens. A sophisticated customer service interaction involving 2,000 tokens costs approximately $0.03. Even accounting for web search, RAG infrastructure, and generous conversation lengths, a single customer interaction rarely exceeds $0.15 in API costs.
The mathematics are stark. Salesforce’s Agentforce charges $2 per conversation at the base rate. Direct API integration with Claude or GPT costs roughly 1% of that figure for equivalent functionality.
2. Agentforce Under Financial Scrutiny
Salesforce’s response to the AI revolution has been Agentforce, announced at Dreamforce 2024 with considerable fanfare. Marc Benioff called it “the third wave of AI” and declared it would be the company’s singular focus. The initial pricing of $2 per conversation drew immediate criticism for being unpredictable and expensive for mid sized businesses.
The financial reality of Agentforce reveals several uncomfortable truths:
The Conversation Tax: At $2 per conversation, a call centre handling 10,000 daily interactions faces $600,000 in annual Agentforce costs before touching base licensing. The May 2025 introduction of Flex Credits at $0.10 per action provides marginal relief, but compound usage across complex workflows still accumulates rapidly.
The Platform Prerequisite: Agentforce requires Salesforce Enterprise Edition as a foundation, meaning the $165 per user per month floor remains non negotiable. Add the Agentforce add on at $125 per user per month and you’re looking at $290 per user per month before your first AI interaction.
The Hidden Consumption Layer: Even with Flex Credits, organisations face Einstein Request charges for non Agentforce prompts, Data Cloud credits for customer data unification, and separate LLM provider fees if bringing their own models. Multiple billing streams make total cost projection notoriously difficult.
Contrast this with direct LLM integration: A well architected system using Claude directly requires only API costs proportional to actual usage. There are no per seat minimums, no platform prerequisites, no complex credit systems. The billing is a single line item that scales linearly with business value delivered.
3. Deconstructing the Salesforce Stack
Let us examine each major Salesforce component and evaluate whether modern alternatives can replace them for typical call centre operations:
Customer Relationship Management (CRM)
Salesforce cost: $165 per user per month (Enterprise)
Open source alternative: SuiteCRM, Twenty CRM, or EspoCRM at $0 self hosted
SuiteCRM emerged from the SugarCRM community fork and now offers enterprise grade contact management, sales pipelines, case management, and reporting. Twenty CRM provides a modern, developer friendly alternative with full data ownership. Both integrate via standard REST APIs with any LLM orchestration layer.
Verdict: Replaceable for most mid market requirements.
Contact Centre Telephony
Salesforce cost: Service Cloud Voice at $100+ per user per month
Open source alternative: Asterisk, FreePBX, or 3CX
FreePBX provides IVR, call routing, queue management, and call recording with CRM integration capabilities. VICIdial offers predictive dialing for outbound operations. Modern WebRTC implementations enable browser based softphones without proprietary infrastructure.
Verdict: Fully replaceable with significant cost reduction.
AI Powered Customer Service
Salesforce cost: Agentforce at $2 per conversation or $0.10 per action
Direct alternative: Claude API at $0.03 per typical interaction
The core claim for Agentforce is its Atlas Reasoning Engine and tight CRM integration. But RAG (Retrieval Augmented Generation) is not proprietary technology. Any competent engineering team can implement vector search against customer data and orchestrate LLM calls with tool use. LangChain, LlamaIndex, and dozens of frameworks provide production ready scaffolding.
Verdict: Significantly cheaper via direct integration.
Workflow Automation
Salesforce cost: Included in Enterprise but limited; advanced features require additional licensing
Open source alternative: n8n, Temporal, or Apache Airflow
n8n provides visual workflow automation with over 400 integrations. Temporal handles complex, long running workflows with built in retry logic. Both can orchestrate LLM calls, database operations, and third party API interactions.
Verdict: Replaceable with greater flexibility.
Knowledge Management
Salesforce cost: Knowledge add on licensing
Open source alternative: Wiki.js, BookStack, or custom RAG implementation
A PostgreSQL database with pgvector extension provides semantic search over knowledge articles. Combined with an LLM for answer synthesis, this replicates Salesforce Knowledge functionality at infrastructure cost only.
