Stability : The Water of Life for Engineering
Why do Companies Get Stability So Wrong?
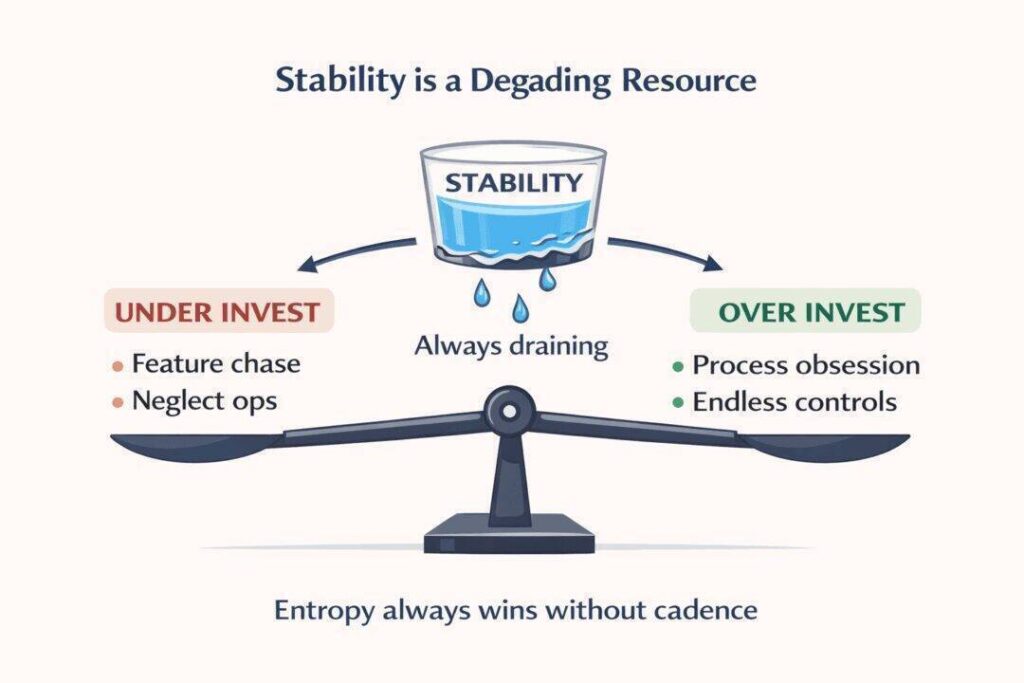
Most companies do not fail because they cannot innovate. They fail because they misjudge stability.
Some organisations under invest. They chase features, growth, and deadlines while stability quietly drains away. Outages feel sudden. Incidents feel unfair. Leadership asks how this happened “out of nowhere”.
Other organisations over invest. They build process on process, reviews on reviews, controls on controls. Delivery slows to a crawl. Engineers disengage. The system becomes stable but irrelevant. Eventually the business collapses under its own weight. Both groups are wrong for the same reason.
They treat stability as a thing you can reason about intellectually instead of a resource that behaves physically. Most corporate conversations about stability sound like this:
- “Are we stable enough?”
- “Do we need more resilience?”
- “Let’s prioritise reliability this quarter”
- “Teams can work on stability when they think it’s needed”
These are the wrong questions. Stability is not binary. It is not something you have or do not have. It is something that is constantly leaking away.
Entropy never pauses.
Complexity always grows.
Dependencies always drift.
So the real question is not how much stability do we want? It is how do humans reliably maintain something that is always degrading, even when it feels fine?
To answer that, it helps to stop thinking like executives and start thinking like biology. And that brings us to a very simple walking experiment.
1. A Simple Walking Experiment
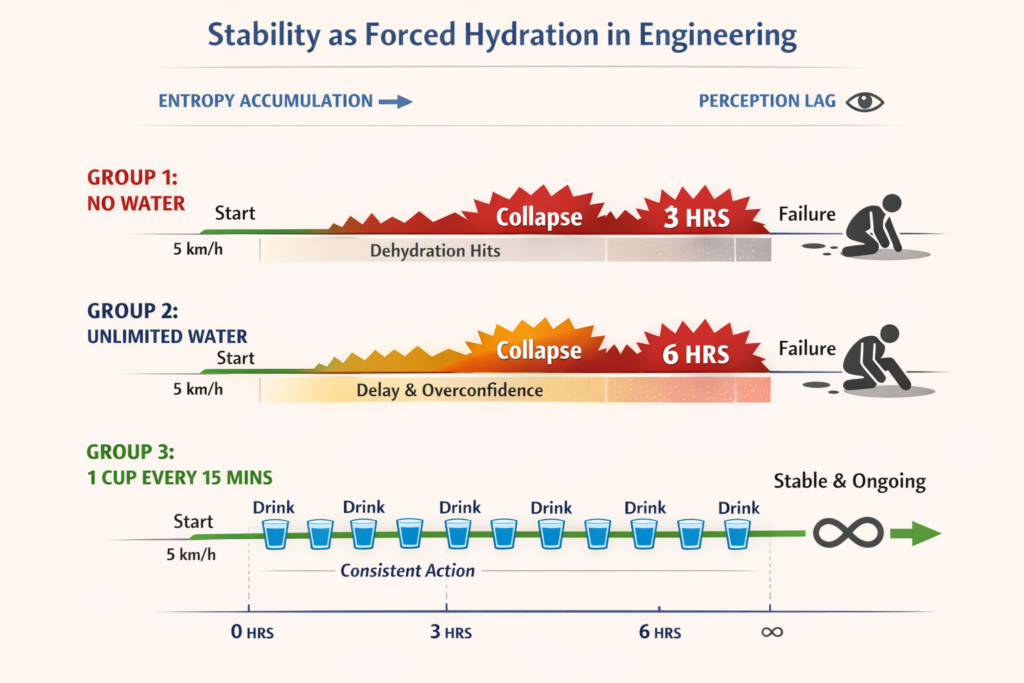
Imagine three groups of walkers.
