PostgreSQL 18 A Grown Up Release for Serious Workloads
PostgreSQL 18: A Grown-Up Release for Serious Workloads
Introduction
Every few years PostgreSQL delivers a release that does not just add features, but quietly shifts what the database is capable of at scale. PostgreSQL 18 is one of those releases.
This is not a flashy new syntax everywhere upgrade. Instead, Postgres 18 focuses on long-standing pain points that operators, performance engineers, and platform teams have lived with for years: inefficient IO, planner blind spots, fragile vacuum behaviour, limited observability, and replication features that worked in theory but were awkward in production.
If PostgreSQL 17 was about refinement, PostgreSQL 18 is about removing structural ceilings.
This post is a deep dive into what actually matters, why it matters, and how it changes the way Postgres behaves under real workloads.
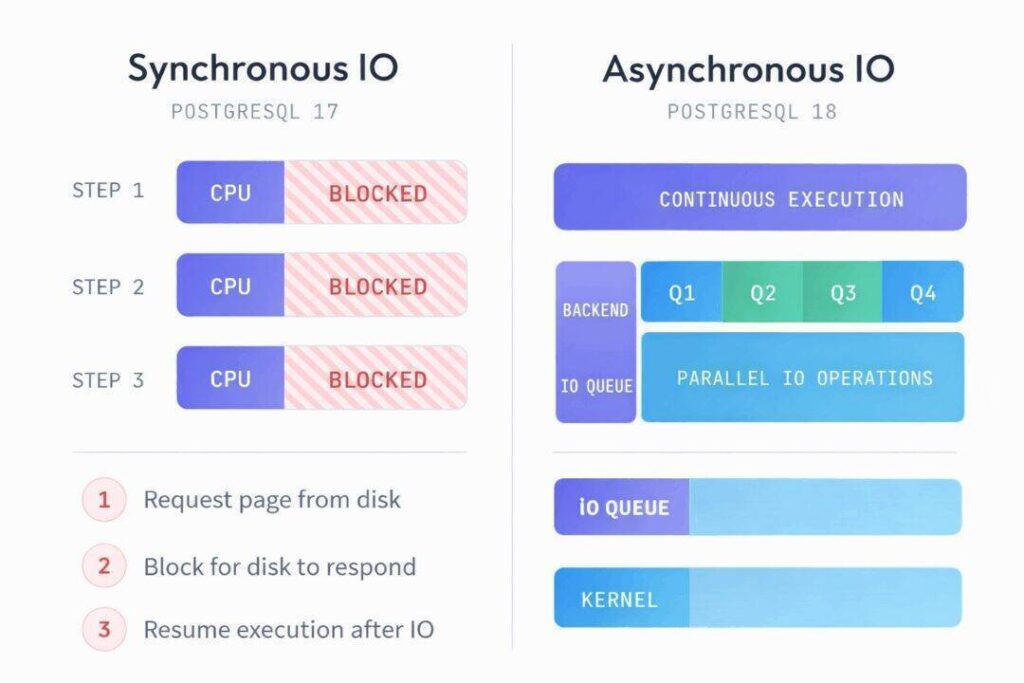
Asynchronous IO: Postgres Finally Learns to Overlap Work
For most of its life, PostgreSQL has relied on synchronous IO semantics. When a backend needed a page from disk, it issued a blocking pread() call and waited. The kernel might do some readahead via posix_fadvise(), but fundamentally the process stalled until the data arrived. On cloud storage where individual block reads routinely cost 1-4 milliseconds, these stalls compound rapidly. A sequential scan touching thousands of pages could spend more time waiting for disk than actually processing rows.
PostgreSQL 18 introduces a first-class asynchronous IO subsystem controlled by a new io_method parameter. The implementation provides three modes.
The sync mode preserves PostgreSQL 17 behaviour exactly: blocking reads with kernel-level prefetch hints. This exists for compatibility and troubleshooting.
The worker mode, which is the new default, introduces dedicated background IO worker processes. When a backend needs pages, it submits requests to a shared queue rather than blocking. The IO workers perform the actual reads and signal completion. From the backend’s perspective, execution continues while data arrives in parallel. The number of workers is controlled by io_workers (default 3), and these processes appear in pg_stat_activity with backend_type = 'io worker'.
The io_uring mode uses Linux’s io_uring interface (kernel 5.1+) for direct kernel submission without intermediate worker processes. This establishes a shared ring buffer between Postgres and the kernel, eliminating syscall overhead entirely. The ring buffer architecture means submissions and completions happen through memory operations rather than context switches. This requires building Postgres with --with-liburing.
The practical impact is substantial. Benchmarks consistently show 2-3x improvements in cold-cache sequential scan throughput when moving from sync to worker or io_uring. The improvement is most pronounced on cloud storage (EBS, Azure managed disks, GCP persistent disks) where per-request latency dominates. On local NVMe with sub-100 microsecond latency, the gains are smaller but still measurable.
The subsystem currently covers sequential scans, bitmap heap scans, and VACUUM operations. Write-path AIO is not included in this release.