Verdict: Trivially replaceable.
Analytics and Reporting
Salesforce cost: CRM Analytics at $140 per user per month
Open source alternative: Metabase, Apache Superset, or Grafana
Metabase offers self service business intelligence with SQL support and visualisation. Modern organisations increasingly prefer these tools for their flexibility and cost structure.
Verdict: Superior alternatives available at lower cost.
4. Service Cloud: The $330 Per Month Question
Service Cloud represents Salesforce’s core contact centre offering, and it deserves particular scrutiny for call centre operations. The pricing structure reveals the full extent of the enterprise software extraction model.
The Pricing Ladder
Service Cloud pricing scales aggressively with capability requirements:
The Starter Suite begins at $25 per user per month, offering basic case management and email support. This entry point appears reasonable until you discover its limitations: no workflow automation, no self service portals, no meaningful AI features.
The Pro Suite at $100 per user per month adds automation capabilities, but organisations quickly discover that serious contact centre operations require Enterprise Edition at $165 per user per month. This tier unlocks self service help centres, advanced case management, work order management, and the Web Services API necessary for meaningful integration.
The Unlimited tier at $330 per user per month introduces 24/7 support, AI powered chatbots, and the Premier Success Plan. For organisations wanting Agentforce capabilities integrated with Service Cloud, the Agentforce 1 Service edition climbs to $550 per user per month.
What You Actually Get
Service Cloud’s core value proposition centres on case management, omnichannel routing, and knowledge base integration. These are genuinely useful capabilities, but none represents rocket science:
Case Management: A ticketing system with assignment rules, escalation paths, and SLA tracking. Open source alternatives like osTicket, Zammad, or even a well designed PostgreSQL schema with n8n workflows provide equivalent functionality.
Omnichannel Routing: Intelligent distribution of work items across available agents. Amazon Connect, Twilio Flex, and numerous open source contact centre platforms handle this competently.
Knowledge Base: Searchable repository of support articles. Any CMS with decent search, or a purpose built RAG implementation over a vector database, replicates this capability at negligible marginal cost.
The Service Console, Salesforce’s agent desktop interface, admittedly provides a polished experience. But React and modern frontend frameworks enable equivalent interface development in weeks, not months.
The Hidden Multiplication
Service Cloud pricing assumes one license per agent. A 50 agent contact centre at Enterprise tier faces $99,000 in annual Service Cloud licensing alone. Add Agentforce at $2 per conversation for AI assisted interactions across 500,000 annual conversations, and you add another $1,000,000 to the bill.
The open source alternative: SuiteCRM for case management (free), Asterisk for telephony integration (free), Claude API for AI assistance ($15,000 at the previously calculated rates). Total annual cost: under $50,000 including infrastructure.
The multiplication factor approaches 20x for equivalent functionality.
5. Financial Services Cloud: The Premium Vertical Tax
For financial institutions, Salesforce’s pitch escalates to Financial Services Cloud, a vertical specific offering that commands substantial premium pricing while delivering functionality largely achievable through standard CRM configuration and modern API integration.
The Vertical Premium
Financial Services Cloud pricing reflects Salesforce’s understanding that financial institutions face compliance pressure and risk averse procurement:
Enterprise Edition starts at $300 per user per month, nearly double the standard Sales Cloud Enterprise pricing. The Unlimited Edition commands $475 per user per month. The combined Sales and Service variant begins at $325 per user per month.
For a 200 person wealth management operation, Financial Services Cloud Enterprise licensing alone costs $720,000 annually. Add implementation, integration, and the inevitable premium support tier, and year one investment easily exceeds $1.5 million.
Deconstructing the “Industry Specific” Value
Financial Services Cloud’s claimed differentiators reduce to three categories:
Industry Data Model: FSC provides pre configured objects for financial accounts, households, relationships, and goals. This data model, while thoughtfully designed, is simply a schema. PostgreSQL can implement identical entity relationships. The schema documentation is publicly available; replication requires database design effort, not licensing fees.
The Financial Account object tracks checking accounts, savings accounts, mortgages, credit cards, investment accounts, and insurance policies. Standard relational modelling handles this elegantly. The Household construct represents family wealth structures. A self referential relationship table achieves the same outcome.