All three walk at exactly 5 km per hour.
The terrain is the same.
The weather is the same.
The only difference is how they consume water.
This is not a story about hydration. It is a story about engineering stability.
Group 1: No Water
This group decides they will push through.
Water is optional. They feel strong. They feel fine.
No surprises. they fail after 3 hours.
Group 2: Unlimited Water
This group has all the water they could ever want. Drink whenever you feel like it. No limits. No rules.
This group goes longer, BUT still fails after 6 hours.
Group 3: One Cup Every 15 Minutes
This group is forced to drink one cup of water every 15 minutes. Even if they are not thirsty. Even if they feel fine. Even if they think it is unnecessary.
They walk forever.
2. Who Wins and Why?
The obvious loser is Group 1. Deprivation always kills you quickly.
But the surprising failure is Group 2. Unlimited water feels like safety. It feels mature. It feels trusting. Yet it still fails. Why?
Because humans are terrible at sensing slow degradation. By the time thirst is obvious, damage is already done. By the time things feel unstable, they are likely in already in a really bad place.
Group 3 wins not because they are smarter.
They win because they removed judgment from the system.
3. Stability Is Like Water
Stability in engineering behaves exactly like hydration. It is:
- Always leaking away
- Always trending down
- Never something you “finish”
You do not reach a stable system and stop.
You only slow the rate at which entropy wins.
The moment you stop drinking, dehydration begins. The moment you stop investing in stability, decay begins. There is no neutral state.
4. Why does “Do It When You Need It” Fail?
Many teams treat stability like Group 2 treats water.
“We can fix reliability whenever we want.”
“We have budget for it.”
“We will focus on it after this delivery.”
“We are stable enough right now.”
This is a lie we tell ourselves because:
- Instability accumulates silently
- Risk compounds invisibly
- Pain arrives late and all at once
Your appetite for stability is not accurate.
Your perception lags reality. By the time engineers feel the pain:
- Pager load is already high
- Cognitive load is already maxed
- Trust in the system is already gone
5. Why Forced, Small, Regular Work Wins
Group 3 survives because the rule is boring, repetitive, and non negotiable.
One cup.
Every 15 minutes.
No debate.
Engineering stability works the same way.
Small actions:
- Reviewing error budgets
- Paying down tiny bits of tech debt
- Exercising failovers
- Reading logs when nothing is broken
- Testing restores even when backups “worked last time”
These actions feel unnecessary right up until they are existential.
The key insight is this:
Stability must be regular, small, and forced, not discretionary.
6. Carte Blanche Stability Still Fails
Giving teams unlimited freedom to “do stability whenever they want” feels empowering. It is not. It creates:
- Deferral
- Rationalisation
- Optimism bias
- Hero culture
Just like unlimited water, people will drink:
- Too late
- Too little
- Only when discomfort appears
And discomfort always appears after damage.
7. Stability Is Not a Project
You do not “do stability”. You consume it continuously. Miss a few intervals and you do not notice. Miss enough and you collapse suddenly. This is why outages feel unfair. “This came out of nowhere.” – it never did. You authored it, when you made stability a choice.
8. The Temporary Uplift of New Leadership and Why It Fades
There is a familiar pattern in many organisations.
New leadership arrives.
Energy lifts.
Standards tighten.
Questions get sharper.
Long ignored issues suddenly move.
For a while, stability improves.
This uplift is real, but it is also temporary.
Why?
Because much of the early improvement does not come from structural change.
It comes from attention.
People prepare more.
Risks are surfaced that were previously hidden.
Teams clean things up because someone is finally looking.
But attention is not a system. It does not scale. And it does not last. Over time, leaders get pulled upward and outward:
- Strategy
- Budgets
- Politics
- External pressure
The deep, uncomfortable details fade from view again. Entropy resumes its work. Eventually the organisation concludes it needs:
- A new leader
- A new structure
- Another reset
And the cycle repeats.