Related parameters have been updated to reflect the new capabilities. effective_io_concurrency now defaults to 16 (up from 1), and this parameter actually matters when using worker or io_uring modes since it controls how many concurrent read-ahead requests the system will issue. The new io_combine_limit parameter controls how many pages can be combined into a single IO request.
Query Planner Improvements That Reduce “Why Didn’t It Use the Index”
Postgres has always had a conservative planner. Reliable, yes, but sometimes frustrating. PostgreSQL 18 removes several of those sharp edges.
B-tree Skip Scan
Historically, multicolumn B-tree indexes were only useful when queries constrained the leftmost columns. An index on (status, created_at, customer_id) worked brilliantly for queries filtering on status, but a query filtering only on customer_id would trigger a sequential scan despite the index existing.
PostgreSQL 18 introduces skip scan support. The planner can now generate a dynamic equality constraint internally that iterates through every distinct value in the leading column(s), effectively performing separate mini-scans for each value and skipping over irrelevant portions of the index.
The mechanism works by recognising that if a leading column has low cardinality (few distinct values), it is cheaper to perform N separate index descents than to scan the entire table. For an index on (region, category, date) where region has only 5 distinct values, a query on category = 'Electronics' becomes 5 targeted index lookups rather than a full table scan.
Skip scan appears in EXPLAIN output through a new “Index Searches” metric that shows how many separate index descents occurred. The optimisation is automatic when the planner estimates it will be beneficial, and requires no schema changes or hints.
The feature is most effective when leading columns that you are omitting have relatively few distinct values. It becomes less beneficial as the number of distinct values increases, since each distinct value requires a separate index descent.
Self-Join Elimination
The planner can now eliminate unnecessary self-joins when it can prove they add no semantic value. This helps ORM-generated queries that often produce redundant join patterns, complex views that accreted joins over time, and legacy SQL that nobody wants to refactor. The planner detects when a table is joined to itself on its primary key with no additional filtering, and removes the redundant scan entirely.
Improved OR/IN Planning
Postgres 18 improves index usage across OR conditions, IN lists, and set operations like INTERSECT and EXCEPT. These are incremental changes individually, but collectively they mean fewer obviously bad plans in production where the planner previously gave up and fell back to sequential scans.
Vacuum: Eager Freezing and Dynamic Worker Scaling
Vacuum has always been one of Postgres’s most misunderstood subsystems. It works until it does not, and when it does not, the fix is usually “vacuum harder”, which makes things worse. PostgreSQL 18 introduces fundamental changes to how vacuum handles freezing and worker allocation.
The Freezing Problem
PostgreSQL uses 32-bit transaction IDs that wrap around after approximately 2 billion transactions. To prevent wraparound, vacuum must periodically “freeze” old tuples, marking them as visible to all transactions. Historically, this created two problems.
First, normal vacuums would skip pages that were all-visible in the visibility map, only freezing opportunistically. This meant large append-only or slowly-changing tables accumulated unfrozen pages until the vacuum_freeze_table_age threshold forced an aggressive vacuum that scanned the entire table.
Second, these aggressive vacuums were unpredictable IO storms. A table that received light maintenance for months would suddenly demand a full-table scan, spiking latency and storage throughput exactly when you least expected it.
Eager Freezing
PostgreSQL 18 introduces eager freezing, controlled by the vacuum_max_eager_freeze_failure_rate parameter (default 0.03 or 3%). Normal vacuums can now proactively scan and freeze all-visible pages even when not in aggressive mode.
The mechanism divides the table into regions and tracks freezing success and failure rates. When vacuum encounters an all-visible page, it attempts to freeze it. If the page can be frozen (all tuples are old enough), it is marked all-frozen in the visibility map. If not (some tuples are too recent), this counts as a failure.
Vacuum continues eager freezing until failures exceed the configured rate. Successful freezes are internally capped at 20% of all-visible but not all-frozen pages per vacuum, spreading the work across multiple vacuum cycles.
The result is that freezing work gets amortized across normal vacuums rather than accumulating for a massive aggressive vacuum. Tables maintain a lower baseline of unfrozen pages, and aggressive vacuums, when they do occur, have far less work to do.
Dynamic Autovacuum Worker Scaling
Previously, changing autovacuum_max_workers required a server restart. PostgreSQL 18 separates the concepts into autovacuum_worker_slots (maximum slots reserved at startup, requires restart) and autovacuum_max_workers (active limit, reloadable via SIGHUP).
This means you can respond to bloat emergencies by temporarily increasing worker count without a maintenance window. Set autovacuum_worker_slots to your maximum anticipated need at startup, then adjust autovacuum_max_workers dynamically based on current conditions.
Vacuum on Partitioned Tables
VACUUM and ANALYZE now extend recursively into child tables by default for inheritance-based partitioning, matching the behaviour that declarative partitioning already had. Use the ONLY keyword when you want to process just the parent.
A significant new capability is running ANALYZE ONLY on a partitioned parent. This refreshes parent-level statistics without scanning all partitions, useful when partition statistics are current but you need accurate parent-level estimates for better query planning.