Wealth Management Features: Portfolio tracking, goal based planning, and client financial summaries. These are reporting views over financial data, achievable through any BI tool connected to a well designed database. Metabase or Apache Superset generate equivalent visualisations.
Compliance Tools: KYC workflows, audit trails, and regulatory reporting frameworks. Critically, Financial Services Cloud does not provide out of the box compliance. It provides workflow primitives that must be configured for specific regulatory requirements. The same configuration can occur in any workflow system.
What Financial Services Cloud Actually Lacks
Despite the premium pricing, FSC exhibits significant gaps for common financial services use cases:
Loan Origination: FSC does not include application tracking, credit decisioning, or disbursement workflows. Banks requiring these capabilities must purchase additional products or build custom solutions.
Loan Servicing: Payment schedules, ACH processing, delinquency tracking, and payoff calculations require separate platforms. Salesforce partners sell complementary products to fill these gaps.
Core Banking Integration: FSC provides no native connectors to common core banking systems. Integration requires MuleSoft (additional licensing) or custom development.
The irony: organisations pay premium FSC pricing, then discover they still require substantial custom development or third party products to address actual banking workflows.
The Alternative for Financial Services
A modern financial services CRM architecture might include:
PostgreSQL with a purpose built financial services schema, modelling accounts, households, relationships, goals, and transactions. Total schema design and implementation: 2 to 4 weeks of engineering effort.
Twenty CRM or a custom React frontend providing relationship manager interface and client portal capabilities. Implementation: 4 to 8 weeks.
n8n or Temporal for workflow automation covering onboarding, KYC, and review processes. Implementation: 2 to 4 weeks.
Claude API integration for intelligent document processing, client communication drafting, and natural language querying of client data. Implementation: 2 to 3 weeks.
Total implementation timeline: 3 to 4 months. Total annual infrastructure and API cost: under $100,000 for a substantial operation.
Versus Financial Services Cloud: 6 to 12 month implementation, $720,000 or more annual licensing for 200 users, plus implementation partner fees typically ranging from $500,000 to $2 million.
The vertical tax extracts value without delivering proportional capability.
6. The Architecture of Liberation
A modern, AI native customer engagement platform can be assembled from open source components at a fraction of the Salesforce cost:
Data Layer
PostgreSQL with pgvector for customer data and semantic search. Cost: Infrastructure only, approximately $500 per month on AWS RDS for substantial workloads.
CRM Layer
Twenty CRM or SuiteCRM self hosted. Cost: Infrastructure only, approximately $200 per month.
Contact Centre
FreePBX or 3CX with SIP trunking. Cost: $0.01 per minute for voice, approximately $500 per month for typical usage.
AI Orchestration
Custom implementation using LangChain or direct API integration. Claude Sonnet 4.5 for reasoning tasks, Haiku for classification and routing. Cost: $1,500 per month for 500,000 interactions.
Workflow Engine
n8n or Temporal for process automation. Cost: Infrastructure only, approximately $200 per month.
Frontend
React or Vue.js application with WebSocket support for real time updates. Cost: Development investment only.
Total monthly infrastructure cost: Approximately $3,000 for a platform handling 500,000 customer interactions, or $36,000 annually.
Equivalent Salesforce deployment: 50 Service Cloud Enterprise seats at $165 per user per month ($99,000), plus Agentforce at $2 per conversation for 500,000 monthly interactions ($12,000,000 annually using conversation pricing) or approximately $600,000 annually using Flex Credits at scale with volume discounts.
The delta is not marginal. It represents orders of magnitude difference in total cost of ownership.
7. Why Agentforce Isn’t Worth $2 Per Conversation
Agentforce’s value proposition rests on three pillars: ease of implementation, CRM integration, and the Atlas Reasoning Engine. Let us examine each:
Ease of Implementation
Salesforce claims Agentforce can be deployed without AI expertise. This is marketing positioning, not technical reality. Any meaningful deployment requires understanding of prompt engineering, knowledge base curation, guardrails configuration, and integration with business processes. These skills transfer directly to open architecture approaches.
