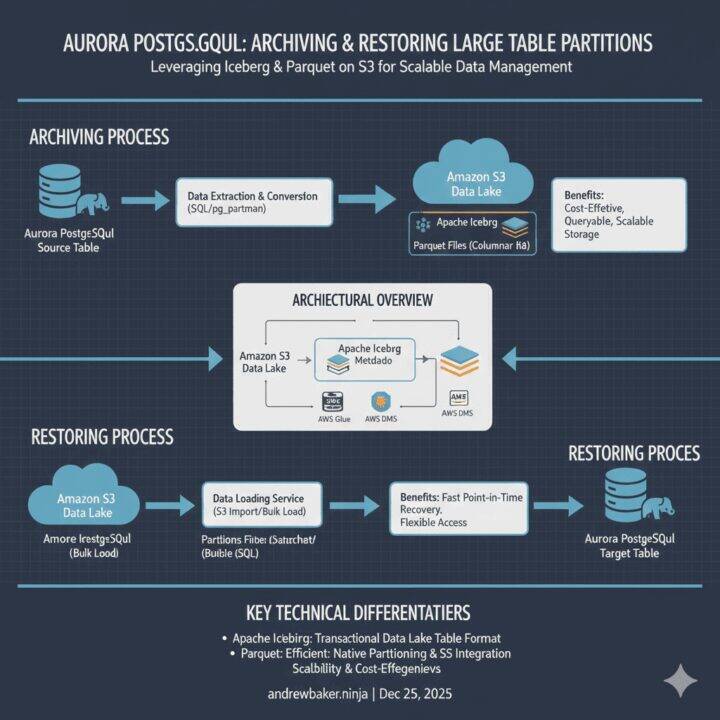
Aurora PostgreSQL: Archive Partitions to S3 Iceberg & Parquet


Archiving Aurora PostgreSQL partitions to S3 involves exporting partition data as Parquet files organised in Apache Iceberg table format using a script that queries the partition, writes columnar files via PyArrow, registers metadata in an Iceberg catalog on S3, then drops the source partition. Archived data remains directly queryable through Athena or a Spring Boot API without database restoration.
A Complete Guide to Archiving, Restoring, and Querying Large Table Partitions
When dealing with multi-terabyte tables in Aurora PostgreSQL, keeping historical partitions online becomes increasingly expensive and operationally burdensome. This guide presents a complete solution for archiving partitions to S3 in Iceberg/Parquet format, restoring them when needed, and querying archived data directly via a Spring Boot API without database restoration.
1. Architecture Overview
The solution comprises three components:
- Archive Script: Exports a partition from Aurora PostgreSQL to Parquet files organised in Iceberg table format on S3
- Restore Script: Imports archived data from S3 back into a staging table for validation and migration to the main table
- Query API: A Spring Boot application that reads Parquet files directly from S3, applying predicate pushdown for efficient filtering
This approach reduces storage costs by approximately 70 to 80 percent compared to keeping data in Aurora, while maintaining full queryability through the API layer.
2. Prerequisites and Dependencies
2.1 Python Environment
pip install boto3 pyarrow psycopg2-binary pandas pyiceberg sqlalchemy2.2 AWS Configuration
Ensure your environment has appropriate IAM permissions:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::your-archive-bucket",
"arn:aws:s3:::your-archive-bucket/*"
]
},
{
"Effect": "Allow",
"Action": [
"glue:CreateTable",
"glue:GetTable",
"glue:UpdateTable",
"glue:DeleteTable"
],
"Resource": "*"
}
]
}2.3 Java Dependencies
For the Spring Boot API, add these to your pom.xml:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.14.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-aws</artifactId>
<version>3.3.6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.6</version>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
<version>2.25.0</version>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-core</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-parquet</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-aws</artifactId>
<version>1.5.0</version>
</dependency>
</dependencies>3. The Archive Script
This script extracts a partition from Aurora PostgreSQL and writes it to S3 in Iceberg table format with Parquet data files.
3.1 Configuration Module
# config.py
from dataclasses import dataclass
from typing import Optional
import os
@dataclass
class DatabaseConfig:
host: str
port: int
database: str
user: str
password: str
@classmethod
def from_environment(cls) -> "DatabaseConfig":
return cls(
host=os.environ["AURORA_HOST"],
port=int(os.environ.get("AURORA_PORT", "5432")),
database=os.environ["AURORA_DATABASE"],
user=os.environ["AURORA_USER"],
password=os.environ["AURORA_PASSWORD"]
)
@property
def connection_string(self) -> str:
return f"postgresql://{self.user}:{self.password}@{self.host}:{self.port}/{self.database}"
@dataclass
class S3Config:
bucket: str
prefix: str
region: str
@classmethod
def from_environment(cls) -> "S3Config":
return cls(
bucket=os.environ["ARCHIVE_S3_BUCKET"],
prefix=os.environ.get("ARCHIVE_S3_PREFIX", "aurora-archives"),
region=os.environ.get("AWS_REGION", "eu-west-1")
)
@dataclass
class ArchiveConfig:
table_name: str
partition_column: str
partition_value: str
schema_name: str = "public"
batch_size: int = 100000
compression: str = "snappy"3.2 Schema Introspection
# schema_inspector.py
from typing import Dict, List, Tuple, Any
import psycopg2
from psycopg2.extras import RealDictCursor
import pyarrow as pa
class SchemaInspector:
"""Inspects PostgreSQL table schema and converts to PyArrow schema."""
POSTGRES_TO_ARROW = {
"integer": pa.int32(),
"bigint": pa.int64(),
"smallint": pa.int16(),
"real": pa.float32(),
"double precision": pa.float64(),
"numeric": pa.decimal128(38, 10),
"text": pa.string(),
"character varying": pa.string(),
"varchar": pa.string(),
"char": pa.string(),
"character": pa.string(),
"boolean": pa.bool_(),
"date": pa.date32(),
"timestamp without time zone": pa.timestamp("us"),
"timestamp with time zone": pa.timestamp("us", tz="UTC"),
"time without time zone": pa.time64("us"),
"time with time zone": pa.time64("us"),
"uuid": pa.string(),
"json": pa.string(),
"jsonb": pa.string(),
"bytea": pa.binary(),
}
def __init__(self, connection_string: str):
self.connection_string = connection_string
def get_table_columns(
self,
schema_name: str,
table_name: str
) -> List[Dict[str, Any]]:
"""Retrieve column definitions from information_schema."""
query = """
SELECT
column_name,
data_type,
is_nullable,
column_default,
ordinal_position,
character_maximum_length,
numeric_precision,
numeric_scale
FROM information_schema.columns
WHERE table_schema = %s
AND table_name = %s
ORDER BY ordinal_position
"""
with psycopg2.connect(self.connection_string) as conn:
with conn.cursor(cursor_factory=RealDictCursor) as cur:
cur.execute(query, (schema_name, table_name))
return list(cur.fetchall())
def get_primary_key_columns(
self,
schema_name: str,
table_name: str
) -> List[str]:
"""Retrieve primary key column names."""
query = """
SELECT a.attname
FROM pg_index i
JOIN pg_attribute a ON a.attrelid = i.indrelid
AND a.attnum = ANY(i.indkey)
JOIN pg_class c ON c.oid = i.indrelid
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE i.indisprimary
AND n.nspname = %s
AND c.relname = %s
ORDER BY array_position(i.indkey, a.attnum)
"""
with psycopg2.connect(self.connection_string) as conn:
with conn.cursor() as cur:
cur.execute(query, (schema_name, table_name))
return [row[0] for row in cur.fetchall()]
def postgres_type_to_arrow(
self,
pg_type: str,
precision: int = None,
scale: int = None
) -> pa.DataType:
"""Convert PostgreSQL type to PyArrow type."""
pg_type_lower = pg_type.lower()
if pg_type_lower == "numeric" and precision and scale:
return pa.decimal128(precision, scale)
if pg_type_lower in self.POSTGRES_TO_ARROW:
return self.POSTGRES_TO_ARROW[pg_type_lower]
if pg_type_lower.startswith("character varying"):
return pa.string()
if pg_type_lower.endswith("[]"):
base_type = pg_type_lower[:-2]
if base_type in self.POSTGRES_TO_ARROW:
return pa.list_(self.POSTGRES_TO_ARROW[base_type])
return pa.string()
def build_arrow_schema(
self,
schema_name: str,
table_name: str
) -> pa.Schema:
"""Build PyArrow schema from PostgreSQL table definition."""
