Category: Kafka
The Year Kafka Grew Up: What version 4.x Actually Means for Platform Teams
There is a version of the Apache Kafka story that gets told as a series of press releases. ZooKeeper removed. KRaft promoted. Share groups landed. Iceberg everywhere. Each headline lands cleanly, and then platform teams go back to their actual clusters and wonder what any of it means for them. This post is the other […]
Read more →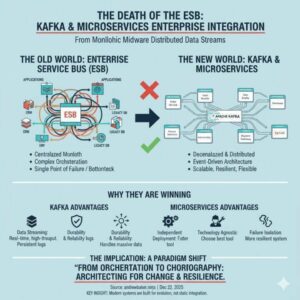
The Death of the Enterprise Service Bus: Why Kafka and Microservices Are Winning
1. Introduction The Enterprise Service Bus (ESB) once promised to be the silver bullet for enterprise integration. Organizations invested millions in platforms like MuleSoft, IBM Integration Bus, Oracle Service Bus, and TIBCO BusinessWorks, believing they would solve all their integration challenges. Today, these same organizations are discovering that their ESB has become their biggest architectural […]
Read more →