Implementation partners charge $2,000 to $6,000 per agent for Agentforce setup and training. This investment could instead fund development of a purpose built, infinitely more flexible solution.
CRM Integration
Data Cloud provides unified customer context. But data unification is not a solved problem that requires Salesforce. Apache Kafka, Debezium, and modern CDC (Change Data Capture) tools enable real time data synchronisation across any system combination. The integration overhead is a one time engineering investment, not a perpetual licensing fee.
Atlas Reasoning Engine
Salesforce positions Atlas as differentiated AI infrastructure. In reality, it orchestrates prompts, manages context, and coordinates tool use, exactly what LangChain, AutoGen, and CrewAI provide freely. The claimed 33% improvement in answer accuracy versus “traditional AI solutions” is marketing terminology without meaningful benchmark specification.
When Agentforce is deployed, it uses the same underlying LLMs available to everyone: GPT-4o by default, or Claude Sonnet 4 on AWS Bedrock. Salesforce is not training breakthrough models. They are wrapping commodity AI in proprietary interfaces and charging a substantial premium for the privilege.
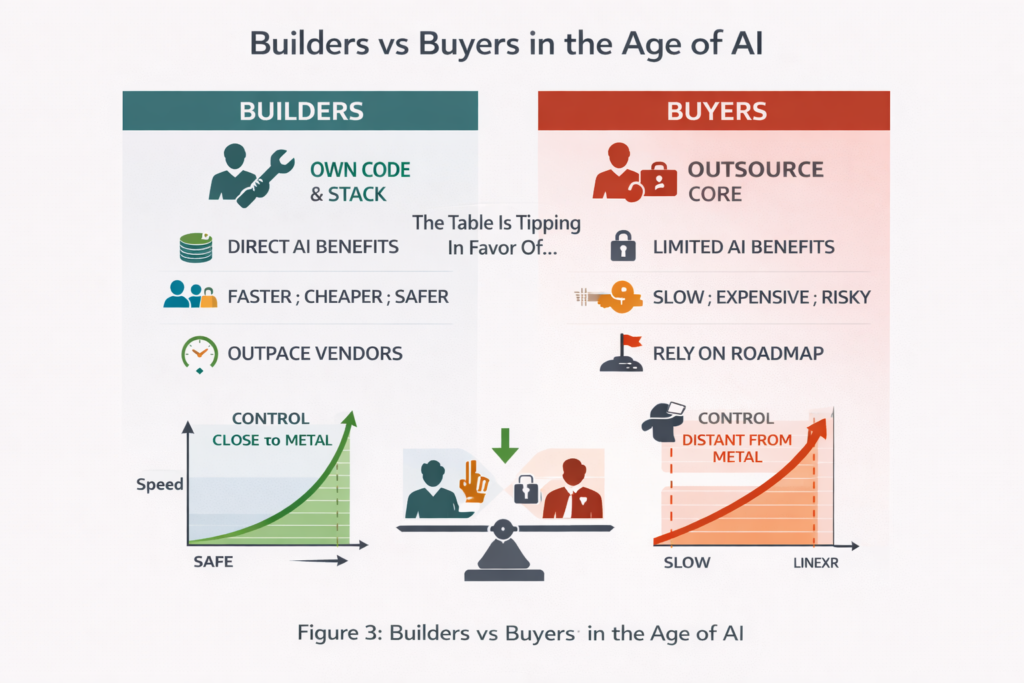
8. The Agentic Advantage: Building Close to the Problem
The true power of modern AI infrastructure lies not in enterprise platforms but in custom agents built close to the problem, evolving quickly based on real operational needs rather than enterprise roadmaps.
Consider a concrete example from fraud investigation. A fraud team identifies a need: shared agentic memory that allows investigators to store learnings that can be referenced by other investigators and agents. This is precisely the kind of domain specific capability that separates effective AI deployment from generic chatbot implementations.
With direct access to AI infrastructure, this can be prototyped almost immediately. Valkey (the open source Redis fork) provides a vector store. Mem0 delivers the memory layer. Claude handles reasoning and natural language interaction. The entire prototype materialises in hours, not quarters.