columns = self.get_table_columns(schema_name, table_name)
fields = []
for col in columns:
arrow_type = self.postgres_type_to_arrow(
col["data_type"],
col.get("numeric_precision"),
col.get("numeric_scale")
)
nullable = col["is_nullable"] == "YES"
fields.append(pa.field(col["column_name"], arrow_type, nullable=nullable))
return pa.Schema(fields)
def get_partition_info(
self,
schema_name: str,
table_name: str
) -> Dict[str, Any]:
"""Get partition strategy information if table is partitioned."""
query = """
SELECT
pt.partstrat,
array_agg(a.attname ORDER BY pos.idx) as partition_columns
FROM pg_partitioned_table pt
JOIN pg_class c ON c.oid = pt.partrelid
JOIN pg_namespace n ON n.oid = c.relnamespace
CROSS JOIN LATERAL unnest(pt.partattrs) WITH ORDINALITY AS pos(attnum, idx)
JOIN pg_attribute a ON a.attrelid = c.oid AND a.attnum = pos.attnum
WHERE n.nspname = %s AND c.relname = %s
GROUP BY pt.partstrat
"""
with psycopg2.connect(self.connection_string) as conn:
with conn.cursor(cursor_factory=RealDictCursor) as cur:
cur.execute(query, (schema_name, table_name))
result = cur.fetchone()
if result:
strategy_map = {"r": "range", "l": "list", "h": "hash"}
return {
"is_partitioned": True,
"strategy": strategy_map.get(result["partstrat"], "unknown"),
"partition_columns": result["partition_columns"]
}
return {"is_partitioned": False}3.3 Archive Script
#!/usr/bin/env python3
# archive_partition.py
"""
Archive a partition from Aurora PostgreSQL to S3 in Iceberg/Parquet format.
Usage:
python archive_partition.py \
--table transactions \
--partition-column transaction_date \
--partition-value 2024-01 \
--schema public
"""
import argparse
import json
import logging
import sys
from datetime import datetime
from pathlib import Path
from typing import Generator, Dict, Any, Optional
import hashlib
import boto3
import pandas as pd
import psycopg2
from psycopg2.extras import RealDictCursor
import pyarrow as pa
import pyarrow.parquet as pq
from config import DatabaseConfig, S3Config, ArchiveConfig
from schema_inspector import SchemaInspector
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(message)s"
)
logger = logging.getLogger(__name__)
class PartitionArchiver:
"""Archives PostgreSQL partitions to S3 in Iceberg format."""
def __init__(
self,
db_config: DatabaseConfig,
s3_config: S3Config,
archive_config: ArchiveConfig
):
self.db_config = db_config
self.s3_config = s3_config
self.archive_config = archive_config
self.schema_inspector = SchemaInspector(db_config.connection_string)
self.s3_client = boto3.client("s3", region_name=s3_config.region)
def _generate_archive_path(self) -> str:
"""Generate S3 path for archive files."""
return (
f"{self.s3_config.prefix}/"
f"{self.archive_config.schema_name}/"
f"{self.archive_config.table_name}/"
f"{self.archive_config.partition_column}={self.archive_config.partition_value}"
)
def _build_extraction_query(self) -> str:
"""Build query to extract partition data."""
full_table = (
f"{self.archive_config.schema_name}.{self.archive_config.table_name}"
)
partition_info = self.schema_inspector.get_partition_info(
self.archive_config.schema_name,
self.archive_config.table_name
)
if partition_info["is_partitioned"]:
partition_table = (
f"{self.archive_config.table_name}_"
f"{self.archive_config.partition_value.replace('-', '_')}"
)
return f"SELECT * FROM {self.archive_config.schema_name}.{partition_table}"
return (
f"SELECT * FROM {full_table} "
f"WHERE {self.archive_config.partition_column} = %s"
)
def _stream_partition_data(self) -> Generator[pd.DataFrame, None, None]:
"""Stream partition data in batches."""
query = self._build_extraction_query()
partition_info = self.schema_inspector.get_partition_info(
self.archive_config.schema_name,
self.archive_config.table_name
)
with psycopg2.connect(self.db_config.connection_string) as conn:
with conn.cursor(
name="archive_cursor",
cursor_factory=RealDictCursor
) as cur:
if partition_info["is_partitioned"]:
cur.execute(query)
else:
cur.execute(query, (self.archive_config.partition_value,))
while True:
rows = cur.fetchmany(self.archive_config.batch_size)
if not rows:
break
yield pd.DataFrame(rows)
def _write_parquet_to_s3(
self,
table: pa.Table,
file_number: int,
arrow_schema: pa.Schema
) -> Dict[str, Any]:
"""Write a Parquet file to S3 and return metadata."""
archive_path = self._generate_archive_path()
file_name = f"data_{file_number:05d}.parquet"
s3_key = f"{archive_path}/data/{file_name}"
buffer = pa.BufferOutputStream()
pq.write_table(
table,
buffer,
compression=self.archive_config.compression,
write_statistics=True
)
data = buffer.getvalue().to_pybytes()
self.s3_client.put_object(
Bucket=self.s3_config.bucket,
Key=s3_key,
Body=data,
ContentType="application/octet-stream"
)
return {
"path": f"s3://{self.s3_config.bucket}/{s3_key}",
"file_size_bytes": len(data),
"record_count": table.num_rows
}
def _write_iceberg_metadata(
self,
arrow_schema: pa.Schema,
data_files: list,
total_records: int
) -> None:
"""Write Iceberg table metadata files."""
archive_path = self._generate_archive_path()
schema_dict = {
"type": "struct",
"schema_id": 0,
"fields": []
}
for i, field in enumerate(arrow_schema):
field_type = self._arrow_to_iceberg_type(field.type)
schema_dict["fields"].append({
"id": i + 1,
"name": field.name,
"required": not field.nullable,
"type": field_type
})
table_uuid = hashlib.md5(
f"{self.archive_config.table_name}_{datetime.utcnow().isoformat()}".encode()
).hexdigest()
manifest_entries = []
for df in data_files:
manifest_entries.append({
"status": 1,
"snapshot_id": 1,
"data_file": {
"file_path": df["path"],
"file_format": "PARQUET",
"record_count": df["record_count"],
"file_size_in_bytes": df["file_size_bytes"]
}
})
metadata = {
"format_version": 2,
"table_uuid": table_uuid,
"location": f"s3://{self.s3_config.bucket}/{archive_path}",
"last_sequence_number": 1,
"last_updated_ms": int(datetime.utcnow().timestamp() * 1000),
"last_column_id": len(arrow_schema),
"current_schema_id": 0,
"schemas": [schema_dict],
"partition_spec": [],
"default_spec_id": 0,
"last_partition_id": 0,
"properties": {
"source.table": self.archive_config.table_name,
"source.schema": self.archive_config.schema_name,
"source.partition_column": self.archive_config.partition_column,
"source.partition_value": self.archive_config.partition_value,
"archive.timestamp": datetime.utcnow().isoformat(),
"archive.total_records": str(total_records)
},
"current_snapshot_id": 1,
"snapshots": [
{
"snapshot_id": 1,
"timestamp_ms": int(datetime.utcnow().timestamp() * 1000),
"summary": {
"operation": "append",
"added_data_files": str(len(data_files)),
"total_records": str(total_records)
},
"manifest_list": f"s3://{self.s3_config.bucket}/{archive_path}/metadata/manifest_list.json"
}
]
}
self.s3_client.put_object(
Bucket=self.s3_config.bucket,
Key=f"{archive_path}/metadata/v1.metadata.json",
Body=json.dumps(metadata, indent=2),
ContentType="application/json"
)
self.s3_client.put_object(
Bucket=self.s3_config.bucket,
Key=f"{archive_path}/metadata/manifest_list.json",
Body=json.dumps(manifest_entries, indent=2),
ContentType="application/json"
)
self.s3_client.put_object(
Bucket=self.s3_config.bucket,
Key=f"{archive_path}/metadata/version_hint.text",
Body="1",
ContentType="text/plain"
)
def _arrow_to_iceberg_type(self, arrow_type: pa.DataType) -> str:
"""Convert PyArrow type to Iceberg type string."""
type_mapping = {
pa.int16(): "int",
pa.int32(): "int",
pa.int64(): "long",
pa.float32(): "float",
pa.float64(): "double",
pa.bool_(): "boolean",
pa.string(): "string",
pa.binary(): "binary",
pa.date32(): "date",
}
if arrow_type in type_mapping:
return type_mapping[arrow_type]
if pa.types.is_timestamp(arrow_type):
if arrow_type.tz:
return "timestamptz"
return "timestamp"
if pa.types.is_decimal(arrow_type):
return f"decimal({arrow_type.precision},{arrow_type.scale})"
if pa.types.is_list(arrow_type):
inner = self._arrow_to_iceberg_type(arrow_type.value_type)
return f"list<{inner}>"
return "string"
def _save_schema_snapshot(self, arrow_schema: pa.Schema) -> None:
"""Save schema information for restore validation."""
