Why Bigger Banks Were Historically More Fragile and Why Architecture Determines Resilience
1. Size Was Once Mistaken for Stability
For most of modern banking history, stability was assumed to increase with size. The thinking was the bigger you are, the more you should care, the more resources you can apply to problems. Larger banks had more capital, more infrastructure, and more people. In a pre-cloud world, this assumption appeared reasonable.
In practice, the opposite was often true.
Before cloud computing and elastic infrastructure, the larger a bank became, the more unstable it was under stress and the harder it was to maintain any kind of delivery cadence. Scale amplified fragility. In 2025, architecture (not size) has become the primary determinant of banking stability.
2. Scale, Fragility, and Quantum Entanglement
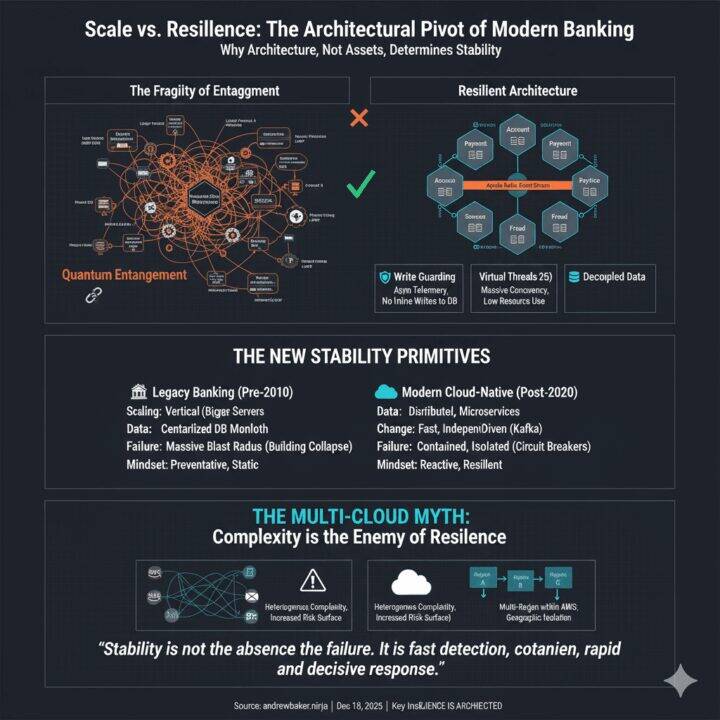
Traditional banking platforms were built on vertically scaled systems: mainframes, monolithic databases, and tightly coupled integration layers. These systems were engineered for control and predictability, not for elasticity or independent change.
As banks grew, they didn’t just add clients. They added products. Each new product introduced new dependencies, shared data models, synchronous calls, and operational assumptions. Over time, this created a state best described as quantum entanglement.
In this context, quantum entanglement refers to systems where:
- Products cannot change independently
- A change in one area unpredictably affects others
- The full impact of change only appears under real load
- Cause and effect are separated by time, traffic, and failure conditions
The larger the number of interdependent products, the more entangled the system becomes.
2.1 Why Entanglement Reduces Stability
As quantum entanglement increases, change becomes progressively riskier. Even small modifications require coordination across multiple teams and systems. Release cycles slow and defensive complexity increases.
Recovery also becomes harder. When something breaks, rolling back a single change is rarely sufficient because multiple products may already be in partially failed or inconsistent states.
Fault finding degrades as well. Logs, metrics, and alerts point in multiple directions. Symptoms appear far from root causes, forcing engineers to chase secondary effects rather than underlying faults.
Most importantly, blast radius expands. A fault in one product propagates through shared state and synchronous dependencies, impacting clients who weren’t using the originating product at all.
The paradox is that the very success of large banks (broad product portfolios) becomes a direct contributor to instability.
3. Why Scale Reduced Stability in the Pre-Cloud Era
Before cloud computing, capacity was finite, expensive, and slow to change. Systems scaled vertically, and failure domains were large by design.
As transaction volumes and product entanglement increased, capacity cliffs became unavoidable. Peak load failures became systemic rather than local. Recovery times lengthened and client impact widened.
Large institutions often appeared stable during normal operation but failed dramatically under stress. Smaller institutions appeared more stable largely because they had fewer entangled products and simpler operational surfaces (not because they were inherently better engineered).
Capitec itself experienced this capacity cliff, when its core banking SQL DB hit a capacity cliff in August 2022. In order to recover the service, close to 100 changes were made which resulted in a downtime of around 40 hrs. The wider service recovery took weeks, with missed payments a duplicate payments being fixed on a case by case basis. It was at this point that Capitec’s leadership drew a line in the sand and decided to totally re-engineer its entire stack from the ground up in AWS. This blog post is really trying to share a few nuggets from the engineering journey we went on, and hopefully help others all struggling the with burden of scale and hardened synchronous pathways.