8.1 Inspection Is Not Optional
John Maxwell captured this simply:
“What you do not inspect, you cannot expect.”
Stability is not maintained by policy. It is maintained by inspection. Leaders cannot delegate this entirely.
Dashboards help, but they are abstractions.
Audits help, but they are compliance driven.
Neither replaces technical curiosity.
8.2 Why Audits Miss the Real Risks
Auditors are necessary, but they are constrained:
- They work to checklists
- They assess evidence, not behaviour
- They validate controls, not fragility
They rarely ask:
- What happens under load?
- What breaks first?
- What do engineers silently work around?
- Where are we “hoping” things hold?
A technically competent leader, even without writing code daily, will notice:
- Architectural smells
- Operational anti patterns
- Client complains
- Excessive handoffs during fault resolution
- Risk concentration
- Overly large blast radii
- “Accepted” risks no one remembers accepting
These things do not show up in audit findings.
They show up in deep dives.
8.3 Leadership Must Periodically Go to the Gemba
If leaders want stability to persist beyond their honeymoon period, they must:
- Periodically deep dive the estate
- Sit with engineers in the details
- Review real incidents, not summaries
- Ask uncomfortable “what if” questions
Not continuously. But deliberately. And repeatedly. This does two things:
- It resets attention on the highest risks
- It reinforces that stability is not someone else’s job
8.4 Sustainable Stability Outlives Leaders
The goal is not to rely on heroic leaders. The goal is to build systems where:
- Risk surfaces automatically
- Attention is forced by mechanisms
- Leaders amplify the system instead of substituting for it
New leadership should improve things.
But stability should not depend on leadership churn. When stability only improves after a reset at the top, it is already leaking. The strongest organisations use leadership attention to reinforce cadence, not replace it.
9. The Engineering Lesson
Great engineering organisations do not trust feelings. They trust cadence. They bake stability into time:
- Weekly reliability work
- Fixed chaos testing intervals
- Mandatory post incident learning
- Forced operational hygiene
Even when everything looks fine. Especially when everything looks fine. Because that is when dehydration is already happening.
10. Conclusion: Turning Stability from Belief into Mechanism
Stability does not survive on intent.
It survives on structure.
Most organisations say the right things about reliability, resilience, and operational excellence. Very few hard code those beliefs into how work actually gets done.
If stability depends on motivation, maturity, or “good engineering culture”, it will decay.
Those things fluctuate. Entropy does not.
The only way stability survives at scale is when it is embedded as a forced, recurring behaviour.
10.1 Make Stability Time Non Negotiable
The first rule is simple: stability must have reserved time.
Set aside a fixed day each week, or a fixed percentage of capacity, that is explicitly not for delivery:
- Automation
- Observability improvements
- Reducing operational toil
- Fixing recurring incidents
- Removing fragile dependencies
This time should not be borrowable.
It should not be traded for deadlines.
If it disappears under pressure, it was never real to begin with.
Just like forced hydration, the value is not in intensity.
It is in cadence.
10.2 Always Run a Short Cycle Risk Rewrite Program
High risk systems should never wait for a “big modernisation”.
Instead, always run a rolling program that:
- Identifies the highest risk systems
- Rewrites or refactors them in small, contained slices
- Finishes something every cycle
This creates two critical properties:
- Risk is continuously reduced, not deferred
- Engineers stay close to production reality
Long lived, untouched systems are where entropy concentrates.
Short cycles keep decay visible.
10.3 Encode Stability as Hard Parameters
The most important shift is this:
stop debating risk and start flushing it out mechanically.
Introduce explicit constraints that surface outsized risk early, for example:
- Maximum database size: 10 TB
- Maximum service restart time: 10 minutes
- Maximum patch age: 3 months
- Maximum server size: 64 CPUs
- Maximum operating system age: 5 years
- Maximum sustained IOPS: 60k
- Maximum acceptable outage per incident: 30 minutes
These numbers do not need to be perfect.
They need to exist.
When a system crosses one of these thresholds, it triggers a conversation. Not a blame exercise. A prioritisation discussion.
The goal is not to prevent exceptions. The goal is to make embedded, accepted risk visible.
10.4 Adjust the Numbers, Never the Principle
Over time, these parameters will change:
- Hardware improves
- Tooling matures
- Teams get stronger
That is fine.
What must never change is the mechanism:
- Explicit limits
- Automatic signalling
- Early discussion
- Intentional action
This is how you prevent stability debt from silently compounding.
10.5 Stability Wins When It Is Boring
The organisations that endure do not heroically fix stability problems in crises.
They routinely prevent them in boring ways.
Small actions.
Forced cadence.
Hard limits.
That is how Group 3 walks forever.
Stability is not something you believe in. It is something you operationalise. And if you do not embed it mechanically, entropy will do the embedding for you.