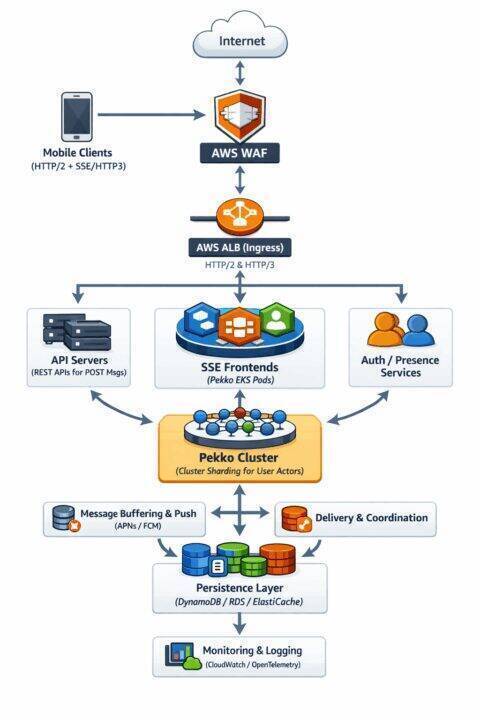
Scaling Mobile Chat to Millions: Architecture Decisions for Apache Pekko, SSE, and Java 25
Real time mobile chat represents one of the most demanding challenges in distributed systems architecture. Unlike web applications where connections are relatively stable, mobile clients constantly transition between networks, experience variable latency, and must conserve battery while maintaining instant message delivery. This post examines the architectural decisions behind building mobile chat at massive scale, the problems each technology solves, and the tradeoffs involved in choosing between alternatives.
1. Understanding the Mobile Chat Problem
Before evaluating solutions, architects must understand precisely what makes mobile chat fundamentally different from other distributed systems challenges.
1.1 The Connection State Paradox
Traditional stateless architectures achieve scale through horizontal scaling of identical, interchangeable nodes. Load balancers distribute requests randomly because any node can handle any request. State lives in databases, and the application tier remains stateless.
Chat demolishes this model. When User A sends a message to User B, the system must know which server holds User B’s connection. This isn’t a database lookup; it’s a routing decision that must happen for every message, in milliseconds, with perfect consistency across your entire cluster.
At 100,000 concurrent connections, you might manage with a centralised routing table in Redis. Query Redis for User B’s server, forward the message, done. At 10 million connections, that centralised lookup becomes the bottleneck. Every message requires a Redis round trip. Redis clustering helps but doesn’t eliminate the fundamental serialisation point.
The deeper problem is consistency. User B might disconnect and reconnect to a different server. Your routing table is now stale. With mobile users reconnecting constantly due to network transitions, your routing information is perpetually outdated. Eventually consistent routing means occasionally lost messages, which users notice immediately.
1.2 The Idle Connection Problem
Mobile usage patterns create a unique resource challenge. Users open chat apps, exchange a few messages, then switch to other apps. The connection often remains open in the background for push notifications and presence updates. At scale, you might have 10 million “connected” users where only 500,000 are actively messaging at any moment.
Your architecture must provision resources for 10 million connections but only needs throughput capacity for 500,000 active users. Traditional thread per connection models collapse here. Ten million OS threads is impossible; the context switching alone would consume all CPU. But you need instant response when any of those 10 million connections becomes active.
This asymmetry between connection count and activity level is fundamental to mobile chat and drives many architectural decisions.
1.3 Network Instability as the Norm
Mobile networks are hostile environments. Users walk through buildings, ride elevators, transition from WiFi to cellular, pass through coverage gaps. A user walking from their office to a coffee shop might experience dozens of network transitions in fifteen minutes.
Each transition is a potential message loss event. The TCP connection over WiFi terminates when the device switches to cellular. Messages queued for delivery on the old connection are lost unless your architecture explicitly handles reconnection and replay.
Desktop web chat can treat disconnection as exceptional. Mobile chat must treat disconnection as continuous background noise. Reconnection isn’t error recovery; it’s normal operation.
1.4 Battery, Backgrounding, and the Wakeup Problem
Every network operation consumes battery. Maintaining a persistent connection keeps the radio active, draining battery faster than almost any other operation. The mobile radio state machine makes this worse: transitioning from idle to active takes hundreds of milliseconds and significant power. Frequent small transmissions prevent deep sleep, causing battery drain disproportionate to data transferred.
But the real architectural complexity emerges when users background your app.
1.4.1 What Happens When Apps Are Backgrounded
iOS and Android aggressively manage background applications to preserve battery and system resources. When a user switches away from your chat app:
iOS Behaviour: Apps receive approximately 10 seconds of background execution time before suspension. After suspension, no code executes, no network connections are maintained, no timers fire. The app is frozen in memory. iOS will terminate suspended apps entirely under memory pressure without notification.
Android Behaviour: Android is slightly more permissive but increasingly restrictive with each version. Background execution limits (introduced in Android 8) prevent apps from running background services freely. Doze mode (Android 6+) defers network access and background work when the device is stationary and screen off. App Standby Buckets (Android 9+) restrict background activity based on how recently the user engaged with the app.
In both cases, your carefully maintained SSE connection dies when the app backgrounds. The server sees a disconnect. Messages arrive but have nowhere to go.
1.4.2 Architectural Choices for Background Message Delivery
You have three fundamental approaches when clients are backgrounded:
Option 1: Push Notification Relay
When the server detects the SSE connection has closed, buffer incoming messages and send push notifications (APNs for iOS, FCM for Android) to wake the device and alert the user.
Advantages: Works within platform constraints. Users receive notifications even with app completely terminated. No special permissions or background modes required.
Disadvantages: Push notifications are not guaranteed delivery. APNs and FCM are best effort services that may delay or drop notifications under load. You cannot stream message content through push; you notify and wait for the user to open the app. The user experience degrades from real time chat to notification driven interaction.
Architectural implications: Your server must detect connection loss quickly (aggressive keepalive timeouts), maintain per user message buffers, integrate with APNs and FCM, and handle the complexity of notification payload limits (4KB for APNs, varying for FCM).