archive_path = self._generate_archive_path()
columns = self.schema_inspector.get_table_columns(
self.archive_config.schema_name,
self.archive_config.table_name
)
pk_columns = self.schema_inspector.get_primary_key_columns(
self.archive_config.schema_name,
self.archive_config.table_name
)
schema_snapshot = {
"source_table": {
"schema": self.archive_config.schema_name,
"table": self.archive_config.table_name
},
"columns": columns,
"primary_key_columns": pk_columns,
"arrow_schema": arrow_schema.to_string(),
"archived_at": datetime.utcnow().isoformat()
}
self.s3_client.put_object(
Bucket=self.s3_config.bucket,
Key=f"{archive_path}/schema_snapshot.json",
Body=json.dumps(schema_snapshot, indent=2, default=str),
ContentType="application/json"
)
def archive(self) -> Dict[str, Any]:
"""Execute the archive operation."""
logger.info(
f"Starting archive of {self.archive_config.schema_name}."
f"{self.archive_config.table_name} "
f"partition {self.archive_config.partition_column}="
f"{self.archive_config.partition_value}"
)
arrow_schema = self.schema_inspector.build_arrow_schema(
self.archive_config.schema_name,
self.archive_config.table_name
)
self._save_schema_snapshot(arrow_schema)
data_files = []
total_records = 0
file_number = 0
for batch_df in self._stream_partition_data():
table = pa.Table.from_pandas(batch_df, schema=arrow_schema)
file_meta = self._write_parquet_to_s3(table, file_number, arrow_schema)
data_files.append(file_meta)
total_records += file_meta["record_count"]
file_number += 1
logger.info(
f"Written file {file_number}: {file_meta['record_count']} records"
)
self._write_iceberg_metadata(arrow_schema, data_files, total_records)
result = {
"status": "success",
"table": f"{self.archive_config.schema_name}.{self.archive_config.table_name}",
"partition": f"{self.archive_config.partition_column}={self.archive_config.partition_value}",
"location": f"s3://{self.s3_config.bucket}/{self._generate_archive_path()}",
"total_records": total_records,
"total_files": len(data_files),
"total_bytes": sum(f["file_size_bytes"] for f in data_files),
"archived_at": datetime.utcnow().isoformat()
}
logger.info(f"Archive complete: {total_records} records in {len(data_files)} files")
return result
def main():
parser = argparse.ArgumentParser(
description="Archive Aurora PostgreSQL partition to S3"
)
parser.add_argument("--table", required=True, help="Table name")
parser.add_argument("--partition-column", required=True, help="Partition column name")
parser.add_argument("--partition-value", required=True, help="Partition value to archive")
parser.add_argument("--schema", default="public", help="Schema name")
parser.add_argument("--batch-size", type=int, default=100000, help="Batch size for streaming")
args = parser.parse_args()
db_config = DatabaseConfig.from_environment()
s3_config = S3Config.from_environment()
archive_config = ArchiveConfig(
table_name=args.table,
partition_column=args.partition_column,
partition_value=args.partition_value,
schema_name=args.schema,
batch_size=args.batch_size
)
archiver = PartitionArchiver(db_config, s3_config, archive_config)
result = archiver.archive()
print(json.dumps(result, indent=2))
return 0
if __name__ == "__main__":
sys.exit(main())4. The Restore Script
This script reverses the archive operation by reading Parquet files from S3 and loading them into a staging table.
4.1 Restore Script
#!/usr/bin/env python3
# restore_partition.py
"""
Restore an archived partition from S3 back to Aurora PostgreSQL.
Usage:
python restore_partition.py \
--source-path s3://bucket/prefix/schema/table/partition_col=value \
--target-table transactions_staging \
--target-schema public
"""
import argparse
import json
import logging
import sys
from datetime import datetime
from typing import Dict, Any, List, Optional
from urllib.parse import urlparse
import boto3
import pandas as pd
import psycopg2
from psycopg2 import sql
from psycopg2.extras import execute_values
import pyarrow.parquet as pq
from config import DatabaseConfig
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(message)s"
)
logger = logging.getLogger(__name__)
class PartitionRestorer:
"""Restores archived partitions from S3 to PostgreSQL."""
def __init__(
self,
db_config: DatabaseConfig,
source_path: str,
target_schema: str,
target_table: str,
create_table: bool = True,
batch_size: int = 10000
):
self.db_config = db_config
self.source_path = source_path
self.target_schema = target_schema
self.target_table = target_table
self.create_table = create_table
self.batch_size = batch_size
parsed = urlparse(source_path)
self.bucket = parsed.netloc
self.prefix = parsed.path.lstrip("/")
self.s3_client = boto3.client("s3")
def _load_schema_snapshot(self) -> Dict[str, Any]:
"""Load the schema snapshot from the archive."""
response = self.s3_client.get_object(
Bucket=self.bucket,
Key=f"{self.prefix}/schema_snapshot.json"
)
return json.loads(response["Body"].read())
def _load_iceberg_metadata(self) -> Dict[str, Any]:
"""Load Iceberg metadata."""
response = self.s3_client.get_object(
Bucket=self.bucket,
Key=f"{self.prefix}/metadata/v1.metadata.json"
)
return json.loads(response["Body"].read())
def _list_data_files(self) -> List[str]:
"""List all Parquet data files in the archive."""
data_prefix = f"{self.prefix}/data/"
files = []
paginator = self.s3_client.get_paginator("list_objects_v2")
for page in paginator.paginate(Bucket=self.bucket, Prefix=data_prefix):
for obj in page.get("Contents", []):
if obj["Key"].endswith(".parquet"):
files.append(obj["Key"])
return sorted(files)
def _postgres_type_from_column_def(self, col: Dict[str, Any]) -> str:
"""Convert column definition to PostgreSQL type."""
data_type = col["data_type"]
if data_type == "character varying":
max_len = col.get("character_maximum_length")
if max_len:
return f"varchar({max_len})"
return "text"
if data_type == "numeric":
precision = col.get("numeric_precision")
scale = col.get("numeric_scale")
if precision and scale:
return f"numeric({precision},{scale})"
return "numeric"
return data_type
def _create_staging_table(
self,
schema_snapshot: Dict[str, Any],
conn: psycopg2.extensions.connection
) -> None:
"""Create the staging table based on archived schema."""
columns = schema_snapshot["columns"]
column_defs = []
for col in columns:
pg_type = self._postgres_type_from_column_def(col)
nullable = "" if col["is_nullable"] == "YES" else " NOT NULL"
column_defs.append(f' "{col["column_name"]}" {pg_type}{nullable}')
create_sql = f"""
DROP TABLE IF EXISTS {self.target_schema}.{self.target_table};
CREATE TABLE {self.target_schema}.{self.target_table} (
{chr(10).join(column_defs)}
)
"""
with conn.cursor() as cur:
cur.execute(create_sql)
conn.commit()
logger.info(f"Created staging table {self.target_schema}.{self.target_table}")
def _insert_batch(
self,
df: pd.DataFrame,
columns: List[str],
conn: psycopg2.extensions.connection
) -> int:
"""Insert a batch of records into the staging table."""
if df.empty:
return 0
for col in df.columns:
if pd.api.types.is_datetime64_any_dtype(df[col]):
df[col] = df[col].apply(
lambda x: x.isoformat() if pd.notna(x) else None
)
values = [tuple(row) for row in df[columns].values]
column_names = ", ".join(f'"{c}"' for c in columns)
insert_sql = f"""
INSERT INTO {self.target_schema}.{self.target_table} ({column_names})
VALUES %s
"""
with conn.cursor() as cur:
execute_values(cur, insert_sql, values, page_size=self.batch_size)
return len(values)
def restore(self) -> Dict[str, Any]:
"""Execute the restore operation."""
