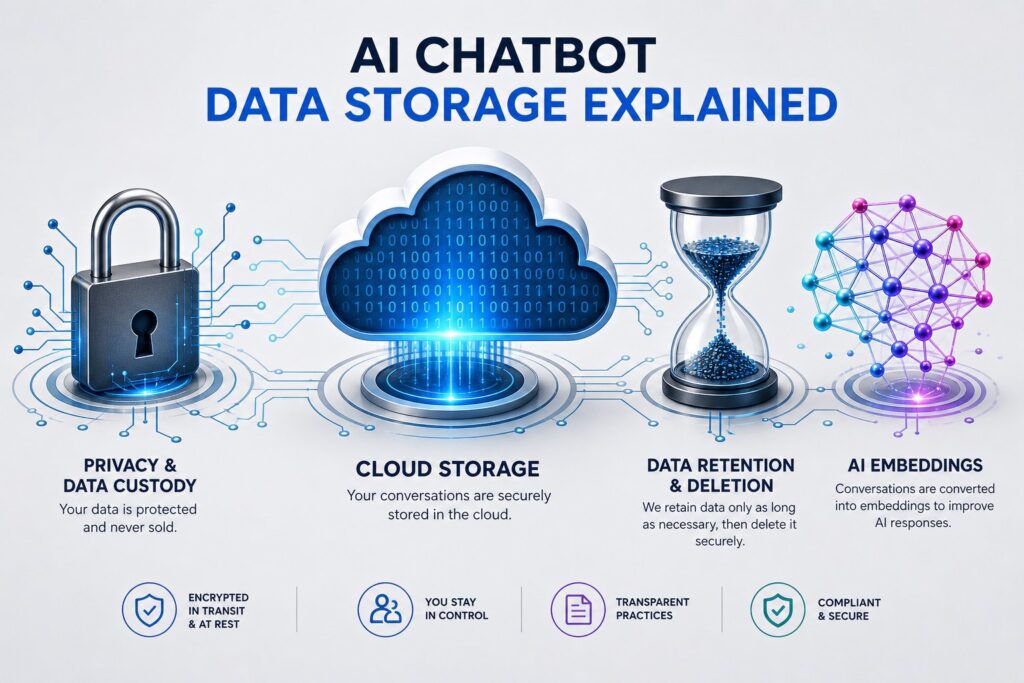
How Does LLM AI Store Your Data: Claude Conversation History, Data Retention, and What Are Embeddings
When you type a message to Claude, your words are converted into numerical arrays called embeddings, which capture semantic meaning rather than storing readable text. Anthropic retains conversation data according to its privacy policy, and deleting a chat removes your access but may not immediately erase server side records. Embeddings are mathematical representations, not compressed copies of your original words.
If you have ever wondered whether your Claude conversations are saved to your phone, whether deleting a chat actually removes your data, how long Anthropic keeps your history, or what on earth your words become before a language model can read them, this post answers all of it. Most explainers stop at the surface, telling you that conversations are “stored in the cloud” or that models use “vector representations” without explaining what those phrases mean in practice or what they mean for your privacy. This one goes deeper, and it starts by clearing up five misconceptions that nontechnical readers almost always walk away with after reading the shallow versions.
The first is that embeddings are compressed copies of your conversations. They are not. The second is that if a chatbot remembers something, it must have retrained on your data. It almost certainly has not. The third is that deleting a chat instantly removes your data from every system simultaneously. It does not. The fourth is that memory, chat history, vector storage, and model training are all the same thing. They are four completely distinct mechanisms. The fifth is that the AI is searching its own brain every time it answers you. What it is actually doing is quite different, and understanding it changes how you think about both the capability and the privacy implications of these systems.
1. The stack: five layers every reader needs before anything else makes sense
Before getting into where your data lives or what embeddings are, you need a mental model of the layers involved, because most of the confusion in this space comes from people conflating layers that are genuinely separate. Think of the system as a stack with five levels, each of which can store data, process data, or both.