Safer Tail Truncation
Vacuum’s tail truncation step (removing empty pages from the end of a table) acquires an ACCESS EXCLUSIVE lock that gets replayed on hot standbys, briefly stalling reads. PostgreSQL 18 adds controls for tuning how aggressively vacuum truncates, which matters for time-series workloads where tables have predictable growth patterns and truncation provides minimal benefit.
Partitioned Tables and Prepared Statement Memory
PostgreSQL 18 addresses a long-standing pain point where prepared statements on heavily partitioned tables caused excessive memory consumption through its improvements to partitionwise joins and plan caching.
The underlying problem was architectural. When executing a prepared statement with a generic plan against a partitioned table, PostgreSQL had to lock all partitions during plan validation, not just the partitions that would actually be accessed. For a table with 365 daily partitions and 3 indexes each, this meant acquiring over 1,400 locks just to validate a plan that might only touch one partition.
Worse, each partition’s metadata had to be loaded into the connection’s local relcache memory. Sessions running prepared statements against heavily partitioned tables would accumulate gigabytes of cached metadata, leading to OOM events under load.
The PostgreSQL 18 release notes indicate work on partition pruning for initial pruning phases that would avoid locking partitions that get pruned away, alongside memory reduction improvements for partitionwise joins. While a complete fix that performs initial pruning before plan validation was attempted (commit 525392d5), it was reverted (commit 1722d5eb) due to complications discovered during testing.
The practical improvements in PostgreSQL 18 come from reduced memory usage in partitionwise join handling (Richard Guo, Tom Lane, Ashutosh Bapat) and improved cost estimates for partition queries. Combined with the existing plan_cache_mode = force_custom_plan workaround, large partition deployments should see improved memory behaviour, though the fundamental prepared statement + generic plan + many partitions issue remains an area of active development.
Observability: You Can Finally See Where the Time Went
Postgres has long suffered from “just enough observability to be dangerous.” PostgreSQL 18 fills critical gaps.
Per-Backend IO Statistics
The pg_stat_io view now reports read bytes, write bytes, WAL IO, and extend operations with enough granularity to answer questions like: Is this query CPU-bound or IO-bound? Are we slow because of WAL writes or data reads? Which backend is actually hammering storage?
For AIO specifically, the new pg_aios system view provides visibility into asynchronous IO operations and requests currently in progress. Combined with pg_stat_activity filtering for backend_type = 'io worker', you can observe the entire IO pipeline.
Enhanced EXPLAIN ANALYZE Output
EXPLAIN ANALYZE now automatically includes BUFFERS output, eliminating the need to remember to add it. The output includes index lookup counts per index scan node, which is critical for understanding skip scan behaviour and multi-column index efficiency.
Material, Window Aggregate, and CTE nodes now report memory and disk usage. This addresses the long-standing mystery of “where did all my work_mem go” in complex analytical queries.
Logical Replication Grows Up
Logical replication has existed for years, but many teams treated it as “promising but sharp.” PostgreSQL 18 removes several of those sharp edges.
Generated Columns Can Replicate
Previously, generated columns had to be recomputed on the subscriber or were not supported cleanly at all. PostgreSQL 18 allows generated column values to be published directly. This matters for heterogeneous subscribers where recomputation might not be possible, downstream analytics systems that need the computed values, and schema evolution scenarios where generated column definitions differ between publisher and subscriber.
Conflict Visibility
Replication conflicts are now logged explicitly and visible via statistics views. This shifts logical replication from “hope it works” to something you can actually operate and debug confidently.
Upgrades Hurt Less
Statistics Survive pg_upgrade
Historically, upgrading meant weeks of suboptimal plans while statistics slowly rebuilt through autovacuum. PostgreSQL 18 allows pg_upgrade to preserve optimizer statistics, meaning better plans immediately after upgrade, fewer post-upgrade fire drills, and less pressure to run ANALYZE on every table manually.
Things That May Bite You
No major release is free of sharp edges. Things to plan for:
Data checksums are now enabled by default for new clusters created with initdb. Existing clusters are not affected, but new deployments will have checksums active unless explicitly disabled.
Time zone abbreviation resolution has changed subtly. If your application relies on ambiguous abbreviations, test thoroughly.
Some vacuum and analyze behaviours differ for partitioned tables with the new recursive defaults. Scripts that relied on explicit partition-by-partition vacuum may need adjustment.
Full-text and trigram indexes may need reindexing depending on collation providers, particularly if upgrading from pre-ICU configurations.
Conclusion: PostgreSQL 18 Raises the Ceiling
PostgreSQL 18 does not radically change how you use Postgres. It changes how far you can push it.
Asynchronous IO removes a long-standing architectural bottleneck. Skip scan and planner improvements reduce manual index gymnastics. Eager freezing and dynamic vacuum scaling make large systems calmer and more predictable. Logical replication finally feels production-ready.
This is the kind of release that platform teams quietly celebrate, not because it adds shiny toys, but because it makes outages rarer, upgrades safer, and performance more understandable.
Postgres 18 is not about doing new things. It is about doing serious things, reliably, at scale.