logger.info(f"Starting restore from {self.source_path}")
schema_snapshot = self._load_schema_snapshot()
metadata = self._load_iceberg_metadata()
data_files = self._list_data_files()
logger.info(f"Found {len(data_files)} data files to restore")
columns = [col["column_name"] for col in schema_snapshot["columns"]]
with psycopg2.connect(self.db_config.connection_string) as conn:
if self.create_table:
self._create_staging_table(schema_snapshot, conn)
total_records = 0
for file_key in data_files:
s3_uri = f"s3://{self.bucket}/{file_key}"
logger.info(f"Restoring from {file_key}")
response = self.s3_client.get_object(Bucket=self.bucket, Key=file_key)
table = pq.read_table(response["Body"])
df = table.to_pandas()
file_records = 0
for start in range(0, len(df), self.batch_size):
batch_df = df.iloc[start:start + self.batch_size]
inserted = self._insert_batch(batch_df, columns, conn)
file_records += inserted
conn.commit()
total_records += file_records
logger.info(f"Restored {file_records} records from {file_key}")
result = {
"status": "success",
"source": self.source_path,
"target": f"{self.target_schema}.{self.target_table}",
"total_records": total_records,
"files_processed": len(data_files),
"restored_at": datetime.utcnow().isoformat()
}
logger.info(f"Restore complete: {total_records} records")
return result
def main():
parser = argparse.ArgumentParser(
description="Restore archived partition from S3 to PostgreSQL"
)
parser.add_argument("--source-path", required=True, help="S3 path to archived partition")
parser.add_argument("--target-table", required=True, help="Target table name")
parser.add_argument("--target-schema", default="public", help="Target schema name")
parser.add_argument("--batch-size", type=int, default=10000, help="Insert batch size")
parser.add_argument("--no-create", action="store_true", help="Don't create table, assume it exists")
args = parser.parse_args()
db_config = DatabaseConfig.from_environment()
restorer = PartitionRestorer(
db_config=db_config,
source_path=args.source_path,
target_schema=args.target_schema,
target_table=args.target_table,
create_table=not args.no_create,
batch_size=args.batch_size
)
result = restorer.restore()
print(json.dumps(result, indent=2))
return 0
if __name__ == "__main__":
sys.exit(main())5. SQL Operations for Partition Migration
Once data is restored to a staging table, you need SQL operations to validate and migrate it to the main table.
5.1 Schema Validation
-- Validate that staging table schema matches the main table
CREATE OR REPLACE FUNCTION validate_table_schemas(
p_source_schema TEXT,
p_source_table TEXT,
p_target_schema TEXT,
p_target_table TEXT
) RETURNS TABLE (
validation_type TEXT,
column_name TEXT,
source_value TEXT,
target_value TEXT,
is_valid BOOLEAN
) AS $$
BEGIN
-- Check column count
RETURN QUERY
SELECT
'column_count'::TEXT,
NULL::TEXT,
src.cnt::TEXT,
tgt.cnt::TEXT,
src.cnt = tgt.cnt
FROM
(SELECT COUNT(*)::INT AS cnt
FROM information_schema.columns
WHERE table_schema = p_source_schema
AND table_name = p_source_table) src,
(SELECT COUNT(*)::INT AS cnt
FROM information_schema.columns
WHERE table_schema = p_target_schema
AND table_name = p_target_table) tgt;
-- Check each column exists with matching type
RETURN QUERY
SELECT
'column_definition'::TEXT,
src.column_name,
src.data_type || COALESCE('(' || src.character_maximum_length::TEXT || ')', ''),
COALESCE(tgt.data_type || COALESCE('(' || tgt.character_maximum_length::TEXT || ')', ''), 'MISSING'),
src.data_type = COALESCE(tgt.data_type, '')
AND COALESCE(src.character_maximum_length, 0) = COALESCE(tgt.character_maximum_length, 0)
FROM
information_schema.columns src
LEFT JOIN
information_schema.columns tgt
ON tgt.table_schema = p_target_schema
AND tgt.table_name = p_target_table
AND tgt.column_name = src.column_name
WHERE
src.table_schema = p_source_schema
AND src.table_name = p_source_table
ORDER BY src.ordinal_position;
-- Check nullability
RETURN QUERY
SELECT
'nullability'::TEXT,
src.column_name,
src.is_nullable,
COALESCE(tgt.is_nullable, 'MISSING'),
src.is_nullable = COALESCE(tgt.is_nullable, '')
FROM
information_schema.columns src
LEFT JOIN
information_schema.columns tgt
ON tgt.table_schema = p_target_schema
AND tgt.table_name = p_target_table
AND tgt.column_name = src.column_name
WHERE
src.table_schema = p_source_schema
AND src.table_name = p_source_table
ORDER BY src.ordinal_position;
END;
$$ LANGUAGE plpgsql;
-- Usage
SELECT * FROM validate_table_schemas('public', 'transactions_staging', 'public', 'transactions');5.2 Comprehensive Validation Report
-- Generate a full validation report before migration
CREATE OR REPLACE FUNCTION generate_migration_report(
p_staging_schema TEXT,
p_staging_table TEXT,
p_target_schema TEXT,
p_target_table TEXT,
p_partition_column TEXT,
p_partition_value TEXT
) RETURNS TABLE (
check_name TEXT,
result TEXT,
details JSONB
) AS $$
DECLARE
v_staging_count BIGINT;
v_existing_count BIGINT;
v_schema_valid BOOLEAN;
BEGIN
-- Get staging table count
EXECUTE format(
'SELECT COUNT(*) FROM %I.%I',
p_staging_schema, p_staging_table
) INTO v_staging_count;
RETURN QUERY SELECT
'staging_record_count'::TEXT,
'INFO'::TEXT,
jsonb_build_object('count', v_staging_count);
-- Check for existing data in target partition
BEGIN
EXECUTE format(
'SELECT COUNT(*) FROM %I.%I WHERE %I = $1',
p_target_schema, p_target_table, p_partition_column
) INTO v_existing_count USING p_partition_value;
IF v_existing_count > 0 THEN
RETURN QUERY SELECT
'existing_partition_data'::TEXT,
'WARNING'::TEXT,
jsonb_build_object(
'count', v_existing_count,
'message', 'Target partition already contains data'
);
ELSE
RETURN QUERY SELECT
'existing_partition_data'::TEXT,
'OK'::TEXT,
jsonb_build_object('count', 0);
END IF;
EXCEPTION WHEN undefined_column THEN
RETURN QUERY SELECT
'partition_column_check'::TEXT,
'ERROR'::TEXT,
jsonb_build_object(
'message', format('Partition column %s not found', p_partition_column)
);
END;
-- Validate schemas match
SELECT bool_and(is_valid) INTO v_schema_valid
FROM validate_table_schemas(
p_staging_schema, p_staging_table,
p_target_schema, p_target_table
);
RETURN QUERY SELECT
'schema_validation'::TEXT,
CASE WHEN v_schema_valid THEN 'OK' ELSE 'ERROR' END::TEXT,
jsonb_build_object('schemas_match', v_schema_valid);
-- Check for null values in NOT NULL columns
RETURN QUERY
SELECT
'null_check_' || c.column_name,
CASE WHEN null_count > 0 THEN 'ERROR' ELSE 'OK' END,
jsonb_build_object('null_count', null_count)
FROM information_schema.columns c
CROSS JOIN LATERAL (
SELECT COUNT(*) as null_count
FROM (
SELECT 1
FROM information_schema.columns ic
WHERE ic.table_schema = p_staging_schema
AND ic.table_name = p_staging_table
AND ic.column_name = c.column_name
) x
) nc
WHERE c.table_schema = p_target_schema
AND c.table_name = p_target_table
AND c.is_nullable = 'NO';
END;
$$ LANGUAGE plpgsql;
-- Usage
SELECT * FROM generate_migration_report(
'public', 'transactions_staging',
'public', 'transactions',
'transaction_date', '2024-01'
);5.3 Partition Migration
-- Migrate data from staging table to main table
CREATE OR REPLACE PROCEDURE migrate_partition_data(
p_staging_schema TEXT,
p_staging_table TEXT,
p_target_schema TEXT,
p_target_table TEXT,
p_partition_column TEXT,
p_partition_value TEXT,
p_delete_existing BOOLEAN DEFAULT FALSE,
p_batch_size INTEGER DEFAULT 50000
)
LANGUAGE plpgsql
AS $$
DECLARE
v_columns TEXT;
v_total_migrated BIGINT := 0;
v_batch_migrated BIGINT;
v_validation_passed BOOLEAN;
BEGIN
-- Validate schemas match
SELECT bool_and(is_valid) INTO v_validation_passed
FROM validate_table_schemas(
p_staging_schema, p_staging_table,
p_target_schema, p_target_table
);
IF NOT v_validation_passed THEN
RAISE EXCEPTION 'Schema validation failed. Run validate_table_schemas() for details.';
END IF;
-- Build column list
SELECT string_agg(quote_ident(column_name), ', ' ORDER BY ordinal_position)
INTO v_columns
FROM information_schema.columns
WHERE table_schema = p_staging_schema
AND table_name = p_staging_table;
-- Delete existing data if requested
IF p_delete_existing THEN
EXECUTE format(
'DELETE FROM %I.%I WHERE %I = $1',
p_target_schema, p_target_table, p_partition_column
) USING p_partition_value;
