How to Optimise your Technology Teams Structure to improve flow
I have seen many organisations restructure their technology teams over and over, but whichever model they opt for – they never seem to be able to get the desired results with respect to speed, resilience and quality. For this reason organisations will tend to oscillate from centralised teams, which are organised around skills and reuse, to federated teams that are organised around products and time to market. This article exams the failure modes for both centralised and federated teams and then questions whether there are better alternatives?
Day 1: Centralisation
Centralised technology teams tend to create frustrated product teams, long backlogs and lots of prioritisation escalations. Quality is normally fairly consistent (it can be consistently bad or consistently good), but speed is generally considered problematic.
These central teams will often institute some kind of ticketing system to coordinate their activities. They will even use tickets to coordinate activities between their own, narrowly focused central teams. These teams will create reports that demonstrate “millions” of tickets have been closed each month. This will be sold as some form of success / progress. Dependent product teams, on the other hand, will still struggle to get their work loads into production and frequently escalate the bottlenecks created using a centralised approach.
Central teams tend to focus on reusability, creating large consolidated central services and cost compression. Their architecture will tend to create massive “risk concentrators”, whereby they reuse the same infrastructure for the entire organisation. Any upgrades to these central services tend to be a life threatening event, making things like minor version changes and even patching extremely challenging. These central services will have poorly designed logical boundaries. This means that “bad” consumers of these shared services, can create saturation outages which affect the entire enterprise. These teams will be comfortable with mainframes, large physical datacenters and have a poor culture of learning. The technology stack will be at least 20 years old and you will often hear the term, “tried and tested”. They will view change as a bad thing and will create reports showing that change is causing outages. They will periodically suggest a slow down, or freezes to combat the great evil of “change”. There will be no attempt made to get better at delivering change and everything will be described as a “journey”. It will take years to get anything done in this world and the technology stack will be a legacy, expensive, immutable blob of tightly coupled vendor products.
Day 2: Lets Federate!
Eventually delivery pressure builds and the organisation capitulates into the chaotic world of federation. This is quickly followed by an explosion in headcount, as each product team attempts to utopian state of “end to end autonomy”. End to end autonomy, is the equivalent of absolute freedom – it simple does not and cannot exist. Why can’t you have an absolute state of full autonomy? It turns out that unless you’re a one product startup, you will have to share certain services and channels with other products. This means that any single products “autonomy” expressed in any shared channel/framework, ends up becoming another products “constraint”.
A great example of this is a client facing channel, like an app or a web site. Imagine if you carved up a channel into little product size pieces. Imagine how hard it would be to support your clients, where do you route support queries? Even something basic, like trying to keep the channel available would be difficult, as there is no single team stopping other teams from injecting failure planes and vendor SDKs into critical shared areas. In this world, each product does what it wants, when it wants, how it wants and the channel ends up yielding an inconsistent, frustrating and unstable customer experience. No product team will ever get around to dealing with complex issues, like fraud, cyber security or even basics like observability. Instead they will naturally chase PnL. In the end, you will have to resort to using social media to field complaints and resolve issues. Game theory depicts this as something called the “Tragedy of the Commons” – it’s these common assets that die in the federated world.
In the federated world, the lack of scope for staff results in ballooning your headcount and aggregating roles across multiple disciplines for the staff you have managed to hire. Highly skilled staff tend to get very bored with their “golden cages” and search out more challenging roles at other companies.
You will see lots of key man risk in this world. Because product teams can never fully fund their end to end autonomy – you will commonly see individuals that looks after networking, DBA and storage and cyber. When this person eventually resigns, the risks from their undocumented “tactile fixes” quickly start to materialise as the flow of outages starts to takes a grip. You will struggle to hire highly skilled resources into this model, as the scope of the roles you advertise are restrictively narrow, eg a DBA to look after a single database, a senior UX person to look after 3 screens. Obviously, if you manage to hire a senior UX person, you can then show them the 2 databases you also want them to manage 😂
If not this, then what?