The first layer is the raw conversation, which is exactly what it sounds like: the text of your messages and the model’s responses, stored as ordinary text in a database. The second layer is the embedding, which is a mathematical transformation of that text into a list of numbers that encodes meaning rather than words, and which enables a fundamentally different kind of search than keyword matching. The third layer is the vector database, which is a specialised storage system designed to hold those numerical representations and retrieve the ones most similar to a new query at speed. The fourth layer is retrieval, which is the process of searching that vector database to find relevant context before a response is generated. The fifth layer is generation, where the language model finally produces a response, often having been handed retrieved context from layer four to work with.
The modern pattern that powers AI memory in most production systems is sometimes called retrieval-augmented generation: search first, answer second. The model does not hold everything in its head. It searches for relevant fragments and reads them just before it speaks. That single insight dissolves most of the confusion people have about how AI memory works, so it is worth sitting with for a moment before moving on.
2. The biggest misunderstanding about AI memory
Most people imagine that when Claude or ChatGPT remembers something from a previous conversation, the model itself has been updated, that some learning has happened and the new information is now woven into the model’s weights the way a human might absorb a lesson. That picture is almost always wrong, and the gap between that intuition and the reality is large enough to matter.
In most deployed AI memory systems, the model has not been retrained on your conversation. What has happened instead is that your conversation was stored, possibly converted into embeddings and indexed in a vector database, and when you start a new conversation, a retrieval system searches that store for fragments relevant to what you are currently asking about. Those fragments are then injected into the prompt as context before the model generates a response. The model sees them as text at the top of its input, reads them as it would read anything else, and produces a response that appears to reflect memory of your previous interaction. The effect feels like memory because retrieval quality has improved dramatically over the last two years, but the mechanism is much closer to a well-organised filing system than to the way human memory works.
This distinction between memory, retrieval, and training is not a technicality. It has direct implications for your privacy, for what happens when you delete data, and for what it even means to say that an AI “knows” something about you. Memory in this context usually means a structured data store of facts derived from your conversations. Retrieval is the mechanism that finds relevant facts and injects them into context at the right moment. Training is a completely separate and vastly more expensive process that happens on dedicated infrastructure over weeks or months, not in response to your individual conversations. Conflating them leads to wildly incorrect assumptions in both directions, sometimes thinking the AI knows more about you than it does, and sometimes thinking your data is safer than it is.
3. Why the AI does not search every previous conversation every time
A natural follow-up question is whether the system is reading through all of your previous conversations every time you ask something. It is not, and understanding why helps clarify how the retrieval layer works in practice.
Imagine you have had 500 conversations with Claude over the past year. The combined text of those conversations might run to several hundred thousand words. A language model has a context window, a maximum amount of text it can hold in working memory at once, and that window cannot fit hundreds of thousands of words of previous conversations alongside your current question. Something has to be selective. That something is the retrieval layer, which uses embedding similarity to find the handful of previous conversations or memory fragments most relevant to what you are asking right now and injects only those into the prompt. The model sees perhaps a few paragraphs of retrieved context, not your entire history. The selectivity is what makes the system practical, and embeddings are what make the selectivity possible, because without a way to measure semantic similarity you would be back to keyword matching and the retrieval quality would be poor.
4. What embeddings are and why meaning-as-geometry works
A traditional database search works like a library catalogue: it finds documents that contain the exact words you searched for. If you search for “Aurora migration” it returns results containing those specific words and nothing else. A vector database works on a completely different principle, one closer to human intuition: it finds documents that are mathematically similar in meaning to your query, regardless of whether they share any words. Searching for “Aurora migration” in a vector database might return a document about “moving a relational workload from a managed AWS service to open source PostgreSQL” even though none of those words appeared in your query, because the meaning of the two phrases occupies nearby positions in the same mathematical space.
That shift from keyword matching to meaning matching is what makes modern AI memory and search systems possible, and the mechanism behind it is embeddings. An embedding is the process of converting a piece of text into a list of numbers, typically thousands of numbers long, that encodes where the meaning of that text sits in a learned map of concepts. The map is not designed by anyone. It emerges from training, from exposing a model to enormous quantities of text and letting the numerical representations of words and phrases drift toward each other when those words and phrases appear in similar contexts and drift apart when they do not.