RAISE NOTICE 'Deleted existing data for partition % = %',
p_partition_column, p_partition_value;
END IF;
-- Migrate in batches using a cursor approach
LOOP
EXECUTE format($sql$
WITH to_migrate AS (
SELECT ctid
FROM %I.%I
WHERE NOT EXISTS (
SELECT 1 FROM %I.%I t
WHERE t.%I = $1
)
LIMIT $2
),
inserted AS (
INSERT INTO %I.%I (%s)
SELECT %s
FROM %I.%I s
WHERE s.ctid IN (SELECT ctid FROM to_migrate)
RETURNING 1
)
SELECT COUNT(*) FROM inserted
$sql$,
p_staging_schema, p_staging_table,
p_target_schema, p_target_table, p_partition_column,
p_target_schema, p_target_table, v_columns,
v_columns,
p_staging_schema, p_staging_table
) INTO v_batch_migrated USING p_partition_value, p_batch_size;
v_total_migrated := v_total_migrated + v_batch_migrated;
IF v_batch_migrated = 0 THEN
EXIT;
END IF;
RAISE NOTICE 'Migrated batch: % records (total: %)', v_batch_migrated, v_total_migrated;
COMMIT;
END LOOP;
RAISE NOTICE 'Migration complete. Total records migrated: %', v_total_migrated;
END;
$$;
-- Usage
CALL migrate_partition_data(
'public', 'transactions_staging',
'public', 'transactions',
'transaction_date', '2024-01',
TRUE, -- delete existing
50000 -- batch size
);5.4 Attach Partition (for Partitioned Tables)
-- For natively partitioned tables, attach the staging table as a partition
CREATE OR REPLACE PROCEDURE attach_restored_partition(
p_staging_schema TEXT,
p_staging_table TEXT,
p_target_schema TEXT,
p_target_table TEXT,
p_partition_column TEXT,
p_partition_start TEXT,
p_partition_end TEXT
)
LANGUAGE plpgsql
AS $$
DECLARE
v_partition_name TEXT;
v_constraint_name TEXT;
BEGIN
-- Validate schemas match
IF NOT (
SELECT bool_and(is_valid)
FROM validate_table_schemas(
p_staging_schema, p_staging_table,
p_target_schema, p_target_table
)
) THEN
RAISE EXCEPTION 'Schema validation failed';
END IF;
-- Add constraint to staging table that matches partition bounds
v_constraint_name := p_staging_table || '_partition_check';
EXECUTE format($sql$
ALTER TABLE %I.%I
ADD CONSTRAINT %I
CHECK (%I >= %L AND %I < %L)
$sql$,
p_staging_schema, p_staging_table,
v_constraint_name,
p_partition_column, p_partition_start,
p_partition_column, p_partition_end
);
-- Validate constraint without locking
EXECUTE format($sql$
ALTER TABLE %I.%I
VALIDATE CONSTRAINT %I
$sql$,
p_staging_schema, p_staging_table,
v_constraint_name
);
-- Detach old partition if exists
v_partition_name := p_target_table || '_' || replace(p_partition_start, '-', '_');
BEGIN
EXECUTE format($sql$
ALTER TABLE %I.%I
DETACH PARTITION %I.%I
$sql$,
p_target_schema, p_target_table,
p_target_schema, v_partition_name
);
RAISE NOTICE 'Detached existing partition %', v_partition_name;
EXCEPTION WHEN undefined_table THEN
RAISE NOTICE 'No existing partition to detach';
END;
-- Rename staging table to partition name
EXECUTE format($sql$
ALTER TABLE %I.%I RENAME TO %I
$sql$,
p_staging_schema, p_staging_table,
v_partition_name
);
-- Attach as partition
EXECUTE format($sql$
ALTER TABLE %I.%I
ATTACH PARTITION %I.%I
FOR VALUES FROM (%L) TO (%L)
$sql$,
p_target_schema, p_target_table,
p_staging_schema, v_partition_name,
p_partition_start, p_partition_end
);
RAISE NOTICE 'Successfully attached partition % to %',
v_partition_name, p_target_table;
END;
$$;
-- Usage for range partitioned table
CALL attach_restored_partition(
'public', 'transactions_staging',
'public', 'transactions',
'transaction_date',
'2024-01-01', '2024-02-01'
);5.5 Cleanup Script
-- Clean up after successful migration
CREATE OR REPLACE PROCEDURE cleanup_after_migration(
p_staging_schema TEXT,
p_staging_table TEXT,
p_verify_target_schema TEXT DEFAULT NULL,
p_verify_target_table TEXT DEFAULT NULL,
p_verify_count BOOLEAN DEFAULT TRUE
)
LANGUAGE plpgsql
AS $$
DECLARE
v_staging_count BIGINT;
v_target_count BIGINT;
BEGIN
IF p_verify_count AND p_verify_target_schema IS NOT NULL THEN
EXECUTE format(
'SELECT COUNT(*) FROM %I.%I',
p_staging_schema, p_staging_table
) INTO v_staging_count;
EXECUTE format(
'SELECT COUNT(*) FROM %I.%I',
p_verify_target_schema, p_verify_target_table
) INTO v_target_count;
IF v_target_count < v_staging_count THEN
RAISE WARNING 'Target count (%) is less than staging count (%). Migration may be incomplete.',
v_target_count, v_staging_count;
RETURN;
END IF;
END IF;
EXECUTE format(
'DROP TABLE IF EXISTS %I.%I',
p_staging_schema, p_staging_table
);
RAISE NOTICE 'Dropped staging table %.%', p_staging_schema, p_staging_table;
END;
$$;
-- Usage
CALL cleanup_after_migration(
'public', 'transactions_staging',
'public', 'transactions',
TRUE
);6. Spring Boot Query API
This API allows querying archived data directly from S3 without restoring to the database.
6.1 Project Structure
src/main/java/com/example/archivequery/
ArchiveQueryApplication.java
config/
AwsConfig.java
ParquetConfig.java
controller/
ArchiveQueryController.java
service/
ParquetQueryService.java
PredicateParser.java
model/
QueryRequest.java
QueryResponse.java
ArchiveMetadata.java
predicate/
Predicate.java
ComparisonPredicate.java
LogicalPredicate.java
PredicateEvaluator.java6.2 Application Configuration
// ArchiveQueryApplication.java
package com.example.archivequery;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ArchiveQueryApplication {
public static void main(String[] args) {
SpringApplication.run(ArchiveQueryApplication.class, args);
}
}6.3 AWS Configuration
// config/AwsConfig.java
package com.example.archivequery.config;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.s3.S3Client;
@Configuration
public class AwsConfig {
@Value("${aws.region:eu-west-1}")
private String region;
@Bean
public S3Client s3Client() {
return S3Client.builder()
.region(Region.of(region))
.credentialsProvider(DefaultCredentialsProvider.create())
.build();
}
}6.4 Parquet Configuration
// config/ParquetConfig.java
package com.example.archivequery.config;
import org.apache.hadoop.conf.Configuration;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
@org.springframework.context.annotation.Configuration
public class ParquetConfig {
@Value("${aws.region:eu-west-1}")
private String region;
@Bean
public Configuration hadoopConfiguration() {
Configuration conf = new Configuration();
conf.set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem");
conf.set("fs.s3a.aws.credentials.provider",
"com.amazonaws.auth.DefaultAWSCredentialsProviderChain");
conf.set("fs.s3a.endpoint.region", region);
return conf;
}
}6.5 Model Classes
// model/QueryRequest.java
package com.example.archivequery.model;
import java.util.List;
import java.util.Map;
public record QueryRequest(
String archivePath,
List<String> columns,
Map<String, Object> filters,
String filterExpression,
Integer limit,
Integer offset
) {
public QueryRequest {
if (limit == null) limit = 1000;
if (offset == null) offset = 0;
}
}// model/QueryResponse.java
package com.example.archivequery.model;
import java.util.List;
import java.util.Map;
public record QueryResponse(
List<Map<String, Object>> data,
long totalMatched,
long totalScanned,
long executionTimeMs,
Map<String, String> schema,
String archivePath
) {}// model/ArchiveMetadata.java
package com.example.archivequery.model;
import java.time.Instant;
import java.util.List;
import java.util.Map;
public record ArchiveMetadata(
String tableUuid,
String location,
List<ColumnDefinition> columns,
Map<String, String> properties,
Instant archivedAt
) {
public record ColumnDefinition(
int id,
String name,
String type,
boolean required
) {}
}6.6 Predicate Classes
// predicate/Predicate.java
package com.example.archivequery.predicate;
import java.util.Map;
public sealed interface Predicate
permits ComparisonPredicate, LogicalPredicate {
boolean evaluate(Map<String, Object> record);
}// predicate/ComparisonPredicate.java
package com.example.archivequery.predicate;
import java.math.BigDecimal;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.util.Map;
import java.util.Objects;
public record ComparisonPredicate(
String column,
Operator operator,
Object value
) implements Predicate {
public enum Operator {
EQ, NE, GT, GE, LT, LE, LIKE, IN, IS_NULL, IS_NOT_NULL
}
@Override
public boolean evaluate(Map<String, Object> record) {
Object recordValue = record.get(column);
return switch (operator) {
case IS_NULL -> recordValue == null;
