Category: Public Cloud

Aurora Serverless v2 PostgreSQL: Production Scaling Guide
Aurora Serverless v2 promises the dream of a database that automatically scales to meet demand, freeing engineering teams from capacity planning. The reality is considerably more nuanced. After running Serverless v2 PostgreSQL clusters under production workloads, I have encountered enough sharp edges to fill a blog post. This is that post. The topics covered here […]
Read more →Auto-Recover a Failed WordPress Instance on AWS
When WordPress goes down on your AWS instance, waiting for manual intervention means downtime and lost revenue. Here are two robust approaches to automatically detect and recover from WordPress failures. Approach 1: Lambda Based Intelligent Recovery This approach tries the least disruptive fix first (restarting services) before escalating to a full instance reboot. Step 1: […]
Read more →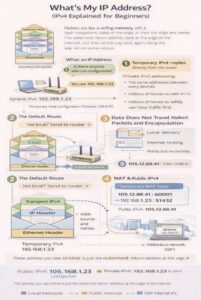
What Is My IP Address? IPv4 Explained for Beginners
Firstly, let me acknowledge that there are lots of these kinds of posts on the internet. But the reason why i wrote this blog is that I wanted to force myself to consolidate the various articles I have read and my learnt knowledge in this space. I will probably update this article several times and […]
Read more →Protected: Neo by Capitec: AI Client Support That Resolves Issues Proactively
There is no excerpt because this is a protected post.
Read more →WordPress on AWS Graviton: Deploy & Migrate in Minutes
Running WordPress on ARM-based Graviton instances delivers up to 40% better price-performance compared to x86 equivalents. This guide provides production-ready scripts to deploy an optimised WordPress stack in minutes, plus everything you need to migrate your existing site. Why Graviton for WordPress? Graviton3 processors deliver: The t4g.small instance (2 vCPU, 2GB RAM) at ~$12/month handles […]
Read more →
Rubrik Architecture: Why Restore, Not Backup, Is the Product
1. Backups Should Be Boring (and That Is the Point) Backups are boring. They should be boring. A backup system that generates excitement is usually signalling failure. The only time backups become interesting is when they are missing, and that interest level is lethal. Emergency bridges. Frozen change windows. Executive escalation. Media briefings. Regulatory apology […]
Read more →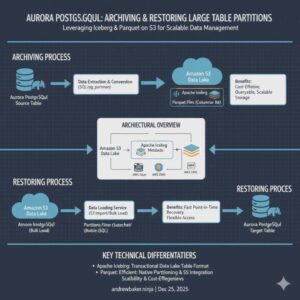
Aurora PostgreSQL: Archive Partitions to S3 Iceberg & Parquet
A Complete Guide to Archiving, Restoring, and Querying Large Table Partitions When dealing with multi-terabyte tables in Aurora PostgreSQL, keeping historical partitions online becomes increasingly expensive and operationally burdensome. This guide presents a complete solution for archiving partitions to S3 in Iceberg/Parquet format, restoring them when needed, and querying archived data directly via a Spring […]
Read more →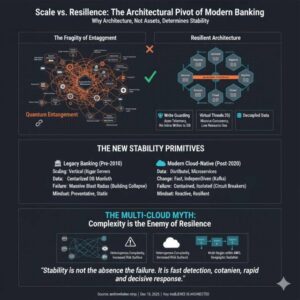
Why Bank Architecture Determines Resilience More Than Size
1. Size Was Once Mistaken for Stability For most of modern banking history, stability was assumed to increase with size. The thinking was the bigger you are, the more you should care, the more resources you can apply to problems. Larger banks had more capital, more infrastructure, and more people. In a pre-cloud world, this […]
Read more →PostgreSQL Prepared Statements: Fix Plan Caching Memory Issues
Prepared statements are one of PostgreSQL’s most powerful features for query optimization. By parsing and planning queries once, then reusing those plans for subsequent executions, they can dramatically improve performance. But this optimization comes with a hidden danger: sometimes caching the same plan for every execution can lead to catastrophic memory exhaustion and performance degradation. […]
Read more →
Amazon Aurora DSQL: Performance, Limits & Architecture
1. Executive Summary Amazon Aurora DSQL represents AWS’s ambitious entry into the distributed SQL database market, announced at re:Invent 2024. It’s a serverless, distributed SQL database featuring active active high availability and PostgreSQL compatibility. While the service offers impressive architectural innovations including 99.99% single region and 99.999% multi region availability, but it comes with significant […]
Read more →