Try achieving this with Agentforce. First, the requirement enters a backlog. Then it competes with other priorities. Eventually, if fortunate, it might surface in a product enhancement request. The feature would need to reach the top of Salesforce’s roadmap, survive prioritisation against thousands of other customer requests, and emerge in some future release as a genericised capability designed for average use cases.
This velocity differential compounds over time. An organisation building custom agents accumulates institutional AI capability. Domain specific patterns emerge. Integration knowledge deepens. Each prototype informs the next.
An organisation waiting for enterprise vendors accumulates nothing but licensing costs and dependency. When Salesforce eventually ships a feature approximating the requirement, it arrives as a generic solution designed for the median customer, not the specific operational context that drove the original need.
The fraud investigation memory example illustrates a broader principle: the organisations capturing maximum value from AI are those building bespoke capabilities aligned to their operational reality. They treat LLMs as infrastructure components, not as features rented from platform vendors.
This requires engineering capability and architectural confidence. But the investment returns compound, while licensing fees simply accumulate.
9. The Integration Fallacy
Enterprise software vendors have long argued that integration complexity justifies their pricing. The unified platform, they claim, eliminates the integration burden that would otherwise consume engineering resources.
This argument has weakened substantially. Modern API design, standardised authentication (OAuth 2.0), and widespread JSON adoption have made integration work routine rather than heroic. A competent developer can connect any two SaaS applications in hours, not months.
More importantly, the integration argument assumes vendor lock in is acceptable. But lock in creates long term liability. Every workflow built on Salesforce proprietary automation becomes a migration obstacle. Every custom object schema increases switching costs.
The alternative approach, building on open standards and portable data models, preserves optionality. Customer data in PostgreSQL can be queried by any application. Workflows in n8n can be exported and reimplemented. LLM integrations can switch providers without architectural overhaul.
10. The Consultant Economy Distortion
Salesforce has spawned an enormous consulting ecosystem. Deloitte, Accenture, and hundreds of boutique firms derive substantial revenue from Salesforce implementations. This creates a self reinforcing dynamic where consultants recommend Salesforce because they profit from Salesforce, not because it represents optimal architecture.
The 6% price increase announced for August 2025 affecting Enterprise and Unlimited editions demonstrates Salesforce’s confidence in this lock in effect. Customers with substantial sunk costs in Salesforce customisation face painful switching economics, enabling Salesforce to extract increasing rents.
New greenfield deployments face no such constraint. The rational economic choice is increasingly to avoid the Salesforce ecosystem entirely.
11. The Security and Compliance Consideration
Enterprise procurement often defaults to established vendors citing security and compliance requirements. Salesforce’s Trust Layer and SOC 2 certifications provide compliance checkbox satisfaction.
However, self hosted open source alternatives can achieve identical certifications. PostgreSQL on AWS RDS operates within SOC 2 compliant infrastructure. LLM API calls can route through VPCs with appropriate network isolation. The compliance burden is operational, not architectural.
For industries with strict data residency requirements, self hosted architectures may actually provide superior compliance positioning. Customer data never leaves organisational control, whereas Salesforce processes data across shared infrastructure.
12. The Talent Arbitrage
Salesforce skills command premium compensation. Certified administrators earn $85,000 to $120,000 annually. Architects command $150,000 to $250,000. This reflects artificial scarcity created by proprietary platform complexity.
General purpose engineering skills (Python, PostgreSQL, React, API integration) are far more abundant and fungible. Building on open technologies enables access to a broader talent pool at more competitive rates.
Moreover, engineers prefer working with modern, open architectures. Recruiting becomes easier when the technology stack aligns with industry best practices rather than proprietary vendor frameworks.
13. The Financial Services Cloud Premium: Industry Vertical Lock In
For banks, wealth managers, and insurers, Salesforce offers Financial Services Cloud (FSC), a vertically specialised platform that commands even steeper pricing than standard Service Cloud. The financial argument for FSC deserves particular scrutiny because it exemplifies the enterprise platform premium extraction model at its most aggressive.
The FSC Price Tag
Financial Services Cloud pricing starts at $300 per user per month for Enterprise Edition, rising to $475 per user per month for Unlimited Edition. Combined Sales and Service editions can reach $700 per user per month. These figures represent an 80% to 125% premium over standard Service Cloud pricing.