case IS_NOT_NULL -> recordValue != null;
case EQ -> Objects.equals(recordValue, convertValue(recordValue));
case NE -> !Objects.equals(recordValue, convertValue(recordValue));
case GT -> compare(recordValue, convertValue(recordValue)) > 0;
case GE -> compare(recordValue, convertValue(recordValue)) >= 0;
case LT -> compare(recordValue, convertValue(recordValue)) < 0;
case LE -> compare(recordValue, convertValue(recordValue)) <= 0;
case LIKE -> matchesLike(recordValue);
case IN -> matchesIn(recordValue);
};
}
private Object convertValue(Object recordValue) {
if (recordValue == null || value == null) return value;
if (recordValue instanceof LocalDate && value instanceof String s) {
return LocalDate.parse(s);
}
if (recordValue instanceof LocalDateTime && value instanceof String s) {
return LocalDateTime.parse(s);
}
if (recordValue instanceof BigDecimal && value instanceof Number n) {
return new BigDecimal(n.toString());
}
if (recordValue instanceof Long && value instanceof Number n) {
return n.longValue();
}
if (recordValue instanceof Integer && value instanceof Number n) {
return n.intValue();
}
if (recordValue instanceof Double && value instanceof Number n) {
return n.doubleValue();
}
return value;
}
@SuppressWarnings({"unchecked", "rawtypes"})
private int compare(Object a, Object b) {
if (a == null || b == null) return 0;
if (a instanceof Comparable ca && b instanceof Comparable cb) {
return ca.compareTo(cb);
}
return 0;
}
private boolean matchesLike(Object recordValue) {
if (recordValue == null || value == null) return false;
String pattern = value.toString()
.replace("%", ".*")
.replace("_", ".");
return recordValue.toString().matches(pattern);
}
private boolean matchesIn(Object recordValue) {
if (recordValue == null || value == null) return false;
if (value instanceof Iterable<?> iterable) {
for (Object item : iterable) {
if (Objects.equals(recordValue, item)) return true;
}
}
return false;
}
}// predicate/LogicalPredicate.java
package com.example.archivequery.predicate;
import java.util.List;
import java.util.Map;
public record LogicalPredicate(
Operator operator,
List<Predicate> predicates
) implements Predicate {
public enum Operator {
AND, OR, NOT
}
@Override
public boolean evaluate(Map<String, Object> record) {
return switch (operator) {
case AND -> predicates.stream().allMatch(p -> p.evaluate(record));
case OR -> predicates.stream().anyMatch(p -> p.evaluate(record));
case NOT -> !predicates.getFirst().evaluate(record);
};
}
}// predicate/PredicateEvaluator.java
package com.example.archivequery.predicate;
import java.util.Map;
public class PredicateEvaluator {
private final Predicate predicate;
public PredicateEvaluator(Predicate predicate) {
this.predicate = predicate;
}
public boolean matches(Map<String, Object> record) {
if (predicate == null) return true;
return predicate.evaluate(record);
}
}6.7 Predicate Parser
// service/PredicateParser.java
package com.example.archivequery.service;
import com.example.archivequery.predicate.*;
import org.springframework.stereotype.Service;
import java.util.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
@Service
public class PredicateParser {
private static final Pattern COMPARISON_PATTERN = Pattern.compile(
"(\\w+)\\s*(=|!=|<>|>=|<=|>|<|LIKE|IN|IS NULL|IS NOT NULL)\\s*(.*)?"
);
public Predicate parse(String expression) {
if (expression == null || expression.isBlank()) {
return null;
}
return parseExpression(expression.trim());
}
public Predicate fromFilters(Map<String, Object> filters) {
if (filters == null || filters.isEmpty()) {
return null;
}
List<Predicate> predicates = new ArrayList<>();
for (Map.Entry<String, Object> entry : filters.entrySet()) {
String key = entry.getKey();
Object value = entry.getValue();
if (key.endsWith("_gt")) {
predicates.add(new ComparisonPredicate(
key.substring(0, key.length() - 3),
ComparisonPredicate.Operator.GT,
value
));
} else if (key.endsWith("_gte")) {
predicates.add(new ComparisonPredicate(
key.substring(0, key.length() - 4),
ComparisonPredicate.Operator.GE,
value
));
} else if (key.endsWith("_lt")) {
predicates.add(new ComparisonPredicate(
key.substring(0, key.length() - 3),
ComparisonPredicate.Operator.LT,
value
));
} else if (key.endsWith("_lte")) {
predicates.add(new ComparisonPredicate(
key.substring(0, key.length() - 4),
ComparisonPredicate.Operator.LE,
value
));
} else if (key.endsWith("_ne")) {
predicates.add(new ComparisonPredicate(
key.substring(0, key.length() - 3),
ComparisonPredicate.Operator.NE,
value
));
} else if (key.endsWith("_like")) {
predicates.add(new ComparisonPredicate(
key.substring(0, key.length() - 5),
ComparisonPredicate.Operator.LIKE,
value
));
} else if (key.endsWith("_in") && value instanceof List<?> list) {
predicates.add(new ComparisonPredicate(
key.substring(0, key.length() - 3),
ComparisonPredicate.Operator.IN,
list
));
} else {
predicates.add(new ComparisonPredicate(
key,
ComparisonPredicate.Operator.EQ,
value
));
}
}
if (predicates.size() == 1) {
return predicates.getFirst();
}
return new LogicalPredicate(LogicalPredicate.Operator.AND, predicates);
}
private Predicate parseExpression(String expression) {
String upper = expression.toUpperCase();
int andIndex = findLogicalOperator(upper, " AND ");
if (andIndex > 0) {
String left = expression.substring(0, andIndex);
String right = expression.substring(andIndex + 5);
return new LogicalPredicate(
LogicalPredicate.Operator.AND,
List.of(parseExpression(left), parseExpression(right))
);
}
int orIndex = findLogicalOperator(upper, " OR ");
if (orIndex > 0) {
String left = expression.substring(0, orIndex);
String right = expression.substring(orIndex + 4);
return new LogicalPredicate(
LogicalPredicate.Operator.OR,
List.of(parseExpression(left), parseExpression(right))
);
}
if (upper.startsWith("NOT ")) {
return new LogicalPredicate(
LogicalPredicate.Operator.NOT,
List.of(parseExpression(expression.substring(4)))
);
}
if (expression.startsWith("(") && expression.endsWith(")")) {
return parseExpression(expression.substring(1, expression.length() - 1));
}
return parseComparison(expression);
}
private int findLogicalOperator(String expression, String operator) {
int depth = 0;
int index = 0;
while (index < expression.length()) {
char c = expression.charAt(index);
if (c == '(') depth++;
else if (c == ')') depth--;
else if (depth == 0 && expression.substring(index).startsWith(operator)) {
return index;
}
index++;
}
return -1;
}
private Predicate parseComparison(String expression) {
Matcher matcher = COMPARISON_PATTERN.matcher(expression.trim());
if (!matcher.matches()) {
throw new IllegalArgumentException("Invalid expression: " + expression);
}
String column = matcher.group(1);
String operatorStr = matcher.group(2).toUpperCase();
String valueStr = matcher.group(3);
ComparisonPredicate.Operator operator = switch (operatorStr) {
case "=" -> ComparisonPredicate.Operator.EQ;
case "!=", "<>" -> ComparisonPredicate.Operator.NE;
case ">" -> ComparisonPredicate.Operator.GT;
case ">=" -> ComparisonPredicate.Operator.GE;
case "<" -> ComparisonPredicate.Operator.LT;
case "<=" -> ComparisonPredicate.Operator.LE;
case "LIKE" -> ComparisonPredicate.Operator.LIKE;
case "IN" -> ComparisonPredicate.Operator.IN;
case "IS NULL" -> ComparisonPredicate.Operator.IS_NULL;
case "IS NOT NULL" -> ComparisonPredicate.Operator.IS_NOT_NULL;
default -> throw new IllegalArgumentException("Unknown operator: " + operatorStr);
};
Object value = parseValue(valueStr, operator);
return new ComparisonPredicate(column, operator, value);
}
private Object parseValue(String valueStr, ComparisonPredicate.Operator operator) {
if (operator == ComparisonPredicate.Operator.IS_NULL ||
operator == ComparisonPredicate.Operator.IS_NOT_NULL) {
return null;
}
if (valueStr == null || valueStr.isBlank()) {
return null;
}
valueStr = valueStr.trim();
if (valueStr.startsWith("'") && valueStr.endsWith("'")) {
return valueStr.substring(1, valueStr.length() - 1);
}
if (operator == ComparisonPredicate.Operator.IN) {
if (valueStr.startsWith("(") && valueStr.endsWith(")")) {
valueStr = valueStr.substring(1, valueStr.length() - 1);
}
return Arrays.stream(valueStr.split(","))
.map(String::trim)