4. Cloud Changed the Equation (But Only When Architecture Changed)
Cloud computing made it possible to break entanglement, but only for organisations willing to redesign systems to exploit it.
Horizontal scaling, availability zone isolation, managed databases, and elastic compute allow products to exist as independent domains rather than tightly bound extensions of a central core.
Institutions that merely moved infrastructure to the cloud without breaking product entanglement continue to experience the same instability patterns (only on newer hardware).
5. An Architecture Designed to Avoid Entanglement
Capitec represents a deliberate rejection of quantum entanglement.
Its entire App production stack is cloud native on AWS, Kubernetes, Kafka and Postgres. The platform is well advanced in rolling out new Java 25 runtimes, alongside ahead of time (AOT) optimisation to further reduce scale latency, improve startup characteristics, and increase predictability under load. All Aurora Serverless are setup with read replicas, offloading read pressure from write paths. All workloads are deployed across three availability zones, ensuring resilience. Database access is via the AWS JDBC wrapper (which enables extremely rapid failovers, outside of DNS TTLs)
Crucially, products are isolated by design. There is no central product graph where everything depends on everything else. But, a word of caution, we are “not there yet”. We will always have edges that can hurt and we you hit an edge at speed, sometimes its hard to get back up on your feet. Often you see that the downtime you experienced, simply results in pent up demand. Put another way, the volume that took your systems offline, is now significantly LESS than the volume thats waiting for you once you recover! This means that you somehow have to magically add capacity, or optimise code, during an outage in order to recover the service. You will often say “Rate Limiting” fan club put a foot forward when I discuss burst recoverability. I personally don’t buy this for single entity services (for a complex set of reasons). For someone like AWS, it absolutely makes sense to carry the enormous complexity of guarding services with rate limits. But I don’t believe the same is true for a single entity ecosystem, in these instances, offloading is normally a purer pathway.
6. Write Guarding as a Stability Primitive
Capitec’s mobile and digital platforms employ a deliberate **write guarding** strategy.
Read only operations (such as logging into the app) are explicitly prevented from performing inline write operations. Activities like audit logging, telemetry capture, behavioural flags, and notification triggers are never executed synchronously on high volume read paths.
Instead, these concerns are offloaded asynchronously using Amazon MSK (Managed Streaming for Apache Kafka) or written to in memory data stores such as Valkey, where they can be processed later without impacting the user journey.
This design completely removes read-write contention from critical paths. Authentication storms, balance checks, and session validation no longer compete with persistence workloads. Under load, read performance remains stable because it is not coupled to downstream write capacity.
Critically, write guarding prevents database maintenance pressure (such as vacuum activity) from leaking into high volume events like logins. Expensive background work remains isolated from customer facing read paths.
Write guarding turns one of the most common failure modes in large banking systems (read traffic triggering hidden writes) into a non event. Stability improves not by adding capacity, but by removing unnecessary coupling.
7. Virtual Threads as a Scalability Primitive
Java 25 introduces mature virtual threading as a first class concurrency model. This fundamentally changes how high concurrency systems behave under load.
Virtual threads decouple application concurrency from operating system threads. Instead of being constrained by a limited pool of heavyweight threads, services can handle hundreds of thousands of concurrent blocking operations without exhausting resources.
Request handling becomes simpler. Engineers can write straightforward blocking code without introducing thread pool starvation or complex asynchronous control flow.
Tail latency improves under load. When traffic spikes, virtual threads queue cheaply rather than collapsing the system through thread exhaustion.
Failure isolation improves. Slow downstream calls no longer monopolise scarce threads, reducing cascading failure modes.
Operationally, virtual threads align naturally with containerised, autoscaling environments. Concurrency scales with demand, not with preconfigured thread limits.
When combined with modern garbage collectors and ahead of time optimisation, virtual threading removes an entire class of concurrency related instability that plagued earlier JVM based banking platforms.
8. Nimbleness Emerges When Entanglement Disappears
When blast zones and integration choke points disappear, teams regain the ability to move quickly without increasing systemic risk.
Domains communicate through well defined RESTful interfaces, often across separate AWS accounts, enforcing isolation as a first class property. A failure in one domain does not cascade across the organisation.
To keep this operable at scale, Capitec uses Backstage (via an internal overlay called ODIN) as its internal orchestration and developer platform. All AWS accounts, services, pipelines, and operational assets are created to a common standard. Teams consume platform capability rather than inventing infrastructure.
This eliminates configuration drift, reduces cognitive load, and ensures that every new product inherits the same security, observability, and resilience characteristics.
The result is nimbleness without fragility.
