Category: Public Cloud + Databases
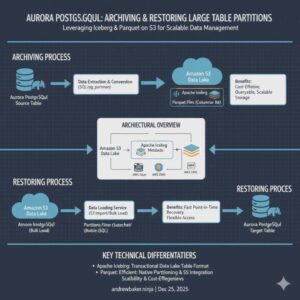
Aurora PostgreSQL: Archive Partitions to S3 Iceberg & Parquet
A Complete Guide to Archiving, Restoring, and Querying Large Table Partitions When dealing with multi-terabyte tables in Aurora PostgreSQL, keeping historical partitions online becomes increasingly expensive and operationally burdensome. This guide presents a complete solution for archiving partitions to S3 in Iceberg/Parquet format, restoring them when needed, and querying archived data directly via a Spring […]
Read more →Model Context Protocol: Enterprise Implementation Guide
The Model Context Protocol (MCP) represents a fundamental shift in how we integrate Large Language Models (LLMs) with external data sources and tools. As enterprises increasingly adopt AI powered applications, understanding MCP’s architecture, operational characteristics, and practical implementation becomes critical for technical leaders building production systems. 1. What is Model Context Protocol? Model Context Protocol […]
Read more →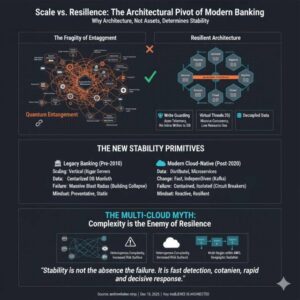
Why Bank Architecture Determines Resilience More Than Size
1. Size Was Once Mistaken for Stability For most of modern banking history, stability was assumed to increase with size. The thinking was the bigger you are, the more you should care, the more resources you can apply to problems. Larger banks had more capital, more infrastructure, and more people. In a pre-cloud world, this […]
Read more →Memgraph & Claude Desktop: Detect Mule Accounts on macOS
1. Introduction This guide walks you through setting up Memgraph with Claude Desktop on your laptop to analyze relationships between mule accounts in banking systems. By the end of this tutorial, you’ll have a working setup where Claude can query and visualize banking transaction patterns to identify potential mule account networks. Why Graph Databases for […]
Read more →
PostgreSQL Prepared Statements: Fix Plan Caching Memory Issues
Prepared statements are one of PostgreSQL’s most powerful features for query optimization. By parsing and planning queries once, then reusing those plans for subsequent executions, they can dramatically improve performance. But this optimization comes with a hidden danger: sometimes caching the same plan for every execution can lead to catastrophic memory exhaustion and performance degradation. […]
Read more →
Amazon Aurora DSQL: Performance, Limits & Architecture
1. Executive Summary Amazon Aurora DSQL represents AWS’s ambitious entry into the distributed SQL database market, announced at re:Invent 2024. It’s a serverless, distributed SQL database featuring active active high availability and PostgreSQL compatibility. While the service offers impressive architectural innovations including 99.99% single region and 99.999% multi region availability, but it comes with significant […]
Read more →
PostgreSQL Vacuum Optimization for Large Tables: Deep Dive
When managing large PostgreSQL tables with frequent updates, vacuum operations become critical for maintaining database health and performance. In this comprehensive guide, we’ll explore vacuum optimization techniques, dive deep into the pg_repack extension, and provide hands-on examples you can run in your own environment. 1. Understanding the Problem PostgreSQL uses Multi-Version Concurrency Control (MVCC) to […]
Read more →
AWS NLB Sticky Sessions: Setup, Behavior & Pitfalls
When you deploy applications behind a Network Load Balancer (NLB) in AWS, you usually expect perfect traffic distribution, fast, fair, and stateless.But what if your backend holds stateful sessions, like in-memory login sessions, caching, or WebSocket connections and you need a given client to keep hitting the same target every time? That’s where NLB sticky […]
Read more →
SQL Server 2019 Diagnostic Queries: Glenn Berry’s Guide
Finding issues in SQL Server is not alway that easy. It can be NUMA issues, it can be DBCC settings, it can even be the CU (eg CU19). A friend sent me a very useful query a few years ago that really helped me fault find these issues. It was written by Glenn Berry, but […]
Read more →Delete 50+ EBS Snapshots Using AWS CLI: Step-by-Step
The Amazon EC2 console allows you to delete up to 50 Amazon Elastic Block Store (Amazon EBS) snapshots at once. To delete more than 50 snapshots, use the AWS Command Line Interface (AWS CLI) or the AWS SDK. To see all the snapshots that you own in a specific region, run the following. Note, replace […]
Read more →