The analogy that makes this stick is a city. Imagine every word or phrase is a building, and the city is arranged so that similar concepts are in the same neighbourhood. “Dog” and “puppy” are next door neighbours. “Dog” and “cat” are a few doors down on the same street. “Dog” and “democracy” are in completely different boroughs with no natural route between them. Now extend the city to 8,000 dimensions instead of two, with each dimension capturing some learned aspect of meaning, grammatical role, or typical context, and you have an embedding space. A word’s position in that space, described by its coordinates across all 8,000 dimensions, is its embedding vector. Similarity of meaning becomes a mathematical distance calculation, which means the model can find related concepts using arithmetic rather than needing a dictionary or an encyclopedia.
The famous demonstration of this is: take the vector for “king”, subtract the vector for “man”, and add the vector for “woman”, and you arrive very close to the vector for “queen.” The geometry of the space has encoded the relationship between royalty and gender so precisely that you can navigate between concepts by adding and subtracting their positions. Nobody designed that relationship into the system. It emerged because “king” and “queen” appeared in overlapping contexts across millions of training examples, and the embedding space organised itself to reflect that pattern.
5. How your question becomes an embedding, step by step
When you type “how do I fix a slow computer”, the process that turns those words into an embedding is mechanical and precise. The tokeniser splits the text into tokens, which are word fragments rather than whole words, producing something like “how”, “ do”, “ I”, “ fix”, “ a”, “ slow”, “ computer”. Each token has an integer ID in a vocabulary lookup table, so “computer” might be token number 7,439. That ID is used to look up a row in the embedding table, which is a large matrix with one row per token in the vocabulary and thousands of columns. Token 7,439 maps to a specific row of that matrix: a vector of perhaps 8,000 numbers encoding everything the model learned during training about where “computer” sits in the space of meaning. This lookup happens for every token in your message, so the entire query becomes a matrix of numerical vectors, one row per token, which is what enters the transformer network and what gets stored in the vector database if your message is being indexed for later retrieval.
6. Can someone reconstruct your original conversation from an embedding?
This is one of the most frequently asked questions about AI privacy and it deserves a careful answer rather than a reassuring one. The short version is that embeddings are not designed to be readable copies of your conversations and you cannot simply decode a vector back into the original text the way you might unzip a compressed file. The embedding process is a transformation that discards a great deal of surface information in favour of capturing semantic meaning, and there is no straightforward reversal.
The longer and more honest version is that “not designed for reconstruction” is not the same as “impossible to infer from.” Research into embedding inversion has shown that under certain conditions, aspects of the original text can be approximated from its embedding, particularly for short texts with limited possible content. This is an active area of security research rather than a solved problem. The practical risk for most users is low, because an attacker would need direct access to your stored embeddings, not just to the model, and because the reconstruction quality degrades substantially for longer and more complex text. But the “embeddings are irreversible therefore perfectly safe” framing that you sometimes see overstates the guarantee. Embeddings are not plain-text copies of your conversations, and they are not privacy shields with mathematical certainty. They sit somewhere between those two poles, and anyone making security decisions about what to share with AI systems should understand that.
7. Where your conversation data actually lives
With the conceptual stack in place, the storage question has a much more precise answer. Nothing from your Claude conversation is stored permanently on your device. The mobile app and the web interface are thin clients that render conversation history fetched from Anthropic’s servers and hold it in working memory while the session is active. Close the app, and the local copy is gone. This is why you cannot read your conversation history offline and why losing or replacing a device has no effect on your history at all. Your conversation history is tied to your account, not to any hardware.
When you are logged in, your conversation history lives in Anthropic’s cloud infrastructure and is accessible from any device where you authenticate. The history visible in the sidebar of claude.ai is a view over a server-side store associated with your account identifier. This is also why conversation history follows you seamlessly from phone to laptop to another laptop without any synchronisation step on your part.