.map(s -> s.startsWith("'") ? s.substring(1, s.length() - 1) : parseNumber(s))
.toList();
}
return parseNumber(valueStr);
}
private Object parseNumber(String s) {
try {
if (s.contains(".")) {
return Double.parseDouble(s);
}
return Long.parseLong(s);
} catch (NumberFormatException e) {
return s;
}
}
}6.8 Parquet Query Service
// service/ParquetQueryService.java
package com.example.archivequery.service;
import com.example.archivequery.model.*;
import com.example.archivequery.predicate.*;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.parquet.avro.AvroParquetReader;
import org.apache.parquet.hadoop.ParquetReader;
import org.apache.parquet.hadoop.util.HadoopInputFile;
import org.apache.avro.generic.GenericRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Service;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.model.*;
import java.io.IOException;
import java.net.URI;
import java.time.*;
import java.util.*;
import java.util.concurrent.*;
import java.util.stream.Collectors;
@Service
public class ParquetQueryService {
private static final Logger log = LoggerFactory.getLogger(ParquetQueryService.class);
private final S3Client s3Client;
private final Configuration hadoopConfig;
private final PredicateParser predicateParser;
private final ObjectMapper objectMapper;
private final ExecutorService executorService;
public ParquetQueryService(
S3Client s3Client,
Configuration hadoopConfig,
PredicateParser predicateParser
) {
this.s3Client = s3Client;
this.hadoopConfig = hadoopConfig;
this.predicateParser = predicateParser;
this.objectMapper = new ObjectMapper();
this.executorService = Executors.newFixedThreadPool(
Runtime.getRuntime().availableProcessors()
);
}
public QueryResponse query(QueryRequest request) {
long startTime = System.currentTimeMillis();
Predicate predicate = buildPredicate(request);
PredicateEvaluator evaluator = new PredicateEvaluator(predicate);
List<String> dataFiles = listDataFiles(request.archivePath());
List<Map<String, Object>> allResults = Collections.synchronizedList(new ArrayList<>());
long[] counters = new long[2];
List<Future<?>> futures = new ArrayList<>();
for (String dataFile : dataFiles) {
futures.add(executorService.submit(() -> {
try {
QueryFileResult result = queryFile(
dataFile,
request.columns(),
evaluator
);
synchronized (counters) {
counters[0] += result.matched();
counters[1] += result.scanned();
}
allResults.addAll(result.records());
} catch (IOException e) {
log.error("Error reading file: " + dataFile, e);
}
}));
}
for (Future<?> future : futures) {
try {
future.get();
} catch (InterruptedException | ExecutionException e) {
log.error("Error waiting for query completion", e);
}
}
List<Map<String, Object>> paginatedResults = allResults.stream()
.skip(request.offset())
.limit(request.limit())
.collect(Collectors.toList());
Map<String, String> schema = extractSchema(request.archivePath());
long executionTime = System.currentTimeMillis() - startTime;
return new QueryResponse(
paginatedResults,
counters[0],
counters[1],
executionTime,
schema,
request.archivePath()
);
}
public ArchiveMetadata getMetadata(String archivePath) {
try {
URI uri = URI.create(archivePath);
String bucket = uri.getHost();
String prefix = uri.getPath().substring(1);
GetObjectRequest getRequest = GetObjectRequest.builder()
.bucket(bucket)
.key(prefix + "/metadata/v1.metadata.json")
.build();
byte[] content = s3Client.getObjectAsBytes(getRequest).asByteArray();
Map<String, Object> metadata = objectMapper.readValue(content, Map.class);
List<Map<String, Object>> schemas = (List<Map<String, Object>>) metadata.get("schemas");
Map<String, Object> currentSchema = schemas.getFirst();
List<Map<String, Object>> fields = (List<Map<String, Object>>) currentSchema.get("fields");
List<ArchiveMetadata.ColumnDefinition> columns = fields.stream()
.map(f -> new ArchiveMetadata.ColumnDefinition(
((Number) f.get("id")).intValue(),
(String) f.get("name"),
(String) f.get("type"),
(Boolean) f.get("required")
))
.toList();
Map<String, String> properties = (Map<String, String>) metadata.get("properties");
String archivedAtStr = properties.get("archive.timestamp");
Instant archivedAt = archivedAtStr != null ?
Instant.parse(archivedAtStr) : Instant.now();
return new ArchiveMetadata(
(String) metadata.get("table_uuid"),
(String) metadata.get("location"),
columns,
properties,
archivedAt
);
} catch (Exception e) {
throw new RuntimeException("Failed to read archive metadata", e);
}
}
private Predicate buildPredicate(QueryRequest request) {
Predicate filterPredicate = predicateParser.fromFilters(request.filters());
Predicate expressionPredicate = predicateParser.parse(request.filterExpression());
if (filterPredicate == null) return expressionPredicate;
if (expressionPredicate == null) return filterPredicate;
return new LogicalPredicate(
LogicalPredicate.Operator.AND,
List.of(filterPredicate, expressionPredicate)
);
}
private List<String> listDataFiles(String archivePath) {
URI uri = URI.create(archivePath);
String bucket = uri.getHost();
String prefix = uri.getPath().substring(1) + "/data/";
ListObjectsV2Request listRequest = ListObjectsV2Request.builder()
.bucket(bucket)
.prefix(prefix)
.build();
List<String> files = new ArrayList<>();
ListObjectsV2Response response;
do {
response = s3Client.listObjectsV2(listRequest);
for (S3Object obj : response.contents()) {
if (obj.key().endsWith(".parquet")) {
files.add("s3a://" + bucket + "/" + obj.key());
}
}
listRequest = listRequest.toBuilder()
.continuationToken(response.nextContinuationToken())
.build();
} while (response.isTruncated());
return files;
}
private record QueryFileResult(
List<Map<String, Object>> records,
long matched,
long scanned
) {}
private QueryFileResult queryFile(
String filePath,
List<String> columns,
PredicateEvaluator evaluator
) throws IOException {
List<Map<String, Object>> results = new ArrayList<>();
long matched = 0;
long scanned = 0;
Path path = new Path(filePath);
HadoopInputFile inputFile = HadoopInputFile.fromPath(path, hadoopConfig);
try (ParquetReader<GenericRecord> reader = AvroParquetReader
.<GenericRecord>builder(inputFile)
.withConf(hadoopConfig)
.build()) {
GenericRecord record;
while ((record = reader.read()) != null) {
scanned++;
Map<String, Object> recordMap = recordToMap(record);
if (evaluator.matches(recordMap)) {
matched++;
if (columns != null && !columns.isEmpty()) {
Map<String, Object> projected = new LinkedHashMap<>();
for (String col : columns) {
if (recordMap.containsKey(col)) {
projected.put(col, recordMap.get(col));
}
}
results.add(projected);
} else {
results.add(recordMap);
}
}
}
}
return new QueryFileResult(results, matched, scanned);
}
private Map<String, Object> recordToMap(GenericRecord record) {
Map<String, Object> map = new LinkedHashMap<>();
for (org.apache.avro.Schema.Field field : record.getSchema().getFields()) {
String name = field.name();
Object value = record.get(name);
map.put(name, convertValue(value));
}
return map;
}
private Object convertValue(Object value) {
if (value == null) return null;
if (value instanceof org.apache.avro.util.Utf8) {
return value.toString();
}
if (value instanceof org.apache.avro.generic.GenericRecord nested) {
return recordToMap(nested);
}
if (value instanceof java.nio.ByteBuffer buffer) {
byte[] bytes = new byte[buffer.remaining()];
buffer.get(bytes);
return Base64.getEncoder().encodeToString(bytes);
}
if (value instanceof Integer i) {
return LocalDate.ofEpochDay(i);
}
if (value instanceof Long l && l > 1_000_000_000_000L) {
return LocalDateTime.ofInstant(
Instant.ofEpochMilli(l / 1000),
ZoneOffset.UTC
);
}
return value;
}
private Map<String, String> extractSchema(String archivePath) {
try {
ArchiveMetadata metadata = getMetadata(archivePath);
return metadata.columns().stream()
.collect(Collectors.toMap(
ArchiveMetadata.ColumnDefinition::name,
ArchiveMetadata.ColumnDefinition::type,
(a, b) -> a,
LinkedHashMap::new
));
} catch (Exception e) {
log.warn("Failed to extract schema", e);
return Collections.emptyMap();
}
}
}6.9 REST Controller
// controller/ArchiveQueryController.java
package com.example.archivequery.controller;
import com.example.archivequery.model.*;