Option 2: Background Fetch and Silent Push
Use platform background fetch capabilities to periodically wake your app and check for new messages. Silent push notifications can trigger background fetches on demand.
iOS provides Background App Refresh, which wakes your app periodically (system determined intervals, typically 15 minutes to hours depending on user engagement patterns). Silent push notifications can wake the app for approximately 30 seconds of background execution.
Android provides WorkManager for deferrable background work and high priority FCM messages that can wake the app briefly.
Advantages: Better message freshness than pure notification relay. Can sync recent messages before user opens app, improving perceived responsiveness.
Disadvantages: Timing is not guaranteed; the system determines when background fetch runs. Silent push has strict limits (iOS limits rate and will throttle abusive apps). Background execution time is severely limited; you cannot maintain a persistent connection. Users who disable Background App Refresh get degraded experience.
Architectural implications: Your sync protocol must be efficient, fetching only delta updates within the brief execution window. Server must support efficient “messages since timestamp X” queries. Consider message batching to maximise value of each background wake.
Option 3: Persistent Connection via Platform APIs
Both platforms offer APIs for maintaining network connections in background, but with significant constraints.
iOS VoIP Push: Originally designed for VoIP apps, this mechanism maintains a persistent connection and wakes the app instantly for incoming calls. However, Apple now requires apps using VoIP push to actually provide VoIP calling functionality. Apps abusing VoIP push for chat have been rejected from the App Store.
iOS Background Modes: The “remote-notification” background mode combined with PushKit allows some connection maintenance, but Apple reviews usage carefully. Pure chat apps without calling features will likely be rejected.
Android Foreground Services: Apps can run foreground services that maintain connections, but must display a persistent notification to the user. This is appropriate for actively ongoing activities (music playback, navigation) but feels intrusive for chat apps. Users may disable or uninstall apps with unwanted persistent notifications.
Advantages: True real time message delivery even when backgrounded. Best possible user experience.
Disadvantages: Platform restrictions make this unavailable for most pure chat apps. Foreground service notifications annoy users. Increased battery consumption may lead users to uninstall.
Architectural implications: Only viable if your app genuinely provides VoIP or other qualifying functionality. Otherwise, design assuming connections terminate on background.
1.4.3 The Pragmatic Hybrid Architecture
Most successful chat apps use a hybrid approach:
Foreground: Maintain SSE connection for real time message streaming. Aggressive delivery with minimal latency.
Recently Backgrounded (first few minutes): The connection may persist briefly. Deliver messages normally until disconnect detected.
Backgrounded: Switch to push notification model. Buffer messages server side. Send push notification for new messages. Optionally use silent push to trigger background sync of recent messages.
App Terminated: Pure push notification relay. User sees notification, opens app, app reconnects and syncs all missed messages.
Return to Foreground: Immediately re-establish SSE connection. Sync any messages missed during background period using Last-Event-ID resume. Return to real time streaming.
This hybrid approach accepts platform constraints rather than fighting them. Real time delivery when possible, reliable notification when not.
1.4.4 Server Side Implications
The hybrid model requires server architecture to support:
Connection State Tracking: Detect when SSE connections close. Distinguish between network hiccup (will reconnect shortly) and true backgrounding (switch to push mode).
Per User Message Buffers: Store messages for offline users. Size buffers appropriately; users backgrounded for days may have thousands of messages.
Push Integration: Maintain connections to APNs and FCM. Handle token refresh, feedback service (invalid tokens), and retry logic.
Efficient Sync Protocol: Support “give me everything since message ID X” queries efficiently. Index appropriately for this access pattern.
Delivery Tracking: Track which messages were delivered via SSE versus require push notification versus awaiting sync on app open. Avoid duplicate notifications.
1.5 Message Ordering and Delivery Guarantees
Users expect messages to arrive in send order. When Alice sends “Are you free?” followed by “for dinner tonight?”, they must arrive in that order or the conversation becomes nonsensical. Network variability means packets arrive out of order constantly. Your application layer must reorder correctly.
Additionally, mobile chat requires “at least once” delivery with deduplication. Users expect messages to arrive even if they were offline when sent. But retransmission on reconnection must not create duplicates. This requires message identifiers, delivery tracking, and idempotent processing throughout your pipeline.
2. Why Apache Pekko Solves These Problems
Apache Pekko provides the distributed systems primitives that address mobile chat’s fundamental challenges. Understanding why requires examining what Pekko actually provides and how it maps to chat requirements.
2.1 The Licensing Context: Why Pekko Over Akka
Akka pioneered the actor model on the JVM and proved it at scale across thousands of production deployments. In 2022, Lightbend changed Akka’s licence from Apache 2.0 to the Business Source Licence, requiring commercial licences for production use above certain thresholds.
Apache Pekko emerged as a community fork maintaining API compatibility with Akka 2.6.x under Apache 2.0 licensing. For architects evaluating new projects, Pekko provides the same battle tested primitives without licensing concerns or vendor dependency.
The codebase is mature, inheriting over a decade of Akka’s production hardening. The community is active and includes many former Akka contributors. For new distributed systems projects on the JVM, Pekko is the clear choice.
2.2 The Actor Model: Right Abstraction for Connection State
The actor model treats computation as isolated entities exchanging messages. Each actor has private state, processes messages sequentially, and communicates only through asynchronous message passing. No shared memory, no locks, no synchronisation primitives.
This maps perfectly onto chat connections:
One Actor Per Connection: Each mobile connection becomes an actor. The actor holds connection state: user identity, device information, subscription preferences, message buffers. When messages arrive for that user, they route to the actor. When the connection terminates, the actor stops and releases resources.
Extreme Lightweightness: Actors are not threads. A single JVM hosts millions of actors, each consuming only a few hundred bytes when idle. This matches mobile’s reality: millions of mostly idle connections, each requiring instant activation when a message arrives.
Natural Fault Isolation: A misbehaving connection cannot crash the server. Actors fail independently. Supervisor hierarchies determine recovery strategy. One client sending malformed data affects only its actor, not the millions of other connections on that node.