The model weights themselves are not personalised to you. Claude does not build a private internal representation of who you are that updates over time between sessions. The weights are fixed between training runs and are identical for every user. What Anthropic does maintain separately is a memory system, which derives structured facts from your conversations and injects them as context at the start of future sessions. This is a distinct data store from your conversation logs, visible and editable in your account settings, and it is closer to a set of notes read aloud before a meeting than to anything the model has learned. If you use incognito mode in the Claude interface, neither conversation logs nor memory updates are saved, and the session is discarded entirely when you close it.
8. What actually happens when you delete a conversation
Deletion is not a single event. It is a sequence of events across separate systems, and understanding the sequence matters for anyone trying to manage their data seriously.
When you delete a conversation in the Claude interface, it is immediately removed from your view and from the conversation history store associated with your account. That part is instant. What is not instant is the removal from Anthropic’s backend logs, operational databases, and backup systems. Conversation data persists in backend logs for up to 30 days after deletion before being permanently purged, which means that for roughly a month after you delete something it still exists on Anthropic’s infrastructure even though it is no longer visible to you. If your conversation history has been used to generate memory entries, deleting the conversation does not automatically delete the derived memory. Those are stored separately and need to be managed separately through the memory settings in your account.
The training data question adds another layer. For consumer accounts that have opted in to model training, deleted conversations are excluded from future training runs, but conversations used in training runs that already completed before deletion are not retroactively removed from trained model weights, because that is not how model training works. The weights encode patterns from enormous datasets and there is no mechanism to surgically remove the influence of a single conversation from a trained model. This is not unique to Anthropic. It is a fundamental property of how neural network training works.
There is also a trust and safety carve-out that operates independently of your deletion and training preferences. Any conversation flagged by Anthropic’s classifiers as a potential policy violation can be retained for up to two years, and the classifier scores themselves can be kept for up to seven years as part of an abuse detection function. This applies regardless of whether you have opted out of training and regardless of whether you have deleted the conversation.
9. How long Claude keeps your data, and what the 2025 policy changes mean
The retention rules changed significantly in August 2025 when Anthropic updated its consumer terms, and the changes introduced a branching structure depending on your privacy settings that is worth understanding precisely.
For consumer accounts on Free, Pro, and Max plans, the default position is that your conversations are retained in backend logs for up to 30 days after deletion and then permanently purged, with nothing from those conversations used to train future models. If you opted in to model training, or if you missed the September 2025 deadline and were defaulted in by inaction, your conversations can be retained in de-identified form for up to five years and used to improve future versions of Claude. This setting is changeable at any time in Privacy Settings, and deleting individual conversations excludes them from future training runs even if you have opted in at the account level.
For enterprise API customers, commercial terms apply and the picture is cleaner. API conversations are excluded from model training regardless of any consumer-level settings, retention defaults to 30 days, and enterprises can negotiate a Zero Data Retention agreement under which inputs and outputs are not stored at all beyond the minimum required for abuse screening. The September 2025 consumer policy changes did not apply to commercial customers.
10. Why no one designed the embedding space, and why that matters
One closing point that matters for understanding the scale of what is possible here. Nobody decided what each dimension of an 8,000 dimensional embedding space should represent. Nobody drew the map, placed the buildings, or chose to put “dog” near “cat.” The embedding values were not designed. They were discovered. The model started training with random numbers assigned to every token in the vocabulary, and over billions of training examples those numbers were adjusted incrementally each time the model made a wrong prediction. Words that appeared frequently in similar contexts drifted toward each other in the space because that arrangement made next-token prediction more accurate, and words that almost never appeared in related contexts drifted apart for the same reason. The result is a space whose geometry reflects the deep statistical structure of language as it is actually used across an enormous and varied corpus of text, encoding relationships and distinctions far more nuanced than any team of humans could have specified by hand. “Broken heart” and “grief after relationship loss” ended up close together not because anyone put them there but because the sentences surrounding those phrases overlapped in consistent ways across millions of examples, and the geometry of the space reorganised itself to reflect that pattern. That self-organising property is what makes embedding-based retrieval work at the scale and quality that modern AI memory systems require.
Andrew Baker is Group CIO at Capitec Bank. He writes on technology, infrastructure, and AI at andrewbaker.ninja.