For a 200 seat wealth management firm, annual FSC licensing alone exceeds $720,000 before implementation, customisation, or Agentforce additions. Add Agentforce 1 Edition at $550 per user per month and you’re looking at $1.32 million annually just for platform access.
What FSC Actually Provides
The FSC value proposition centres on several capabilities:
Industry Data Model: Pre built objects for financial accounts, households, financial goals, and relationship hierarchies. These are database schemas, not proprietary technology. PostgreSQL with appropriate table design achieves identical functionality.
Relationship Visualisation: Displays connections between individuals, households, and business entities. Graph databases like Neo4j provide superior relationship modelling at a fraction of the cost.
Compliance Workflows: Pre configured processes for KYC, AML, and regulatory reporting. These codify standard industry practices that any competent development team can implement.
Integration Accelerators: MuleSoft connectors to core banking platforms. These are API integrations that exist in the open source ecosystem or can be built directly.
Einstein Financial Insights: AI driven recommendations and predictions. The same Claude or GPT models that power these features are available via direct API integration.
The Open Source Financial Services Alternative
The financial services industry has embraced open source more enthusiastically than many sectors. FINOS (Fintech Open Source Foundation), backed by institutions like Fidelity, NatWest, Deutsche Bank, and Capital One, coordinates collaborative development of financial services technology.
Apache Fineract provides open source core banking infrastructure. Combined with modern CRM alternatives, wealth management specific functionality can be assembled without FSC dependency:
Client and Household Management
SuiteCRM or Twenty CRM with custom objects for financial relationships. One time development cost, zero ongoing licensing.
Portfolio and Account Aggregation
Plaid APIs for account connectivity ($0.20 to $0.50 per connection), integrated with custom dashboards built on Metabase or Apache Superset.
Financial Goal Tracking
Custom application development using standard frameworks. A competent team builds this in weeks, not months.
Compliance and Regulatory Reporting
Purpose built workflows using n8n or Temporal for orchestration, with document generation via standard templating libraries.
AI Powered Advisory
Direct Claude integration for natural language interaction, goal analysis, and recommendation generation. Claude Sonnet at $3 per million input tokens delivers superior reasoning to Einstein at a fraction of the cost.
The FSC Total Cost Comparison
Consider a mid sized wealth management firm with 100 relationship managers:
Salesforce FSC Route
FSC Unlimited licensing: 100 × $475 × 12 = $570,000
Agentforce add on: 100 × $125 × 12 = $150,000
Data Cloud: approximately $180,000
Implementation: approximately $250,000
Annual consulting: approximately $150,000
Year one total: $1,300,000
Ongoing annual cost: $1,050,000
Open Architecture Route
CRM platform (SuiteCRM self hosted): approximately $24,000 infrastructure
Custom financial data model development: approximately $80,000 one time
Portfolio aggregation (Plaid): approximately $30,000 annually
AI integration (Claude API): approximately $36,000 annually
Workflow automation: approximately $12,000 infrastructure
Custom dashboard development: approximately $60,000 one time
Ongoing engineering support: approximately $120,000 annually
Year one total: $362,000
Ongoing annual cost: $222,000
The delta exceeds $800,000 annually on an ongoing basis. Over five years, the open architecture approach saves approximately $4 million while providing greater flexibility and zero vendor lock in.
The Regulatory Compliance Myth
FSC marketing emphasises regulatory compliance as a key value proposition. Banks and wealth managers must adhere to GDPR, GLBA, SOC 2, and industry specific regulations.
However, compliance is a function of process and controls, not platform selection. A properly architected open source deployment achieves identical compliance posture:
PostgreSQL on AWS RDS operates within SOC 2 Type II certified infrastructure. Encryption at rest and in transit is standard. Audit logging is native functionality.
KYC and AML workflows are business logic, not platform magic. They require customer due diligence data collection, risk scoring, and suspicious activity reporting. These processes can be implemented in any competent workflow engine.
Data residency requirements are actually better served by self hosted deployments where customer data never leaves organisational infrastructure boundaries.
The Wealth Management AI Opportunity
The intersection of wealth management and AI represents perhaps the clearest example of Salesforce’s value extraction meeting its natural limit.