Is the issue that we didn’t try hard enough? Maybe we should have given the model more time to bear fruit? Maybe we didn’t get the teams buy in? So what I am saying? I am saying BOTH federated and centralised models will eventually fail, because they are extremes. These are not the only choices on the table, there are a vast number of states in between, depending on your architecture, the size of your organization and the pools of skills you have.
Before you start tinkering with your organisations structure it’s key that you agree on what is the purpose of your organisation structure? Specifically – what are you trying to do and how are you trying to do it? Centralists will argue that economies of scale, better quality are key. But the federation proponents will point to time to market and speed. So how do you design your organisation?
There are two main parameters that you should try to optimise for:
- Domain Optimisation: Design your structure around people and skills (from the centralised model). Give your staff enough domain / scope to be able to solve complex problems and add value across multiple products in your enterprise. The benefit of teams with wide domains, is that you can put your best resources on your biggest problems. But watch out, because as the domain of each team increases, so will the dependencies on this team.
- Dependency Optimisation: Design your structure around flow/output by removing dependencies and enabling self service (from the federated model). Put simply, try to pay down dependencies by changing your architecture to enable self service such that product teams can execute quickly, whilst benefiting from high quality, reusable building blocks.
These two parameters are antagonistic, with your underlying architecture being the lever to change the gradient of the yield.
Domain Optimisation
Your company cannot be successful, if you narrow the scope of your roles down to a single product. Senior, skilled engineers need domain and companies need to make sure that complicated problems flow to those who can best solve these problems. Having myopically scoped roles, not only balloons your headcount, it also means that your best staff might be sat on your easiest problems. More than this, how do you practically hire the various disciplines you need, if you’re scope is restricted to a single product that might only occasionally use a fraction of your skills.
You need to give staff from a skill / discipline enough scope to make sure they are stretched and that you’re getting value from them. If this domain creates a bottleneck, then you should look to fracture these pools of skills by creating multiple layers. Keeping one team close to operational workloads (to reduce dependencies) and a second team looking a more strategic problems. For example, you can have a UX team look after a single channel, but also have a strategic UX team look after more long dated / complex UX challenges (like peer analysis, telemetry insights, redesigns etc).
Dependency Optimisation
As we already discussed, end to end autonomy is a bogus construct. But teams should absolutely look to shed as many dependencies as possible, so that they can yield flow without begging other teams to do their jobs. There are two ways of reducing dependency:
- Reduce the scope of a role and look at creating multiple pools of skills with different scopes.
- Change your technology architecture.
Typically only item 1) is considered, and this is the crux of this article. Performing periodic org structure rewrites simply gives you a new poison to swallow. This is great, maybe you like strawberry flavoured arsenic! But my question is, why not stop taking poison altogether?
If you look at the anecdotal graph below you can see the relationship between domain / scope and dependency. This graph shows you that as you reduce domain you reduce dependency. Put simply, the lower your dependancies them more “federated” your organisation and the more domain your staff have the more “centralised” your organisation is.
What you will also observe that poorly architectured systems exhibit a “dependency cliff”. What this means is that even as you reduce the scope of your roles – your will not see any dependency benefit. This is because your systems are so tightly coupled that any amount of org structure gymnastics will not give you lower dependencies. If you attempt to carve up any shared systems that are exhibiting a dependency cliff, you have to hire more staff, you will have more outages, less output and more escalations.