Sequential Processing Eliminates Concurrency Bugs: Each actor processes one message at a time. Connection state updates are inherently serialised. You don’t need locks, atomic operations, or careful reasoning about race conditions. The actor model eliminates entire categories of bugs that plague traditional concurrent connection handling.
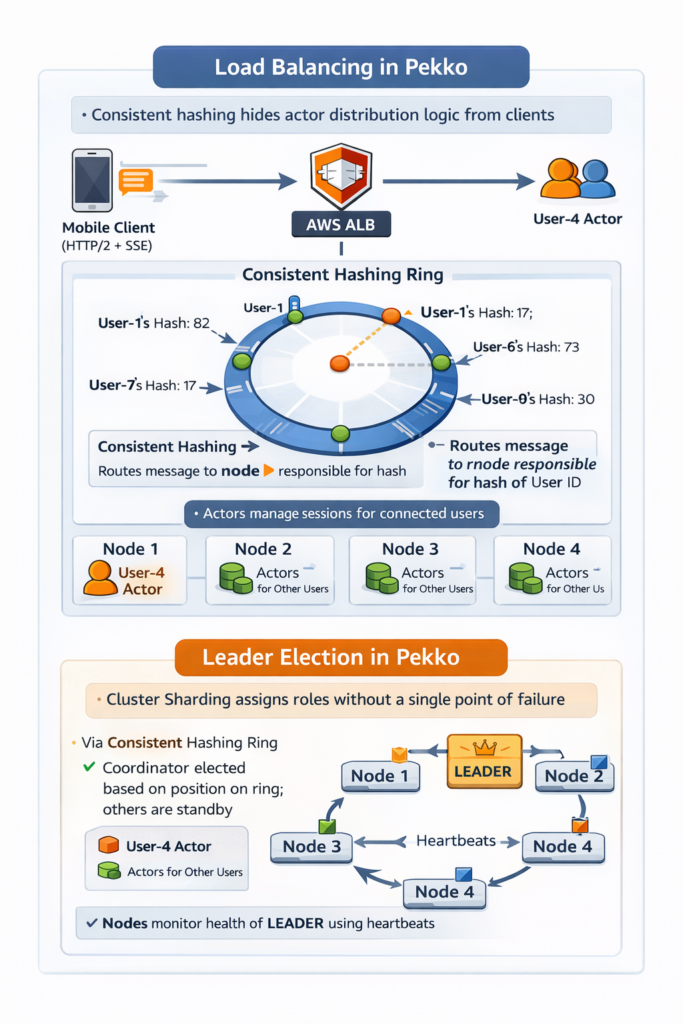
2.3 Cluster Sharding: Eliminating the Routing Bottleneck
Cluster sharding is Pekko’s solution to the connection routing problem. Rather than maintaining an explicit routing table, you define a sharding strategy based on entity identity. Pekko handles physical routing transparently.
When sending a message to User B, you address it to User B’s logical entity identifier. You don’t know or care which physical node hosts User B. Pekko’s sharding layer determines the correct node and routes the message. If User B isn’t currently active, the shard can activate an actor for them on demand.
The architectural significance is profound:
No Centralised Routing Table: There’s no Redis cluster to query for every message. Routing is computed from the entity identifier using consistent hashing. The computation is local; no network round trip required.
Automatic Rebalancing: When nodes join or leave the cluster, shards rebalance automatically. Application code is unchanged. A user might reconnect to a different physical node after a network transition, but message delivery continues because routing is by logical identity, not physical location.
Elastic Scaling: Add nodes to increase capacity. Remove nodes during low traffic. The sharding layer handles redistribution without application involvement. This is true elasticity, not the sticky session pseudo scaling that WebSocket architectures often require.
Location Transparency: Services sending messages don’t know cluster topology. They address logical entities. This decouples message producers from the physical deployment, enabling independent scaling of different cluster regions.
2.4 Backpressure: Graceful Degradation Under Load
Mobile networks have variable bandwidth. A user on fast WiFi can receive messages instantly. The same user in an elevator has effectively zero bandwidth. What happens to messages queued for delivery?
Without explicit backpressure, messages accumulate in memory. The buffer grows until the server exhausts heap and crashes. This cascading failure takes down not just one connection but thousands sharing that server.
Pekko Streams provides reactive backpressure propagating through entire pipelines. When a consumer can’t keep up, pressure signals flow backward to producers. You configure explicit overflow strategies:
Bounded Buffers: Limit how many messages queue per connection. Memory consumption is predictable regardless of consumer speed.
Overflow Strategies: When buffers fill, choose behaviour: drop oldest messages, drop newest messages, signal failure to producers. For chat, dropping oldest is usually correct; users prefer missing old messages to system crashes.
Graceful Degradation: Under extreme load, the system slows down rather than falling over. Message delivery delays but the system remains operational.
This explicit backpressure is essential for mobile where network quality varies wildly and client consumption rates are unpredictable.
2.5 Multi Device and Presence
Modern users have multiple devices: phone, tablet, watch, desktop. Messages should deliver to all connected devices. Presence should reflect aggregate state across devices.
The actor hierarchy models this naturally. A UserActor represents the user across all devices. Child ConnectionActors represent individual device connections. Messages to the user fan out to all active connections. When all devices disconnect, the UserActor knows the user is offline and can trigger push notifications or buffer messages.
This isn’t just convenience; it’s architectural clarity. The UserActor is the single source of truth for that user’s state. There’s no distributed coordination problem across devices because one actor owns the aggregate state.
3. Server Sent Events: The Right Protocol Choice
WebSockets are the default assumption for real time applications. Server Sent Events deserve serious architectural consideration for mobile chat.
3.1 Understanding Traffic Asymmetry
Examine any chat system’s traffic patterns. Users receive far more messages than they send. In a group chat with 50 participants, each sent message generates 49 deliveries. Downstream traffic (server to client) exceeds upstream by roughly two orders of magnitude.
WebSocket provides symmetric bidirectional streaming. You’re provisioning and managing upstream capacity you don’t need. SSE acknowledges the asymmetry: persistent streaming downstream, standard HTTP requests upstream.