import com.example.archivequery.service.ParquetQueryService;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.util.List;
import java.util.Map;
@RestController
@RequestMapping("/api/v1/archives")
public class ArchiveQueryController {
private final ParquetQueryService queryService;
public ArchiveQueryController(ParquetQueryService queryService) {
this.queryService = queryService;
}
@PostMapping("/query")
public ResponseEntity<QueryResponse> query(@RequestBody QueryRequest request) {
QueryResponse response = queryService.query(request);
return ResponseEntity.ok(response);
}
@GetMapping("/query")
public ResponseEntity<QueryResponse> queryGet(
@RequestParam String archivePath,
@RequestParam(required = false) List<String> columns,
@RequestParam(required = false) String filter,
@RequestParam(defaultValue = "1000") Integer limit,
@RequestParam(defaultValue = "0") Integer offset
) {
QueryRequest request = new QueryRequest(
archivePath,
columns,
null,
filter,
limit,
offset
);
QueryResponse response = queryService.query(request);
return ResponseEntity.ok(response);
}
@GetMapping("/metadata")
public ResponseEntity<ArchiveMetadata> getMetadata(
@RequestParam String archivePath
) {
ArchiveMetadata metadata = queryService.getMetadata(archivePath);
return ResponseEntity.ok(metadata);
}
@GetMapping("/schema/{schema}/{table}/{partitionValue}")
public ResponseEntity<ArchiveMetadata> getMetadataByTable(
@PathVariable String schema,
@PathVariable String table,
@PathVariable String partitionValue,
@RequestParam String bucket,
@RequestParam(defaultValue = "aurora-archives") String prefix
) {
String archivePath = String.format(
"s3://%s/%s/%s/%s/%s",
bucket, prefix, schema, table, partitionValue
);
ArchiveMetadata metadata = queryService.getMetadata(archivePath);
return ResponseEntity.ok(metadata);
}
@PostMapping("/query/{schema}/{table}/{partitionValue}")
public ResponseEntity<QueryResponse> queryByTable(
@PathVariable String schema,
@PathVariable String table,
@PathVariable String partitionValue,
@RequestParam String bucket,
@RequestParam(defaultValue = "aurora-archives") String prefix,
@RequestBody Map<String, Object> requestBody
) {
String archivePath = String.format(
"s3://%s/%s/%s/%s/%s",
bucket, prefix, schema, table, partitionValue
);
List<String> columns = requestBody.containsKey("columns") ?
(List<String>) requestBody.get("columns") : null;
Map<String, Object> filters = requestBody.containsKey("filters") ?
(Map<String, Object>) requestBody.get("filters") : null;
String filterExpression = requestBody.containsKey("filterExpression") ?
(String) requestBody.get("filterExpression") : null;
Integer limit = requestBody.containsKey("limit") ?
((Number) requestBody.get("limit")).intValue() : 1000;
Integer offset = requestBody.containsKey("offset") ?
((Number) requestBody.get("offset")).intValue() : 0;
QueryRequest request = new QueryRequest(
archivePath,
columns,
filters,
filterExpression,
limit,
offset
);
QueryResponse response = queryService.query(request);
return ResponseEntity.ok(response);
}
}6.10 Application Properties
# application.yml
server:
port: 8080
aws:
region: ${AWS_REGION:eu-west-1}
spring:
application:
name: archive-query-service
logging:
level:
com.example.archivequery: DEBUG
org.apache.parquet: WARN
org.apache.hadoop: WARN7. Usage Examples
7.1 Archive a Partition
# Set environment variables
export AURORA_HOST=your-cluster.cluster-xxxx.eu-west-1.rds.amazonaws.com
export AURORA_DATABASE=production
export AURORA_USER=admin
export AURORA_PASSWORD=your-password
export ARCHIVE_S3_BUCKET=my-archive-bucket
export ARCHIVE_S3_PREFIX=aurora-archives
export AWS_REGION=eu-west-1
# Archive January 2024 transactions
python archive_partition.py \
--table transactions \
--partition-column transaction_month \
--partition-value 2024-01 \
--schema public \
--batch-size 1000007.2 Query Archived Data via API
# Get archive metadata
curl -X GET "https://localhost:8080/api/v1/archives/metadata?archivePath=s3://my-archive-bucket/aurora-archives/public/transactions/transaction_month=2024-01"
# Query with filters (POST)
curl -X POST "https://localhost:8080/api/v1/archives/query" \
-H "Content-Type: application/json" \
-d '{
"archivePath": "s3://my-archive-bucket/aurora-archives/public/transactions/transaction_month=2024-01",
"columns": ["transaction_id", "customer_id", "amount", "transaction_date"],
"filters": {
"amount_gte": 1000,
"status": "completed"
},
"limit": 100,
"offset": 0
}'
# Query with expression filter (GET)
curl -X GET "https://localhost:8080/api/v1/archives/query" \
--data-urlencode "archivePath=s3://my-archive-bucket/aurora-archives/public/transactions/transaction_month=2024-01" \
--data-urlencode "filter=amount >= 1000 AND status = 'completed'" \
--data-urlencode "columns=transaction_id,customer_id,amount" \
--data-urlencode "limit=50"7.3 Restore Archived Data
# Restore to staging table
python restore_partition.py \
--source-path s3://my-archive-bucket/aurora-archives/public/transactions/transaction_month=2024-01 \
--target-table transactions_staging \
--target-schema public \
--batch-size 100007.4 Migrate to Main Table
-- Validate before migration
SELECT * FROM generate_migration_report(
'public', 'transactions_staging',
'public', 'transactions',
'transaction_month', '2024-01'
);
-- Migrate data
CALL migrate_partition_data(
'public', 'transactions_staging',
'public', 'transactions',
'transaction_month', '2024-01',
TRUE, -- delete existing data in partition
50000 -- batch size
);
-- Clean up staging table
CALL cleanup_after_migration(
'public', 'transactions_staging',
'public', 'transactions',
TRUE -- verify counts
);8. Operational Considerations
8.1 Cost Analysis
The cost savings from this approach are significant:
| Storage Type | Monthly Cost per TB |
|---|---|
| Aurora PostgreSQL | $230 |
| S3 Standard | $23 |
| S3 Intelligent Tiering | $23 (hot) to $4 (archive) |
| S3 Glacier Instant Retrieval | $4 |
For a 10TB historical dataset:
- Aurora: $2,300/month
- S3 with Parquet (7:1 compression): ~$33/month
- Savings: ~98.5%
8.2 Query Performance
The Spring Boot API performance depends on:
- Data file size: Smaller files (100MB to 250MB) enable better parallelism
- Predicate selectivity: Higher selectivity means fewer records to deserialise
- Column projection: Requesting fewer columns reduces I/O
- S3 latency: Use same region as the bucket
Expected performance for a 1TB partition (compressed to ~150GB Parquet):
| Query Type | Typical Latency |
|---|---|
| Point lookup (indexed column) | 500ms to 2s |
| Range scan (10% selectivity) | 5s to 15s |
| Full scan with aggregation | 30s to 60s |
8.3 Monitoring and Alerting
Implement these CloudWatch metrics for production use:
@Component
public class QueryMetrics {
private final MeterRegistry meterRegistry;
public void recordQuery(QueryResponse response) {
meterRegistry.counter("archive.query.count").increment();
meterRegistry.timer("archive.query.duration")
.record(response.executionTimeMs(), TimeUnit.MILLISECONDS);
meterRegistry.gauge("archive.query.records_scanned", response.totalScanned());
meterRegistry.gauge("archive.query.records_matched", response.totalMatched());
}
}9. Conclusion
This solution provides a complete data lifecycle management approach for large Aurora PostgreSQL tables. The archive script efficiently exports partitions to the cost effective Iceberg/Parquet format on S3, while the restore script enables seamless data recovery when needed. The Spring Boot API bridges the gap by allowing direct queries against archived data, eliminating the need for restoration in many analytical scenarios.
Key benefits:
- Cost reduction: 90 to 98 percent storage cost savings compared to keeping data in Aurora
- Operational flexibility: Query archived data without restoration
- Schema preservation: Full schema metadata maintained for reliable restores
- Partition management: Clean attach/detach operations for partitioned tables
- Predicate pushdown: Efficient filtering reduces data transfer and processing
The Iceberg format ensures compatibility with the broader data ecosystem, allowing tools like Athena, Spark, and Trino to query the same archived data when needed for more complex analytical workloads.