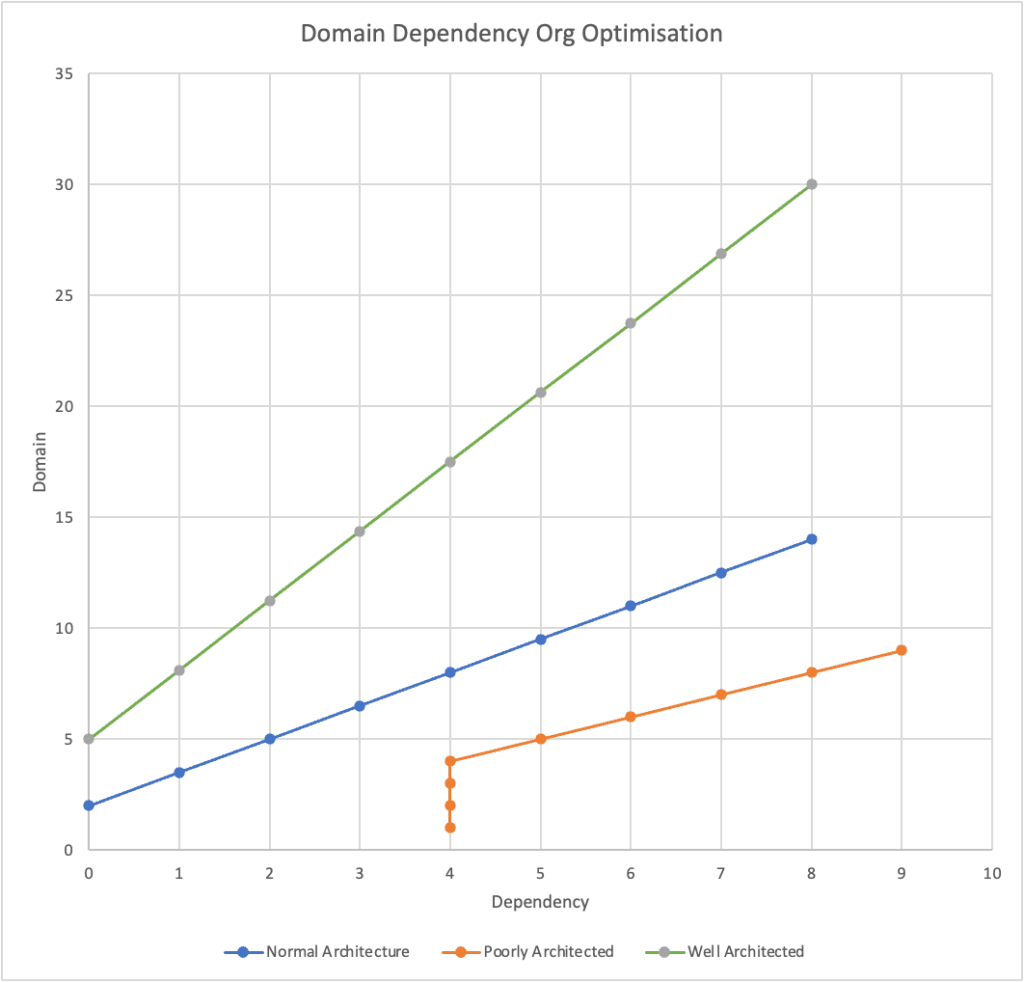
To resolve any dependency cliffs, you have a few choices:
- De-aggregate/re-architect workloads. If all your products sit in a single core banking platform, then do NOT buy a new core banking platform. Instead, rather rearchitect these products, to separate the shared services (eg ledger) from the product services (eg home loans). This is a complex topic and needs a detailed debate.
- Optimise workloads. Acknowledge that a channel or platform can be a product in its own right and ensure that most of the changes product teams want to make on a channel / platform can be automated. Create product specific pipelines, create product enclaves (eg PWA), allow the product teams the ability to store and update state on the channel without having to go through testing release cycles.
- Ensure any central services are opensourced. This will enable product teams to contribute changes and not feel “captive” to the cadence of central teams.
- Deliver all services with REST APIs to ensure all shared services can be self-service.
The Conclusion
There is no easy win when it comes to org structure, because its typically your architecture that drives all your issues. So shuffling people around from one line manager to another will achieve very little. If you want to be successful you will need to look at each service and product in detail and try and remove dependencies by making architectural changes such that product teams can self service wherever possible. When you remove architectural constraints, you will steepen the gradient of the line and give your staff broad domains, without adding dependencies and bottlenecks.
Am done with this article. I really thought I was going to be quick to write and I have run out of energy. I will probably do another push on this in a few weeks. Please DM with spelling mistakes or something that doesn’t make sense.