This isn’t a limitation; it’s architectural honesty about traffic patterns.
3.2 Upstream Path Simplicity
With SSE, sending a message is an HTTP POST. This request is stateless. Any server in your cluster can handle it. Load balancing is trivial. Retries on network failure use standard HTTP retry logic. Rate limiting uses standard HTTP rate limiting. Authentication uses standard HTTP authentication.
You’ve eliminated an entire category of complexity. The upstream path doesn’t need sticky sessions, doesn’t need cluster coordination, doesn’t need special handling for connection migration. It’s just HTTP requests, which your infrastructure already knows how to handle.
3.3 Automatic Reconnection with Resume
The EventSource specification includes automatic reconnection with resume capability. When a connection drops, the client reconnects and sends the Last-Event-ID header indicating the last successfully received event. The server resumes from that point.
For mobile where disconnections happen constantly, this built in resume eliminates significant application complexity. You’re not implementing reconnection logic, not tracking client state for resume, not building replay mechanisms. The protocol handles it.
This is exactly once delivery semantics without distributed transaction protocols. The client tells you what it received; you replay from there.
3.4 HTTP Infrastructure Compatibility
SSE is pure HTTP. It works through every proxy, load balancer, CDN, and firewall that understands HTTP. Corporate networks, hotel WiFi, airplane WiFi: if HTTP works, SSE works.
WebSocket, despite widespread support, still encounters edge cases. Some corporate proxies don’t handle the upgrade handshake. Some firewalls block the WebSocket protocol. Some CDNs don’t support WebSocket passthrough. These edge cases occur precisely when users are on restrictive networks where reliability matters most.
From an operations perspective, SSE uses your existing HTTP monitoring, logging, and debugging infrastructure. WebSocket requires parallel tooling.
3.5 Debugging and Observability
SSE streams are plain text over HTTP. You can observe them with curl, log them with standard HTTP logging, replay them for debugging. Every HTTP tool in your operational arsenal works.
WebSocket debugging requires specialised tools understanding the frame protocol. At 3am during an incident, the simplicity of SSE becomes invaluable.
4. HTTP Protocol Version: A Critical Infrastructure Decision
The choice between HTTP/1.1, HTTP/2, and HTTP/3 significantly impacts mobile chat performance. Each version represents different tradeoffs.
4.1 HTTP/1.1: Universal Compatibility
HTTP/1.1 works everywhere. Every client, proxy, load balancer, and debugging tool supports it. For SSE specifically, HTTP/1.1 functions correctly because SSE connections are single stream.
The limitation is connection overhead. Browsers and mobile clients restrict HTTP/1.1 connections to six per domain. A chat app with multiple subscriptions (messages, presence, typing indicators, notifications) exhausts this quickly. Each subscription requires a separate TCP connection with separate TLS handshake overhead.
For mobile, the multiple connection problem compounds with battery impact. Each TCP connection requires radio activity for establishment and maintenance. Six connections consume significantly more power than one.
Choose HTTP/1.1 when: Maximum compatibility is essential, your infrastructure doesn’t support HTTP/2, or you have very few simultaneous streams.
4.2 HTTP/2: The Practical Choice for Most Deployments
HTTP/2 multiplexes unlimited streams over a single TCP connection. Each SSE subscription becomes a stream within the same connection. Browser connection limits become irrelevant.
For mobile architecture, the implications are substantial:
Single Connection Efficiency: One TCP connection, one TLS session, one set of kernel buffers. The radio wakes once rather than maintaining multiple connections. Battery consumption drops significantly.
Instant Stream Establishment: New subscriptions don’t require TCP handshakes. Opening a new chat room adds a stream to the existing connection in milliseconds rather than the hundreds of milliseconds for new TCP connection establishment.
Header Compression: HPACK compression eliminates redundant bytes in repetitive headers. SSE requests with identical Authorization, Accept, and User-Agent headers compress to single digit bytes after the first request.
Stream Isolation: Flow control operates per stream. A slow stream doesn’t block other streams. If a busy group chat falls behind, direct message delivery continues unaffected.
The limitation is TCP head of line blocking. HTTP/2 streams are independent at the application layer but share a single TCP connection underneath. A single lost packet blocks all streams until retransmission. On lossy mobile networks, this creates correlated latency spikes across all subscriptions.
Choose HTTP/2 when: You need multiplexing benefits, your infrastructure supports HTTP/2 termination, and TCP head of line blocking is acceptable.
4.3 HTTP/3 and QUIC: Purpose Built for Mobile
HTTP/3 replaces TCP with QUIC, a UDP based transport with integrated encryption. For mobile chat, QUIC provides capabilities that fundamentally change user experience.
Stream Independence: QUIC delivers streams independently at the transport layer, not just the application layer. Packet loss on one stream doesn’t affect others. On mobile networks where packet loss is routine, this isolation prevents correlated latency spikes across chat subscriptions.
Connection Migration: QUIC connections are identified by connection ID, not IP address and port. When a device switches from WiFi to cellular, the QUIC connection survives the IP address change. No reconnection, no TLS renegotiation, no message replay. The connection continues seamlessly.
This is transformative for mobile. A user walking from WiFi coverage to cellular maintains their chat connection without interruption. With TCP, this transition requires full reconnection with associated latency and potential message loss during the gap.
Zero Round Trip Resumption: For returning connections, QUIC supports 0-RTT establishment. A user who chatted yesterday can send and receive messages before completing the handshake. For apps where users connect and disconnect frequently, this eliminates perceptible connection latency.
Current Deployment Challenges: Some corporate firewalls block UDP. QUIC runs in userspace rather than leveraging kernel TCP optimisations, increasing CPU overhead. Operational tooling is less mature. Load balancer support varies across vendors.
Choose HTTP/3 when: Mobile experience is paramount, your infrastructure supports QUIC termination, and you can fall back gracefully when UDP is blocked.
4.4 The Hybrid Architecture Recommendation
Deploy HTTP/2 as your baseline with HTTP/3 alongside. Clients negotiate using Alt-Svc headers, selecting HTTP/3 when available and falling back to HTTP/2 when UDP is blocked.