9. Operational Stability Is Observability Plus Action
In entangled systems, failures are discovered by clients and stability is measured retrospectively.
Capitec operates differently. End to end observability through Instana and its in house AI platform, Neo, correlates client side errors, network faults, infrastructure signals, and transaction failures in real time. Issues are detected as they emerge, not after they cascade.
This operational awareness allows teams to intervene early, contain issues quickly, and reduce client impact before failures escalate.
Stability, in this model, is not the absence of failure. It is fast detection, rapid containment, and decisive response.
10. Fraud Prevention Without Creating New Entanglement
Fraud is treated as a first class stability concern rather than an external control.
Payments are evaluated inline as they move through the bank. Abnormal velocity, behavioural anomalies, and account provenance are assessed continuously. Even fraud reported in the call center is immediately visible to other clients paying from the Capitec App. Clients are presented with conscience pricking prompts for high risk payments; these frequently stop fraud as the clients abandon the payment when presented with the risks.
Capitec runs a real time malware detection engine directly on client devices. This engine detects hooks and overlays installed by malicious applications. When malware is identified, the client’s account is immediately stopped, preventing fraudulent transactions before they occur.
Because fraud controls are embedded directly into the transaction flow, they don’t introduce additional coupling or asynchronous failure modes.
The impact is measurable. Capitec’s fraud prevention systems have prevented R300 million in client losses from fraud. In November alone, these systems saved clients a further R60 million in fraud losses.
11. The Myth of Stability Through Multicloud
Multicloud is often presented as a stability strategy. In practice, it is largely a myth.
Running across multiple cloud providers does not remove failure risk. It compounds it. Cross cloud communication can typically only be secured using IP based controls, weakening security posture. Operational complexity increases sharply as teams must reason about heterogeneous platforms, tooling, failure modes, and networking behaviour.
Most critically, multicloud does not eliminate correlated failure. If either cloud provider becomes unavailable, systems are usually unusable anyway. The result is a doubled risk surface, increased operational risk, and new inter cloud network dependencies (without a corresponding reduction in outage impact).
Multicloud increases complexity, weakens controls, and expands risk surface area without delivering meaningful resilience.
12. What Actually Improves Stability
There are better options than multicloud.
Hybrid cloud with anti-affinity on critical channels is one. For example, card rails can be placed in two physically separate data centres so that if cloud based digital channels are unavailable, clients can still transact via cards and ATMs. This provides real functional resilience rather than architectural illusion.
Multi region deployment within a single cloud provider is another. This provides geographic fault isolation without introducing heterogeneous complexity. However, this only works if the provider avoids globally scoped services that introduce hidden single points of failure. At present, only AWS consistently supports this model. Some providers expose global services (such as global front doors) that introduce global blast radius and correlated failure risk.
True resilience requires isolation of failure domains, not duplication of platforms.
13. Why Traditional Banks Still Struggle
Traditional banks remain constrained by entangled product graphs, vertically scaled cores, synchronous integration models, and architectural decisions from a different era. As product portfolios grow, quantum entanglement increases. Change slows, recovery degrades, and outages become harder to diagnose and contain.
Modernisation programmes often increase entanglement temporarily through dual run architectures, making systems more fragile before they become more stable (if they ever do).
The challenge is not talent or ambition. It is the accumulated cost of entanglement.
14. Stability at Scale Without the Traditional Trade Off
Capitec’s significance is not that it is small. It is that it is large and remains stable.
Despite operating at massive scale with a broad product surface and high transaction volumes, stability improves rather than degrades. Scale does not increase blast radius, recovery time, or change risk. It increases parallelism, isolation, and resilience.
This directly contradicts historical banking patterns where growth inevitably led to fragility. Capitec demonstrates that with the right architecture, scale and stability are no longer opposing forces.
15. Final Thought
Before cloud and autoscaling, scale and stability were inversely related. The more products a bank had, the more entangled and fragile it became.
In 2025, that relationship can be reversed (but only by breaking entanglement, isolating failure domains, and avoiding complexity masquerading as resilience).
Doing a deal with a cloud provider means nothing if transformation stalls inside the organisation. If dozens of people carry the title of CIO while quietly pulling the handbrake on the change that is required, the outcome is inevitable regardless of vendor selection.
There is also a strategic question that many institutions avoid. If forced to choose between operating in a jurisdiction that is hostile to public cloud or accessing the full advantages of cloud, waiting is not a strategy. When that jurisdiction eventually allows public cloud, the market will already be populated by banks that moved earlier, built cloud native platforms, and are now entering at scale.
Capitec is an engineering led bank whose stability and speed increase with scale. Traditional banks remain constrained by quantum entanglement baked into architectures from a different era.
These outcomes are not accidental. They are the inevitable result of architectural and organisational choices made years ago, now playing out under real world load.