A wealth management AI assistant needs to:
- Understand client financial situations holistically
- Provide personalised investment guidance
- Monitor portfolios and alert to opportunities or risks
- Support compliance documentation
- Enable natural language interaction
Claude excels at all of these tasks. With appropriate RAG implementation against client data, a purpose built wealth management AI delivers superior functionality to Einstein Financial Insights.
The cost differential is staggering. A wealth management firm processing 50,000 AI assisted client interactions monthly faces:
FSC + Agentforce: $100,000+ monthly (platform licensing plus $2 per conversation)
Direct Claude integration: approximately $3,000 monthly (API costs at typical conversation lengths)
The 30x cost difference cannot be justified by marginal convenience benefits. It represents pure value extraction enabled by institutional lock in and procurement process capture.
14. Building the Alternative
For organisations ready to escape the enterprise platform paradigm, the path forward involves several key decisions:
Data Architecture First
Begin with customer data modelling. Define entities, relationships, and access patterns before selecting tooling. PostgreSQL provides a flexible foundation that supports both transactional and analytical workloads.
Modular AI Integration
Implement LLM capabilities as composable services. Create thin wrappers around provider APIs that enable model switching. Use semantic routing to direct queries to appropriate models based on complexity and cost.
Event Driven Workflows
Adopt event sourcing for customer interactions. Every touchpoint becomes an event that flows through a processing pipeline. This enables sophisticated automation without rigid workflow engines.
Progressive Enhancement
Start with core functionality and iterate. A minimal viable customer platform can launch in weeks, not months. Each iteration adds capability informed by actual usage patterns.
Invest in Operational Excellence
The cost savings from avoiding enterprise platforms should partially fund operational maturity. Implement proper monitoring, alerting, and incident response from day one.
15. The Strategic Inflection Point
We are witnessing a fundamental restructuring of enterprise software economics. The value capture model that sustained Salesforce’s growth, charging premium prices for integrated functionality, is collapsing under the weight of commoditised AI and mature open source alternatives.
This is not merely a pricing adjustment. It is a power shift.
The Leverage Inversion
For two decades, enterprise platforms held leverage over buyers. Switching costs accumulated. Data became trapped. Workflows encoded platform assumptions. Procurement cycles favoured incumbents. The platform controlled the relationship.
AI inverts this dynamic. Intelligence, once the hardest problem, is now the cheapest component. The platform’s historical advantage, integrating complex capabilities into coherent experiences, diminishes when the core capability commoditises.
Buyers now hold leverage they have not possessed since the pre cloud era. Every contract renewal is an opportunity to renegotiate from strength. Every new project is a chance to avoid dependency entirely.
The Bundling Response
Vendors recognise this shift. Their response will be aggressive bundling. More features included at current prices. Deeper integration across product lines. Longer contract terms with steeper early termination penalties.
This is defensive positioning, not value creation. The bundled features address problems that direct AI integration solves more elegantly. The integration depth increases switching costs without delivering proportional capability improvement.
Organisations that recognise bundling as a lock in strategy rather than a value proposition will negotiate accordingly.
The Inertia Trap
The most dangerous response is no response. Continuing current trajectories because change requires effort, because procurement processes favour renewals, because internal stakeholders have built careers around existing platforms.
Inertia compounds. Each year of continued platform dependency increases migration complexity. Each workflow built on proprietary automation adds switching cost. Each data model embedded in vendor schema reduces portability.
The cost of inaction is invisible until it becomes prohibitive. Organisations that wait for obvious inflection points will find themselves negotiating from weakness while competitors operate from positions of architectural freedom.
The Institutional Barriers
The technical barriers to building modern customer engagement platforms have evaporated. The remaining barriers are institutional:
Procurement Processes: Optimised for vendor relationships, not technical evaluation. RFP templates that favour incumbent categories. Evaluation criteria weighted toward features rather than total cost of ownership.
IT Governance Frameworks: Risk models calibrated to established vendors. Security reviews that default to known platforms. Architecture review boards that mistake familiarity for safety.
Executive Comfort: Recognition of established brands. Relationships with vendor account teams. Reluctance to champion unfamiliar approaches.