Modern iOS (15+) and Android clients support HTTP/3 natively. Most mobile users will negotiate HTTP/3 automatically, getting connection migration benefits. Users on restrictive networks fall back to HTTP/2 without application awareness.
This hybrid approach provides optimal experience for capable clients while maintaining universal accessibility.
5. Java 25: Runtime Capabilities That Change Architecture
Java 25 delivers runtime capabilities that fundamentally change how you architect JVM based chat systems. These aren’t incremental improvements but architectural enablers.
5.1 Virtual Threads: Eliminating the Thread/Connection Tension
Traditional Java threads map one to one with operating system threads. Each thread allocates megabytes of stack space and involves kernel scheduling. At 10,000 threads, context switching overhead dominates CPU usage. At 100,000 threads, the system becomes unresponsive.
This created a fundamental architectural tension. Simple, readable code wants one thread per connection, processing messages sequentially with straightforward blocking I/O. But you can’t afford millions of OS threads for millions of connections. The solution was reactive programming: callback chains, continuation passing, complex async/await patterns that are difficult to write, debug, and maintain.
Virtual threads resolve this tension. They’re lightweight threads managed by the JVM, not the operating system. Millions of virtual threads multiplex onto a small pool of platform threads (typically matching CPU core count). When a virtual thread blocks on I/O, it yields its carrier platform thread to other virtual threads rather than blocking the OS thread.
Architecturally, you can now write straightforward sequential code for connection handling. Read from network. Process message. Write to database. Query cache. Each operation can block without concern. When I/O blocks, other connections proceed on the same platform threads.
Combined with Pekko’s actor model, virtual threads enable blocking operations inside actors without special handling. Actors calling databases or external services can use simple blocking calls rather than complex async patterns.
5.2 Generational ZGC: Eliminating GC as an Architectural Constraint
Garbage collection historically constrained chat architecture. Under sustained load, heap fills with connection state, message buffers, and temporary objects. Eventually, major collection triggers, pausing all application threads for hundreds of milliseconds.
During that pause, no messages deliver. Connections timeout. Clients reconnect. The reconnection surge creates more garbage, triggering more collection, potentially cascading into cluster wide instability.
Architects responded with complex mitigations: off heap storage, object pooling, careful allocation patterns, GC tuning rituals. Or they abandoned the JVM entirely for languages with different memory models.
Generational ZGC in Java 25 provides sub millisecond pause times regardless of heap size. At 100GB heap with millions of objects, GC pauses remain under 1ms. Collection happens concurrently while application threads continue executing.
Architecturally, this removes GC as a constraint. You can use straightforward object allocation patterns. You can provision large heaps for connection state. You don’t need off heap complexity for latency sensitive paths. GC induced latency spikes don’t trigger reconnection cascades.
5.3 AOT Compilation Cache: Solving the Warmup Problem
Java’s Just In Time compiler produces extraordinarily efficient code after warmup. The JVM interprets bytecode initially, identifies hot paths through profiling, compiles them to native code, then recompiles with more aggressive optimisation as profile data accumulates.
Full optimisation takes 3 to 5 minutes of sustained load. During warmup:
Elevated Latency: Interpreted code runs 10x to 100x slower than compiled code. Message delivery takes milliseconds instead of microseconds.
Increased CPU Usage: The JIT compiler consumes significant CPU while compiling. Less capacity remains for actual work.
Impaired Autoscaling: When load spikes trigger scaling, new instances need warmup before reaching efficiency. The spike might resolve before new capacity becomes useful.
Deployment Pain: Rolling deployments put cold instances into rotation. Users hitting new instances experience degraded performance until warmup completes.
AOT (Ahead of Time) compilation caching through Project Leyden addresses this. You perform a training run under representative load. The JVM records compilation decisions: which methods are hot, inlining choices, optimisation levels. This persists to a cache file.
On production startup, the JVM loads cached compilation decisions and applies them immediately. Methods identified as hot during training compile before handling any requests. The server starts at near optimal performance.
Architecturally, this transforms deployment and scaling characteristics. New instances become immediately productive. Autoscaling responds effectively to sudden load. Rolling deployments don’t cause latency regressions. You can be more aggressive with instance replacement for security patching or configuration changes.
5.4 Structured Concurrency: Lifecycle Clarity
Structured concurrency ensures concurrent operations have clear parent/child relationships. When a parent scope completes, child operations are guaranteed complete or cancelled. No orphaned tasks, no resource leaks from forgotten futures.
For chat connection lifecycle, this provides architectural clarity. When a connection closes, all associated operations terminate: pending message deliveries, presence updates, typing broadcasts. With unstructured concurrency, ensuring complete cleanup requires careful tracking. With structured concurrency, cleanup is automatic and guaranteed.
Combined with virtual threads, you might spawn thousands of lightweight threads for subtasks within a connection’s processing. Structured concurrency ensures they all terminate appropriately when the connection ends.
6. Kubernetes and EKS Deployment Architecture
Deploying Pekko clusters on Kubernetes requires understanding how actor clustering interacts with container orchestration.
6.1 EKS Configuration Considerations
Amazon EKS provides managed Kubernetes suitable for Pekko chat deployments. Several configuration choices significantly impact cluster behaviour.
Node Instance Types: Chat servers are memory bound before CPU bound due to connection state overhead. Memory optimised instances (r6i, r6g series) provide better cost efficiency than general purpose instances. For maximum connection density, r6g.4xlarge (128GB memory, 16 vCPU) or r6i.4xlarge handles approximately 500,000 connections per node.
Graviton Instances: ARM based Graviton instances (r6g, r7g series) provide approximately 20% better price performance than equivalent x86 instances. Java 25 has mature ARM support. Unless you have x86 specific dependencies, Graviton instances reduce infrastructure cost at scale.
Node Groups: Separate node groups for Pekko cluster nodes versus supporting services (databases, monitoring, ingestion). This allows independent scaling and prevents noisy neighbour issues where supporting workloads affect chat latency.
Pod Anti-Affinity: Configure pod anti-affinity to spread Pekko cluster members across availability zones and physical hosts. Losing a single host shouldn’t remove multiple cluster members simultaneously.
