How to make an offline copy of a static website using wget and hosting on AWS S3 with CloudFront
I have an old website that I want to avoid the hosting costs and so just wanted to download the website and run it from an AWS S3 bucket using Cloud Front to publish the content. Below are the steps I took to do this:
First download the website to your laptop
$ wget
--recursive
--no-clobber
--page-requisites
--html-extension
--convert-links
--no-check-certificate
--restrict-file-names=unix
--domains archive.andrewbaker.ninja
--no-parent
https://archive.andrewbaker.ninja/
$ cd archive.andrewbaker.ninja
$ lsBelow is a summary of the parameters (inc common alternatives):
–recursive: Wget is capable of traversing parts of the Web (or a single HTTP or FTP server), following links and directory structure. We refer to this as to recursive retrieval, or recursion.
–no-clobber: If a file is downloaded more than once in the same directory, Wget’s behavior depends on a few options, including `-nc’. In certain cases, the local file will be clobbered, or overwritten, upon repeated download. In other cases it will be preserved. When running Wget without `-N’, `-nc’, or `-r’, downloading the same file in the same directory will result in the original copy of file being preserved and the second copy being named `file.1′. If that file is downloaded yet again, the third copy will be named `file.2′, and so on. When `-nc’ is specified, this behavior is suppressed, and Wget will refuse to download newer copies of `file‘. Therefore, “no-clobber” is actually a misnomer in this mode–it’s not clobbering that’s prevented (as the numeric suffixes were already preventing clobbering), but rather the multiple version saving that’s prevented. When running Wget with `-r’, but without `-N’ or `-nc’, re-downloading a file will result in the new copy simply overwriting the old. Adding `-nc’ will prevent this behavior, instead causing the original version to be preserved and any newer copies on the server to be ignored. When running Wget with `-N’, with or without `-r’, the decision as to whether or not to download a newer copy of a file depends on the local and remote timestamp and size of the file (see section Time-Stamping). `-nc’ may not be specified at the same time as `-N’. Note that when `-nc’ is specified, files with the suffixes `.html’ or (yuck) `.htm’ will be loaded from the local disk and parsed as if they had been retrieved from the Web.
–page-requisites: This causes wget to download all the files that are necessary to properly display a given HTML page which includes images, css, js, etc. –adjust-extension Preserves proper file extensions for . html, . css, and other assets
–html-extension: This adds .html after the downloaded filename, to make sure it plays nicely on whatever system you’re going to view the archive on
–convert-links: After the download is complete, convert the links in the document to make them suitable for local viewing. This affects not only the visible hyperlinks, but any part of the document that links to external content, such as embedded images, links to style sheets, hyperlinks to non-HTML content, etc.
–no-check-certificate: Don’t check the server certificate against the available certificate authorities. Also don’t require the URL host name to match the common name presented by the certificate.
–restrict-file-names: By default, Wget escapes the characters that are not valid or safe as part of file names on your operating system, as well as control characters that are typically unprintable. This option is useful for changing these defaults, perhaps because you are downloading to a non-native partition”. So unless you are not downloading to non-native partition you do not need to restrict file names by OS. its automatic. Additionally: “The values ‘unix’ and ‘windows’ are mutually exclusive (one will override the other)”
–domains: Limit spanning to specified domains
–no-parent: If you don’t want wget to descend down to the parent directory, use -np or –no-parent option. This instructs wget not to ascend to the parent directory when it hits references like ../ in href links.
Upload Files to S3 Bucket
Next upload the files to your S3 bucket. First move into the relevant bucket, then perform the recursive upload.
$ cd archive.andrewbaker.ninja
$ ls .
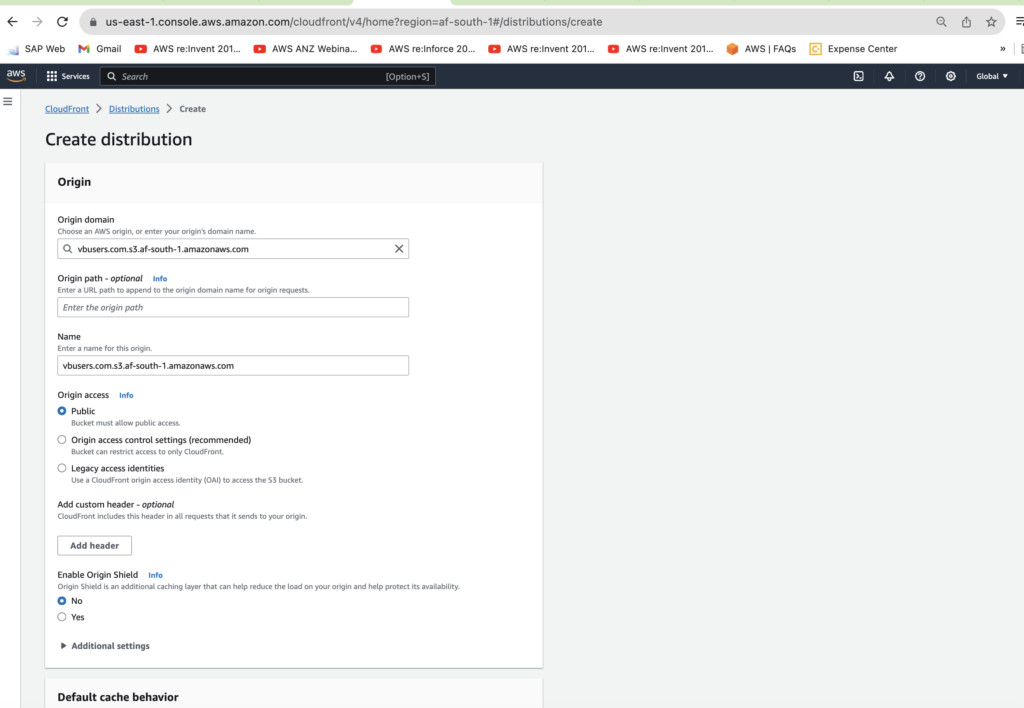
$ aws s3 cp . s3://vbusers.com/ --recursiveCreate a CloudFront Distribution from an S3 Bucket
Finally go to CloudFront and create a distribution from the S3 Bucket you just created. You can pretty much use the default settings. Note: you will need to wait a few minutes before you browse to the distributions domain name: