Category: Banking
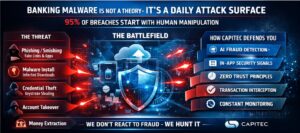
Banking Malware: What It Is, How to Spot It, and Why Capitec Has You Covered
Published by Andrew Baker and the Capitec App Security Team | March 2026 For media enquiries and quotable statistics from this article, see the Press Summary at the end. Every day, approximately 15 million South Africans open the Capitec app to check their balance, pay a bill, or send money to a loved one. It […]
Read more →
Why Capitec Pulse Is a World First and Why You Cannot Just Copy It
By Andrew Baker, Chief Information Officer, Capitec Bank The Engineering Behind Capitec Pulse 1. Introduction I have had lots of questions about how we are “reading our clients minds”. This is a great question, but the answer is quite complex – so I decided to blog it. The article below really focuses on the heavy […]
Read more →Transcripts from the Meeting Where Core Banking was Invented (A Faithful Reconstruction)
A companion piece to Core Banking Is a Terrible Idea. It Always Was. It is 1972. A group of very serious men in very wide ties are gathered in a very beige conference room. They are about to make decisions that will haunt your change advisory board fifty years from now. The following is a […]
Read more →
Core Banking Is a Terrible Idea. It Always Was.
The COBOL apocalypse conversation this week has been useful, because it has forced the industry to confront something it has been avoiding for decades. But most of the coverage is stopping at the wrong point. Everyone is talking about COBOL. Nobody is talking about the architectural philosophy that COBOL gave birth to, the one that […]
Read more →
The Blog Post That Erased $30 Billion from IBM
Anthropic published a blog post on Monday. Not a product launch, not a partnership announcement, not a keynote at a major conference. Just a simple blog post explaining that Claude Code can read COBOL. IBM proceeded to drop 13%, its worst single day loss since October 2000, with twenty five years of stock resilience gone […]
Read more →Is Banking Complexity a Shared Destiny or Is It a Leadership Failure?
If you look back over time at all once great companies, you will see that eventually simplicity gave way to scale. What are some of the risks that drive this? This is where many great banks lose their edge. But is this really a shared destiny for all banks, or did the leadership simply fail […]
Read more →Protected: PRFAQ: Neo – Proactive, Zero Friction Client Support at Capitec
There is no excerpt because this is a protected post.
Read more →
Banking in South Africa: Abundance, Pressure, and the Coming Consolidation
I wanted to write about the trends we can see playing out, both in South Africa and globally with respect to: Large Retailers, Mobile Networks, Banking, Insurance and Technology. These thoughts are my own and I am often wrong, so dont get too excited if you dont agree with me 🙂 South Africa is experiencing […]
Read more →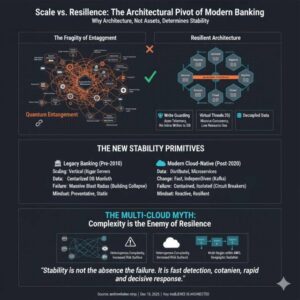
Why Bigger Banks Were Historically More Fragile and Why Architecture Determines Resilience
1. Size Was Once Mistaken for Stability For most of modern banking history, stability was assumed to increase with size. The thinking was the bigger you are, the more you should care, the more resources you can apply to problems. Larger banks had more capital, more infrastructure, and more people. In a pre-cloud world, this […]
Read more →MacOs: Getting Started with Memgraph, Memgraph MCP and Claude Desktop by Analyzing test banking data for Mule Accounts
1. Introduction This guide walks you through setting up Memgraph with Claude Desktop on your laptop to analyze relationships between mule accounts in banking systems. By the end of this tutorial, you’ll have a working setup where Claude can query and visualize banking transaction patterns to identify potential mule account networks. Why Graph Databases for […]
Read more →