6.2 Pekko Kubernetes Discovery
Pekko clusters require members to discover each other for gossip protocol coordination. On Kubernetes, the Pekko Kubernetes Discovery module uses the Kubernetes API to find peer pods.
Configuration involves:
Headless Service: A Kubernetes headless service (clusterIP: None) allows pods to discover peer pod IPs directly rather than load balancing.
RBAC Permissions: The Pekko discovery module needs permissions to query the Kubernetes API for pod information. A ServiceAccount with appropriate RBAC rules enables this.
Startup Coordination: During rolling deployments, new pods must join the existing cluster before old pods terminate. Proper readiness probes and deployment strategies ensure cluster continuity.
6.3 Network Configuration for Connection Density
High connection counts require careful network configuration:
VPC CNI Settings: The default AWS VPC CNI limits pods per node based on ENI capacity. For high connection density, configure secondary IP mode or consider Calico CNI for higher pod density.
Connection Tracking: Linux connection tracking tables have default limits around 65,536 entries. At hundreds of thousands of connections per node, increase nf_conntrack_max accordingly.
Port Exhaustion: With HTTP/2 multiplexing, port exhaustion is less common but still possible for outbound connections to databases and services. Ensure adequate ephemeral port ranges.
6.4 Horizontal Pod Autoscaling Considerations
Traditional HPA based on CPU or memory doesn’t map well to chat workloads where connection count is the primary scaling dimension.
Custom Metrics: Expose connection count as a Prometheus metric and configure HPA using custom metrics adapter. Scale based on connections per pod rather than resource utilisation.
Predictive Scaling: Chat traffic often has predictable daily patterns. AWS Predictive Scaling can pre provision capacity before expected peaks rather than reacting after load arrives.
Scaling Responsiveness: With AOT compilation cache, new pods are immediately productive. This enables more aggressive scaling policies since new capacity provides value immediately rather than after warmup.
6.5 Service Mesh Considerations
Service mesh technologies (Istio, Linkerd) add sidecar proxies that intercept traffic. For high connection count workloads, evaluate carefully:
Sidecar Overhead: Each connection passes through the sidecar proxy, adding latency and memory overhead. At 500,000 connections per pod, sidecar memory consumption becomes significant.
mTLS Termination: If using service mesh for internal mTLS, the sidecar terminates and re-establishes TLS, adding CPU overhead per connection.
Recommendation: For Pekko cluster internal traffic, consider excluding from mesh using annotations. Apply mesh policies to edge traffic where the connection count is lower.
7. Linux Distribution Selection
The choice of Linux distribution affects performance, security posture, and operational characteristics for high connection count workloads.
7.1 Amazon Linux 2023
Amazon Linux 2023 (AL2023) is purpose built for AWS workloads. It uses a Fedora based lineage with Amazon specific optimisations.
Advantages: Optimised for AWS infrastructure including Nitro hypervisor integration. Regular security updates through Amazon. No licensing costs. Excellent AWS tooling integration. Kernel tuned for network performance.
Considerations: Shorter support lifecycle than enterprise distributions. Community smaller than Ubuntu or RHEL ecosystems.
Best for: EKS deployments prioritising AWS integration and cost optimisation.
7.2 Bottlerocket
Bottlerocket is Amazon’s container optimised Linux distribution. It runs containers and nothing else.
Advantages: Minimal attack surface with only container runtime components. Immutable root filesystem prevents runtime modification. Atomic updates reduce configuration drift. API driven configuration rather than SSH access.
Considerations: Cannot run non-containerised workloads. Debugging requires different operational patterns (exec into containers rather than SSH to host). Less community familiarity.
Best for: High security environments where minimal attack surface is paramount. Organisations with mature container debugging practices.
7.3 Ubuntu Server
Ubuntu Server (22.04 LTS or 24.04 LTS) provides broad compatibility and extensive community support.
Advantages: Large community and extensive documentation. Wide hardware and software compatibility. Canonical provides commercial support options. Most operational teams are familiar with Ubuntu.
Considerations: Larger base image than container optimised distributions. More components installed than strictly necessary for container hosts.
Best for: Teams prioritising operational familiarity and broad ecosystem compatibility.
7.4 Flatcar Container Linux
Flatcar is a community maintained fork of CoreOS Container Linux, designed specifically for container workloads.
Advantages: Minimal OS footprint focused on container hosting. Automatic atomic updates. Immutable infrastructure patterns built in. Active community continuing CoreOS legacy.
Considerations: Smaller community than major distributions. Fewer enterprise support options.
Best for: Organisations comfortable with immutable infrastructure patterns seeking minimal container optimised OS.
7.5 Recommendation
For most EKS chat deployments, Amazon Linux 2023 provides the best balance of AWS integration, performance, and operational familiarity. The kernel network stack tuning is appropriate for high connection counts, AWS tooling integration is seamless, and operational teams can apply existing Linux knowledge.
For high security environments or organisations committed to immutable infrastructure, Bottlerocket provides stronger security posture at the cost of operational model changes.
8. Comparing Alternative Architectures
8.1 WebSockets with Socket.IO
Socket.IO provides WebSocket with automatic fallback and higher level abstractions like rooms and acknowledgements.
Architectural Advantages: Rich feature set reduces development time. Room abstraction maps naturally to group chats. Acknowledgement system provides delivery confirmation. Large community provides extensive documentation and examples.
Architectural Disadvantages: Sticky sessions required for scaling. The load balancer must route all requests from a client to the same server, fighting against elastic scaling. Scaling beyond a single server requires a pub/sub adapter (typically Redis), introducing a centralised bottleneck. The proprietary protocol layer over WebSocket adds complexity and overhead.
Scale Ceiling: Practical limits around hundreds of thousands of connections before the Redis adapter becomes a bottleneck.
Best For: Moderate scale applications where development speed outweighs architectural flexibility.
8.2 Firebase Realtime Database / Firestore
Firebase provides real time synchronisation as a fully managed service with excellent mobile SDKs.