These institutional barriers are real but surmountable. They require executive sponsorship willing to challenge procurement orthodoxy, technical leadership confident in alternative architectures, and organisational patience to build internal capability.
The financial case for alternative architectures grows more compelling with each price increase, each new AI capability released into the open ecosystem, and each month of compounding platform dependency.
The question is whether institutional barriers will yield before the economic case becomes undeniable, or whether organisations will pay the accumulated cost of delayed action.
16. Conclusion: Control Versus Convenience
This analysis is not about AI versus platforms. It is about control versus convenience.
AI has made intelligence cheap and portable. The platforms no longer own the hardest problem. When reasoning capability costs $0.03 per interaction via direct API but $2.00 through enterprise wrappers, the economic logic of platform dependency inverts.
The Economic Reality
AI costs are falling rapidly. Platform AI pricing remains at premium levels. This gap is unsustainable.
Buyers are gaining leverage. Vendors will respond by bundling harder, adding more features to justify existing price points, making extraction more difficult. The rational response is to establish optionality before the bundling intensifies.
Where the Real Moat Moves
The defensible advantage is no longer in tools or models. It moves to semantics:
Decision Logic: The rules that determine how customer interactions resolve, how exceptions escalate, how edge cases route. This is institutional knowledge, not platform capability.
Risk and Policy Rules: Compliance requirements, fraud detection patterns, credit decisioning criteria. These encode organisational judgment refined over years.
Domain Context: Understanding what matters in your specific industry, your specific customer base, your specific operational reality. Generic platforms cannot provide this.
Data Meaning: The interpretation layer that transforms raw information into actionable insight. This requires deep familiarity with data lineage, quality characteristics, and business semantics.
Who owns this controls outcomes. Platforms provide infrastructure. Semantics determine value.
The Strategic Risk Matrix
Two failure modes exist:
Staying Locked In: Rising costs, diminishing leverage, strategic decisions constrained by vendor roadmaps. The platform extracts increasing rent while delivering commoditised capability.
Full DIY Without Governance: Technical debt accumulation, security gaps, scaling challenges, key person dependencies. The build option requires organisational maturity to execute sustainably.
The real danger is inertia. Continuing current trajectories because change requires effort. The cost of inaction compounds silently until switching becomes prohibitively expensive.
The Winning Architecture
The answer is composable core with vendor optionality:
Use platforms where they genuinely add value: Identity management, payment processing, regulatory reporting infrastructure. Areas where vendor expertise exceeds internal capability and switching costs remain manageable.
Keep AI orchestration internal: The reasoning layer, the decision logic, the semantic understanding. This is competitive advantage, not commodity infrastructure.
Maintain data ownership: Customer data, interaction history, learned patterns. These assets appreciate over time. Leasing them to vendors surrenders compound returns.
Design systems to be replaceable: Standard interfaces, portable data formats, documented integration points. Every component should be substitutable without architectural overhaul.
The Bottom Line
AI transforms enterprise platforms from strategic assets into negotiable components.
Salesforce built a $34 billion business by providing integrated customer engagement capabilities that were genuinely difficult to replicate. That era has ended. The capabilities are now commodity. The integration complexity has dissolved. The pricing reflects historical leverage, not current value delivery.
Advantage accrues to organisations that:
Separate capability from vendor: Understand what you need versus who currently provides it. Map dependencies. Identify alternatives. Negotiate from knowledge.
Treat AI as infrastructure: Not as a feature rented from platform vendors, but as a utility consumed from the most efficient source. LLMs are interchangeable. Orchestration is portable. Lock in is optional.
Design for optionality, not permanence: Every architectural decision should preserve future flexibility. The technology landscape will continue evolving. Organisations designed for adaptation will outperform those optimised for current state.
The mathematics have changed. The technical barriers have fallen. The financial case is overwhelming.
The remaining question is organisational: does your institution have the clarity to recognise the shift, the courage to act on it, and the capability to execute the transition?
The alternative is continuing to fund an increasingly unjustifiable value extraction, paying premium prices for commodity capability, while competitors capture the economic benefits of AI democratisation.
The choice is control or convenience. The economics favour control. The future belongs to those who recognise this early enough to act.