Architectural Advantages: Zero infrastructure to operate. Offline support built into mobile SDKs. Real time listeners are trivial to implement. Automatic scaling handled by Google. Cross platform consistency through Google’s SDKs.
Architectural Disadvantages: Complete vendor lock in to Google Cloud Platform. Pricing scales with reads, writes, and bandwidth, becoming expensive at scale. Limited query capabilities compared to purpose built databases. Security rules become complex as data models grow. No control over performance characteristics or geographic distribution.
Scale Ceiling: Technically unlimited, but cost prohibitive beyond moderate scale.
Best For: Startups and applications where chat is a feature, not the product. When operational simplicity justifies premium pricing.
8.3 gRPC Streaming
gRPC provides efficient bidirectional streaming with Protocol Buffer serialisation.
Architectural Advantages: Highly efficient binary serialisation reduces bandwidth. Strong typing through Protocol Buffers catches errors at compile time. Excellent for polyglot service meshes. Deadline propagation and cancellation built into the protocol.
Architectural Disadvantages: Limited browser support requiring gRPC-Web proxy translation. Protocol Buffers add schema management overhead. Mobile client support requires additional dependencies. Debugging is more complex than HTTP based protocols.
Scale Ceiling: Very high; gRPC is designed for Google scale internal communication.
Best For: Backend service to service communication. Mobile clients through a translation gateway.
8.4 Solace PubSub+
Solace provides enterprise messaging infrastructure with support for multiple protocols including MQTT, AMQP, REST, and WebSocket. It’s positioned as enterprise grade messaging for mission critical applications.
Architectural Advantages:
Multi-protocol support allows different clients to use optimal protocols. Mobile clients might use MQTT for battery efficiency while backend services use AMQP for reliability guarantees. Protocol translation happens at the broker level without application involvement.
Hardware appliance options provide deterministic latency for organisations requiring guaranteed performance characteristics. Software brokers run on commodity infrastructure for cloud deployments.
Built in message replay and persistence provides durable messaging without separate storage infrastructure. Messages survive broker restarts and can be replayed for late joining subscribers.
Enterprise features like fine grained access control, message filtering, and topic hierarchies are mature and well documented. Compliance and audit capabilities suit regulated industries.
Hybrid deployment models support on premises, cloud, and edge deployments with consistent APIs. Useful for organisations with complex deployment requirements spanning multiple environments.
Architectural Disadvantages:
Proprietary technology creates vendor dependency. While Solace supports standard protocols, the management plane and advanced features are Solace specific. Migration to alternatives requires significant effort.
Cost structure includes licensing fees that become substantial at scale. Unlike open source alternatives, you pay for the messaging infrastructure beyond just compute and storage.
Operational model differs from cloud native patterns. Solace brokers are stateful infrastructure requiring specific operational expertise. Teams familiar with Kubernetes native patterns face a learning curve.
Connection model is broker centric rather than service mesh style. All messages flow through Solace brokers, which become critical infrastructure requiring high availability configuration.
Less ecosystem integration than cloud provider native services. While Solace runs on AWS, Azure, and GCP, it doesn’t integrate as deeply as native services like Amazon MQ or Google Pub/Sub.
Scale Ceiling: Very high with appropriate hardware or cluster configuration. Solace publishes benchmarks showing millions of messages per second.
Best For: Enterprises with existing Solace investments. Organisations requiring multi-protocol support. Regulated industries needing enterprise support contracts and compliance certifications. Hybrid deployments spanning on premises and cloud.
Comparison to Pekko + SSE:
Solace is a messaging infrastructure product; Pekko + SSE is an application architecture pattern. Solace provides the transport layer with sophisticated routing, persistence, and protocol support. Pekko + SSE builds the application logic with actors, clustering, and HTTP streaming.
For greenfield mobile chat, Pekko + SSE provides more control, lower cost, and better fit for modern cloud native deployment. For enterprises integrating chat into existing Solace infrastructure or requiring Solace’s specific capabilities (multi-protocol, hardware acceleration, compliance), Solace as the transport layer with application logic on top is viable.
The architectures can also combine: use Solace for backend service communication and durable message storage while using Pekko + SSE for client-facing connection handling. This hybrid leverages Solace’s enterprise messaging strengths while maintaining cloud native patterns at the edge.
8.5 Commercial Platforms: Pusher, Ably, PubNub
Managed real time platforms provide complete infrastructure as a service.
Architectural Advantages: Zero infrastructure to build or operate. Global edge presence included. Guaranteed SLAs with financial backing. Features like presence and message history built in.
Architectural Disadvantages: Significant cost at scale, often exceeding $10,000 monthly at millions of connections. Vendor lock in with proprietary APIs. Limited customisation for specific requirements. Latency to vendor infrastructure adds milliseconds to every message.
Scale Ceiling: High, but cost limited rather than technology limited.
Best For: When real time is a feature you need but not core competency. When engineering time is more constrained than infrastructure budget.
8.6 Erlang/Elixir with Phoenix Channels
The BEAM VM provides battle tested concurrency primitives, and Phoenix Channels offer WebSocket abstraction with presence and pub/sub.
Architectural Advantages: Exceptional concurrency model designed and proven at telecom scale. “Let it crash” supervision provides natural fault tolerance. WhatsApp scaled to billions of messages on BEAM. Per process garbage collection eliminates global GC pauses. Hot code reloading enables deployment without disconnecting users.
Architectural Disadvantages: Smaller talent pool than JVM ecosystem. Different operational model requires team investment. Library ecosystem is smaller than Java. Integration with existing JVM based systems requires interop complexity.
Scale Ceiling: Very high; BEAM is purpose built for this workload.
Best For: Teams with Erlang/Elixir expertise. Greenfield applications where the BEAM’s unique capabilities (hot reloading, per process GC) provide significant value.
8.7 Comparison Summary
| Architecture | Scale Ceiling | Operational Complexity | Development Speed | Cost at Scale | Talent Availability |
|---|---|---|---|---|---|
| Pekko + SSE | Very High | Medium | Medium | Low | High |
| Socket.IO | Medium | Medium | Fast | Medium | Very High |
| Firebase | High | Very Low | Very Fast | Very High | High |
| gRPC | Very High | Medium | Medium | Low | High |
| Solace | Very High | Medium-High | Medium | High | Medium |
| Commercial | High | Very Low | Fast | Very High | N/A |
| BEAM/Phoenix | Very High | Medium | Medium | Low | Low |
9. Capacity Planning Framework
9.1 Connection Density Expectations
With Java 25 on appropriately sized instances, expect approximately 500,000 to 750,000 concurrent SSE connections per node. Limiting factors in order of typical impact:
Memory: Each connection requires actor state, stream buffers, and HTTP/2 overhead. Budget 100 to 200 bytes per idle connection, 1KB to 2KB per active connection with buffers.
File Descriptors: Each TCP connection requires a kernel file descriptor. Default Linux limits (1024) are inadequate. Production systems need limits of 500,000 or higher.
Network Bandwidth: Aggregate message throughput eventually saturates network interfaces, typically 10Gbps on modern cloud instances.
9.2 Throughput Expectations
Message throughput depends on message size and processing complexity:
Simple Relay: 50,000 to 100,000 messages per second per node for small messages with minimal processing.
With Persistence: 20,000 to 50,000 messages per second when writing to database.
With Complex Processing: 10,000 to 30,000 messages per second with encryption, filtering, or transformation logic.
9.3 Latency Targets
Reasonable expectations for properly architected systems:
Same Region Delivery: p50 under 10ms, p99 under 50ms.
Cross Region Delivery: p50 under 100ms, p99 under 200ms (dominated by network latency).
Connection Establishment: Under 500ms including TLS handshake.
Reconnection with Resume: Under 200ms with HTTP/3, under 500ms with HTTP/2.
9.4 Cluster Sizing Example
For 10 million concurrent connections with 1 million active users generating 10,000 messages per second:
Connection Tier: 15 to 20 Pekko nodes (r6g.4xlarge) handling connection state and message routing.
Persistence Tier: 3 to 5 node ScyllaDB or Cassandra cluster for message storage.
Cache Tier: 3 node Redis cluster for presence and transient state if not using Pekko distributed data.
Load Balancing: Application Load Balancer with HTTP/2 support, or Network Load Balancer with Nginx fleet for HTTP/3.
10. Architectural Principles
Several principles guide successful mobile chat architecture regardless of specific technology choices.
10.1 Design for Reconnection
Mobile connections are ephemeral. Every component should assume disconnection happens constantly. Message delivery must survive connection loss. State reconstruction must be fast. Resume must be seamless.
This isn’t defensive programming; it’s accurate modelling of mobile reality.
10.2 Separate Logical Identity from Physical Location
Messages should route to User B, not to “the server holding User B’s connection.” When User B reconnects to a different server, routing should work without explicit updates.
Cluster sharding provides this naturally. Explicit routing tables require careful consistency management that’s difficult to get right.
10.3 Embrace Traffic Asymmetry
Chat is read heavy. Optimise the downstream path aggressively. The upstream path handles lower volume and can be simpler.
SSE plus HTTP POST matches this asymmetry. Bidirectional WebSocket overprovisions upload capacity.
10.4 Make Backpressure Explicit
When consumers can’t keep up, something must give. Explicit backpressure with configurable overflow strategies is better than implicit unbounded buffering that eventually exhausts memory.
Decide what happens when a client falls behind. Drop oldest messages? Drop newest? Disconnect? Make it a conscious architectural choice.
10.5 Eliminate Warmup Dependencies
Mobile load is spiky. Autoscaling must respond quickly. New instances must be immediately productive.
AOT compilation cache, pre warmed connection pools, and eager initialisation eliminate the warmup period that makes autoscaling ineffective.
10.6 Plan for Multi Region
Mobile users are globally distributed. Latency matters for chat quality. Eventually you’ll need presence in multiple regions.
Architecture decisions made for single region deployment affect multi region feasibility. Avoid patterns that assume single cluster or centralised state.
10.7 Accept Platform Constraints for Background Operation
Fighting mobile platform restrictions on background execution is futile. Design for the hybrid model: real time when foregrounded, push notification relay when backgrounded, efficient sync on return.
Architectures that assume persistent connections regardless of app state will disappoint users with battery drain or fail entirely when platforms enforce restrictions.
11. Conclusion
Mobile chat at scale requires architectural decisions that embrace mobile reality: unstable networks, battery constraints, background execution limits, multi device users, and constant connection churn.
Apache Pekko provides the actor model and cluster sharding that naturally fit connection state and message routing. Actors handle millions of mostly idle connections efficiently. Cluster sharding solves routing without centralised bottlenecks.
Server Sent Events match chat’s asymmetric traffic pattern while providing automatic reconnection and resume. HTTP/2 multiplexing reduces connection overhead. HTTP/3 with QUIC enables connection migration for seamless network transitions.
Java 25 removes historical JVM limitations. Virtual threads eliminate the thread per connection tension. Generational ZGC removes GC as a latency concern. AOT compilation caching makes autoscaling effective by eliminating warmup.
The background execution model requires accepting platform constraints rather than fighting them. Real time streaming when foregrounded, push notification relay when backgrounded, efficient sync on return. This hybrid approach works within mobile platform rules while providing the best achievable user experience.
EKS deployment requires attention to instance sizing, network configuration, and Pekko cluster discovery integration. Amazon Linux 2023 provides the appropriate base for high connection count workloads.
Alternative approaches like Solace provide enterprise messaging capabilities but with different operational models and cost structures. The choice depends on existing infrastructure, compliance requirements, and team expertise.
The architecture handles tens of millions of concurrent connections. More importantly, it handles mobile gracefully: network transitions don’t lose messages, battery impact remains reasonable, and users experience the instant message delivery they expect whether the app is foregrounded or backgrounded.
The key architectural insight is that mobile chat is a distributed systems problem with mobile specific constraints layered on top. Solve the distributed systems challenges with proven primitives, address mobile constraints with appropriate protocol choices, and leverage modern runtime capabilities. The result is a system that scales horizontally, recovers automatically, and provides the experience mobile users demand.